Erik Desmazieres’s “La Bibliothèque de Babel”. 1997.
We have been training language models (LMs) for years, but finding valuable resources about the data pipelines commonly used to build the datasets for training these models is paradoxically challenging. It may be because we often take it for granted that these datasets exist (or at least existed? As replicating them is becoming increasingly difficult). However, one must consider the numerous decisions involved in creating such pipelines, as it can significantly impact the final model’s quality, as seen recently in the struggle of models aiming to replicate LLaMA (LLaMA: Open and Efficient Foundation Language Models). It might be tempting to think that now, with large models that can scale well, data is becoming more critical than modeling, since model architectures are not radically changing much. However, data has always been critical.
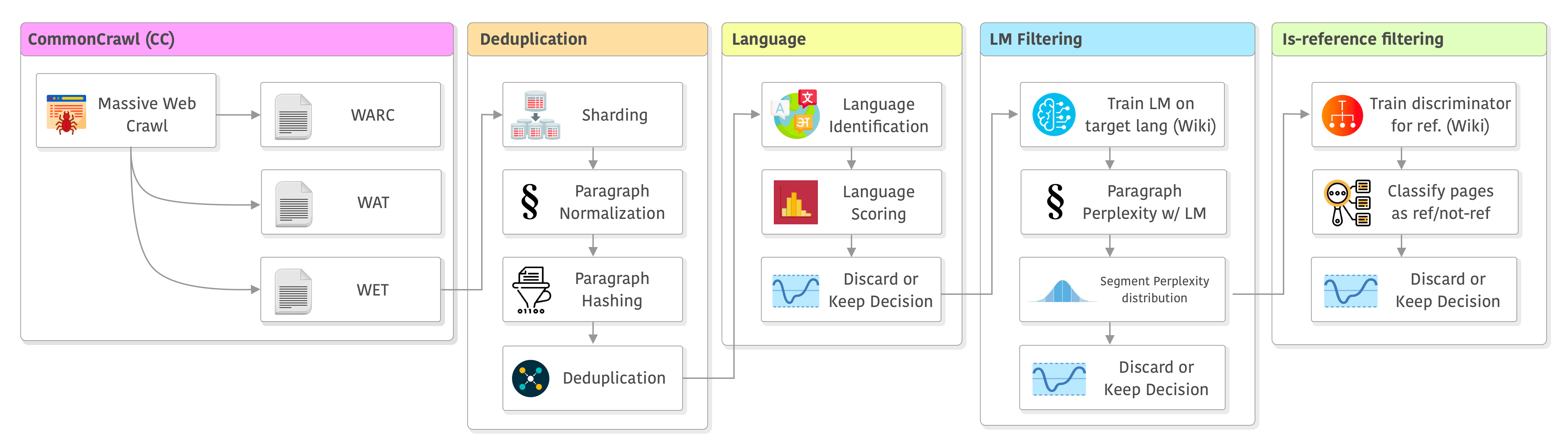
The entire pipeline of CCNet (plus some minor modifications made by LLaMA’s paper) can be seen below. It has the following stages: data source, deduplication, language, filtering, and the “is-reference” filtering which was added in LLaMA. I will go through each one of them in the sections below.
Visual overview of the CCNet pipeline with some modifications done in LLaMA. Click to enlarge.
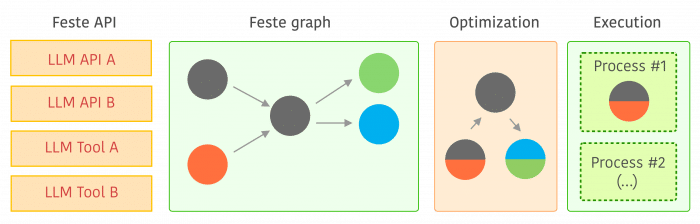
I just released Feste, a free and open-source framework with a permissive license that allows scalable composition of NLP tasks using a graph execution model that is optimized and executed by specialized schedulers. The main idea behind Feste is that it builds a graph of execution instead of executing tasks immediately, this graph allows Feste to optimize and parallelize it. One main example of optimization is when we have multiple calls to the same backend (e.g. same API), Feste automatically fuses these calls into a single one and therefore it batches the call to reduce latency and improve backend inference leverage of GPU vectorization. Feste also executes tasks that can be done in parallel in different processes, so the user doesn’t have to care about parallelization, especially when there are multiple frameworks using different concurrency strategies.
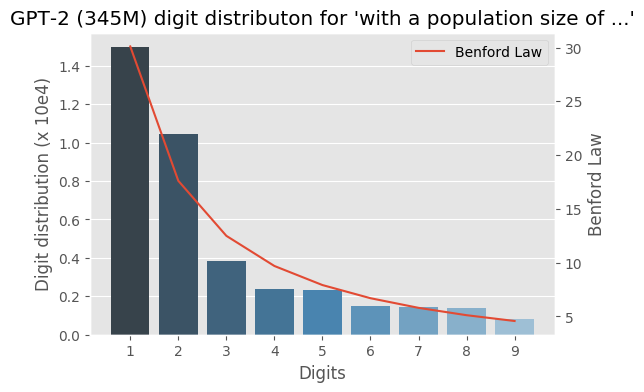
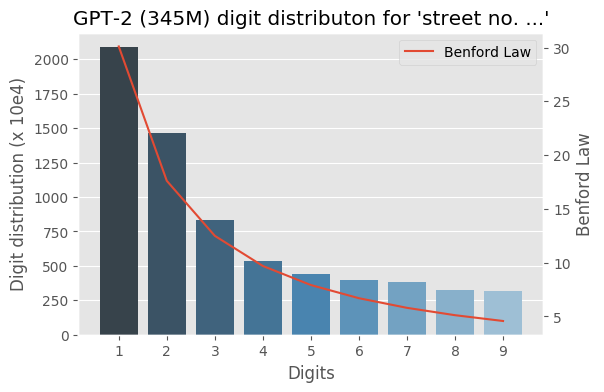
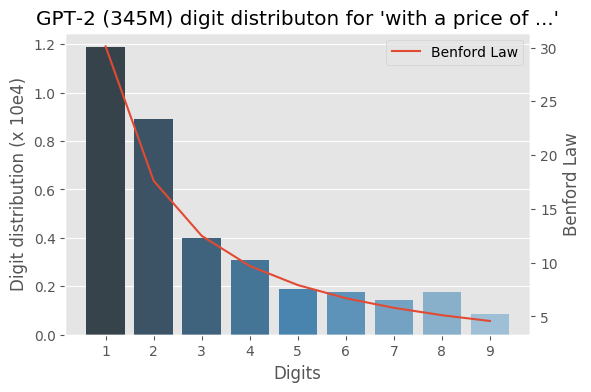
I wrote some months ago about how the Benford law emerges from language models, today I decided to evaluate the same method to check how the GPT-2 would behave with some sentences and it turns out that it seems that it is also capturing these power laws. You can find some plots with the examples below, the plots are showing the probability of the digit given a particular sentence such as “with a population size of”, showing the distribution of: $$P(\{1,2, \ldots, 9\} \vert \text{“with a population size of”})$$ for the GPT-2 medium model (345M):
I made an introductory talk on word embeddings in the past and this write-up is an extended version of the part about philosophical ideas behind word vectors. The aim of this article is to provide an introduction to Ludwig Wittgenstein’s main ideas on linguistics that are closely related to techniques that are distributional (I’ll talk what this means later) by design, such as word2vec [Mikolov et al., 2013], GloVe [Pennington et al., 2014], Skip-Thought Vectors [Kiros et al., 2015], among others.
One of the most interesting aspects of Wittgenstein is perhaps that fact that he had developed two very different philosophies during his life, and each of which had great influence. Something quite rare for someone who spent so much time working on these ideas and retreating even after the major influence they exerted, especially in the Vienna Circle. A true lesson of intellectual honesty, and in my opinion, one important legacy.
Wittgenstein was an avid reader of the Schopenhauer’s philosophy, and in the same way that Schopenhauer inherited his philosophy from Kant, especially regarding the division of what can be experimented (phenomena) or not (noumena), contrasting things as they appear for us from things as they are in themselves, Wittgenstein concluded that Schopenhauer philosophy was fundamentally right. He believed that in the noumena realm, we have no conceptual understanding and therefore we will never be able to say anything (without becoming nonsense), in contrast to the phenomena realm of our experience, where we can indeed talk about and try to understand. By adding secure foundations, such as logic, to the phenomenal world, he was able to reason about how the world is describable by language and thus mapping what are the limits of how and what can be expressed in language or in conceptual thought.
The first main theory of language from Wittgenstein, described in his Tractatus Logico-Philosophicus, is known as the “Picture theory of language” (aka Picture theory of meaning). This theory is based on an analogy with painting, where Wittgenstein realized that a painting is something very different than a natural landscape, however, a skilled painter can still represent the real landscape by placing patches or strokes corresponding to the natural landscape reality. Wittgenstein gave the name “logical form” to this set of relationships between the painting and the natural landscape. This logical form, the set of internal relationships common to both representations, is why the painter was able to represent reality because the logical form was the same in both representations (here I call both as “representations” to be coherent with Schopenhauer and Kant terms because the reality is also a representation for us, to distinguish between it and the thing-in-itself).
This theory was important, especially in our context (NLP), because Wittgenstein realized that the same thing happens with language. We are able to assemble words in sentences to match the same logical form of what we want to describe. The logical form was the core idea that made us able to talk about the world. However, later Wittgenstein realized that he had just picked a single task, out of the vast amount of tasks that language can perform and created a whole theory of meaning around it.
The fact is, language can do many other tasks besides representing (picturing) the reality. With language, as Wittgenstein noticed, we can give orders, and we can’t say that this is a picture of something. Soon as he realized these counter-examples, Wittgenstein abandoned the picture theory of language and adopted a much more powerful metaphor of a tool. And here we’re approaching the modern view of the meaning in language as well as the main foundational idea behind many modern Machine Learning techniques for word/sentence representations that works quite well. Once you realize that language works as a tool, if you want to understand the meaning of it, you just need to understand all the possible things you can do with it. And if you take for instance a word or concept in isolation, the meaning of it is the sum of all its uses, and this meaning is fluid and can have many different faces. This important thought can be summarized in the well-known quote below:
The meaning of a word is its use in the language.
(…)
One cannot guess how a word functions. One has to look at its use, and learn from that.
– Ludwig Wittgenstein, Philosophical Investigations
And indeed it makes complete sense because once you exhaust all the uses of a word, there is nothing left on it. Reality is also by far more fluid than usually thought, because:
Our language can be seen as an ancient city: a maze of little streets and squares, of old and new houses, and of houses with additions from various periods (…)
– Ludwig Wittgenstein, Philosophical Investigations
John R. Firth was a linguist also known for the popularization of this context-dependent nature of the meaning who also used Wittgenstein’s Philosophical Investigations as a recourse to emphasize the importance of the context in meaning, in which I quote below:
The placing of a text as a constituent in a context of situation contributes to the statement of meaning since situations are set up to recognize use. As Wittgenstein says, ‘the meaning of words lies in their use.’ (Phil. Investigations, 80, 109). The day-to-day practice of playing language games recognizes customs and rules. It follows that a text in such established usage may contain sentences such as ‘Don’t be such an ass !’, ‘You silly ass !’, ‘What an ass he is !’ In these examples, the word ass is in familiar and habitual company, commonly collocated with you silly-, he is a silly-, don’t be such an-. You shall know a word by the company it keeps ! One of the meanings of ass is its habitual collocation with such other words as those above quoted. Though Wittgenstein was dealing with another problem, he also recognizes the plain face-value, the physiognomy of words. They look at us ! ‘The sentence is composed of words and that is enough’.
– John R. Firth
This idea of learning the meaning of a word by the company it keeps is exactly what word2vec (and other count-based methods based on co-occurrence as well) is doing by means of data and learning on an unsupervised fashion with a supervised task that was by design built to predict context (or vice-versa, depending if you use skip-gram or cbow), which was also a source of inspiration for the Skip-Thought Vectors. Nowadays, this idea is also known as the “Distributional Hypothesis“, which is also being used on fields other than linguistics.
Now, it is quite amazing that if we look at the work by Neelakantan, et al., 2015, called “Efficient Non-parametric Estimation of Multiple Embeddings per Word in Vector Space“, where they mention about an important deficiency in word2vec in which each word type has only one vector representation, you’ll see that this has deep philosophical motivations if we relate it to the Wittgenstein and Firth ideas, because, as Wittgenstein noticed, the meaning of a word is unlikely to wear a single face and word2vec seems to be converging to an approximation of the average meaning of a word instead of capturing the polysemy inherent in language.
A concrete example of the multi-faceted nature of words can be seen in the example of the word “evidence”, where the meaning can be quite different to a historian, a lawyer and a physicist. The hearsay cannot count as evidence in a court while it is many times the only evidence that a historian has, whereas the hearsay doesn’t even arise in physics. Recent works such as ELMo [Peters, Matthew E. et al. 2018], which used different levels of features from a LSTM trained with a language model objective are also a very interesting direction with excellent results towards incorporating a context-dependent semantics into the word representations and breaking the tradition of shallow representations as seen in word2vec.
We’re in an exciting time where it is really amazing to see how many deep philosophical foundations are actually hidden in Machine Learning techniques. It is also very interesting that we’re learning a lot of linguistic lessons from Machine Learning experimentation, that we can see as important means for discovery that is forming an amazing virtuous circle. I think that we have never been self-conscious and concerned with language as in the past years.
Privacy-preserving computation or secure computation is a sub-field of cryptography where two (two-party, or 2PC) or multiple (multi-party, or MPC) parties can evaluate a function together without revealing information about the parties private input data to each other. The problem and the first solution to it were introduced in 1982 by an amazing breakthrough done by Andrew Yao on what later became known as the “Yao’s Millionaires’ problem“.
The Yao’s Millionaires Problem is where two millionaires, Alice and Bob, who are interested in knowing which of them is richer but without revealing to each other their actual wealth. In other words, what they want can be generalized as that: Alice and Bob want jointly compute a function securely, without knowing anything other than the result of the computation on the input data (that remains private to them).
To make the problem concrete, Alice has an amount A such as $10, and Bob has an amount B such as $ 50, and what they want to know is which one is larger, without Bob revealing the amount B to Alice or Alice revealing the amount A to Bob. It is also important to note that we also don’t want to trust on a third-party, otherwise the problem would just be a simple protocol of information exchange with the trusted party.
Formally what we want is to jointly evaluate the following function:
Such as the private values A and B are held private to the sole owner of it and where the result r will be known to just one or both of the parties.
It seems very counterintuitive that a problem like that could ever be solved, but for the surprise of many people, it is possible to solve it on some security requirements. Thanks to the recent developments in techniques such as FHE (Fully Homomorphic Encryption), Oblivious Transfer, Garbled Circuits, problems like that started to get practical for real-life usage and they are being nowadays being used by many companies in applications such as information exchange, secure location, advertisement, satellite orbit collision avoidance, etc.
I’m not going to enter into details of these techniques, but if you’re interested in the intuition behind the OT (Oblivious Transfer), you should definitely read the amazing explanation done by Craig Gidney here. There are also, of course, many different protocols for doing 2PC or MPC, where each one of them assumes some security requirements (semi-honest, malicious, etc), I’m not going to enter into the details to keep the post focused on the goal, but you should be aware of that.
The problem: sentence similarity
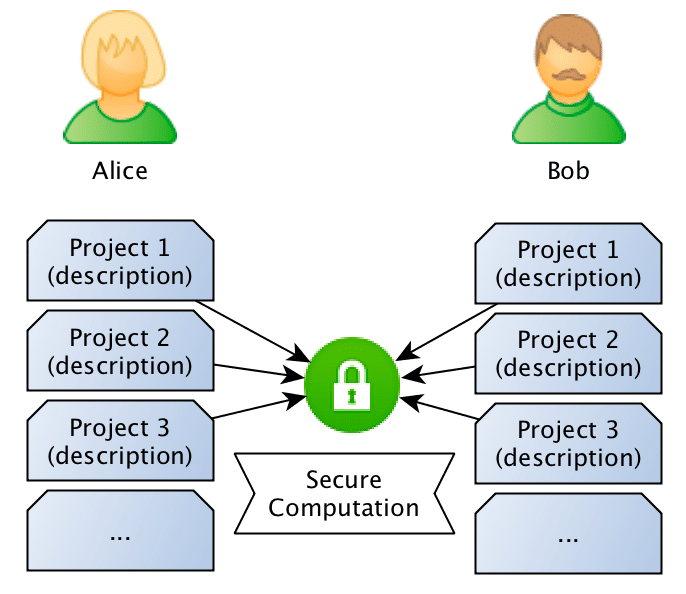
What we want to achieve is to use privacy-preserving computation to calculate the similarity between sentences without disclosing the content of the sentences. Just to give a concrete example: Bob owns a company and has the description of many different projects in sentences such as: “This project is about building a deep learning sentiment analysis framework that will be used for tweets“, and Alice who owns another competitor company, has also different projects described in similar sentences. What they want to do is to jointly compute the similarity between projects in order to find if they should be doing partnership on a project or not, however, and this is the important point: Bob doesn’t want Alice to know the project descriptions and neither Alice wants Bob to be aware of their projects, they want to know the closest match between the different projects they run, but without disclosing the project ideas (project descriptions).
Sentence Similarity Comparison
Now, how can we exchange information about the Bob and Alice’s project sentences without disclosing information about the project descriptions ?
One naive way to do that would be to just compute the hashes of the sentences and then compare only the hashes to check if they match. However, this would assume that the descriptions are exactly the same, and besides that, if the entropy of the sentences is small (like small sentences), someone with reasonable computation power can try to recover the sentence.
Another approach for this problem (this is the approach that we’ll be using), is to compare the sentences in the sentence embeddings space. We just need to create sentence embeddings using a Machine Learning model (we’ll use InferSent later) and then compare the embeddings of the sentences. However, this approach also raises another concern: what if Bob or Alice trains a Seq2Seq model that would go from the embeddings of the other party back to an approximate description of the project ?
It isn’t unreasonable to think that one can recover an approximate description of the sentence given their embeddings. That’s why we’ll use the two-party secure computation for computing the embeddings similarity, in a way that Bob and Alice will compute the similarity of the embeddings without revealing their embeddings, keeping their project ideas safe.
The entire flow is described in the image below, where Bob and Alice shares the same Machine Learning model, after that they use this model to go from sentences to embeddings, followed by a secure computation of the similarity in the embedding space.
Diagram overview of the entire process.
Generating sentence embeddings with InferSent
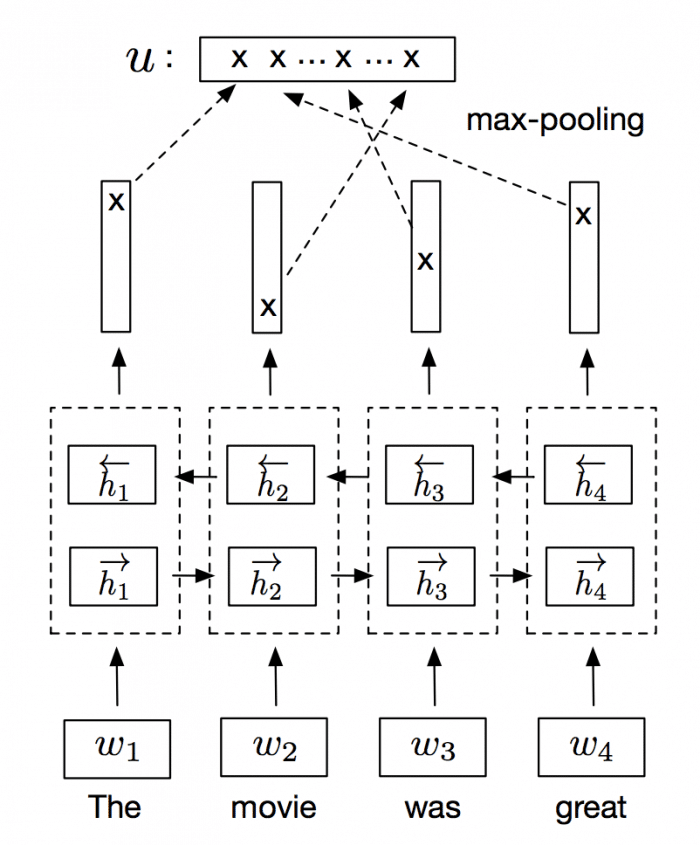
Bi-LSTM max-pooling network. Source: Supervised Learning of Universal Sentence Representations from Natural Language Inference Data. Alexis Conneau et al.
InferSent is an NLP technique for universal sentence representation developed by Facebook that uses supervised training to produce high transferable representations.
They used a Bi-directional LSTM with attention that consistently surpassed many unsupervised training methods such as the SkipThought vectors. They also provide a Pytorch implementation that we’ll use to generate sentence embeddings.
Note: even if you don’t have GPU, you can have reasonable performance doing embeddings for a few sentences.
The first step to generate the sentence embeddings is to download and load a pre-trained InferSent model:
import numpy as np
import torch
# Trained model from: https://github.com/facebookresearch/InferSent
GLOVE_EMBS = '../dataset/GloVe/glove.840B.300d.txt'
INFERSENT_MODEL = 'infersent.allnli.pickle'
# Load trained InferSent model
model = torch.load(INFERSENT_MODEL,
map_location=lambda storage, loc: storage)
model.set_glove_path(GLOVE_EMBS)
model.build_vocab_k_words(K=100000)
As you can see, if we have two unit vectors (vectors with norm 1), the two terms in the equation denominator will be 1 and we will be able to remove the entire denominator of the equation, leaving only:
So, if we normalize our vectors to have a unit norm (that’s why the vectors are wearing hats in the equation above), we can make the computation of the cosine similarity become just a simple dot product. That will help us a lot in computing the similarity distance later when we’ll use a framework to do the secure computation of this dot product.
So, the next step is to define a function that will take some sentence text and forward it to the model to generate the embeddings and then normalize them to unit vectors:
# This function will forward the text into the model and
# get the embeddings. After that, it will normalize it
# to a unit vector.
def encode(model, text):
embedding = model.encode([text])[0]
embedding /= np.linalg.norm(embedding)
return embedding
As you can see, this function is pretty simple, it feeds the text into the model, and then it will divide the embedding vector by the embedding norm.
Now, for practical reasons, I’ll be using integer computation later for computing the similarity, however, the embeddings generated by InferSent are of course real values. For that reason, you’ll see in the code below that we create another function to scale the float values and remove the radix point andconverting them to integers. There is also another important issue, the framework that we’ll be using later for secure computation doesn’t allow signed integers, so we also need to clip the embeddings values between 0.0 and 1.0. This will of course cause some approximation errors, however, we can still get very good approximations after clipping and scaling with limited precision (I’m using 14 bits for scaling to avoid overflow issues later during dot product computations):
# This function will scale the embedding in order to
# remove the radix point.
def scale(embedding):
SCALE = 1 << 14
scale_embedding = np.clip(embedding, 0.0, 1.0) * SCALE
return scale_embedding.astype(np.int32)
You can use floating-point in your secure computations and there are a lot of frameworks that support them, however, it is more tricky to do that, and for that reason, I used integer arithmetic to simplify the tutorial. The function above is just a hack to make it simple. It’s easy to see that we can recover this embedding later without too much loss of precision.
Now we just need to create some sentence samples that we’ll be using:
# The list of Alice sentences
alice_sentences = [
'my cat loves to walk over my keyboard',
'I like to pet my cat',
]
# The list of Bob sentences
bob_sentences = [
'the cat is always walking over my keyboard',
]
And convert them to embeddings:
# Alice sentences
alice_sentence1 = encode(model, alice_sentences[0])
alice_sentence2 = encode(model, alice_sentences[1])
# Bob sentences
bob_sentence1 = encode(model, bob_sentences[0])
Since we have now the sentences and every sentence is also normalized, we can compute cosine similarity just by doing a dot product between the vectors:
As we can see, the first sentence of Bob is most similar (~0.87) with Alice first sentence than to the Alice second sentence (~0.62).
Since we have now the embeddings, we just need to convert them to scaled integers:
# Scale the Alice sentence embeddings
alice_sentence1_scaled = scale(alice_sentence1)
alice_sentence2_scaled = scale(alice_sentence2)
# Scale the Bob sentence embeddings
bob_sentence1_scaled = scale(bob_sentence1)
# This is the unit vector embedding for the sentence
>>> alice_sentence1
array([ 0.01698913, -0.0014404 , 0.0010993 , ..., 0.00252409,
0.00828147, 0.00466533], dtype=float32)
# This is the scaled vector as integers
>>> alice_sentence1_scaled
array([278, 0, 18, ..., 41, 135, 76], dtype=int32)
Now with these embeddings as scaled integers, we can proceed to the second part, where we’ll be doing the secure computation between two parties.
Two-party secure computation
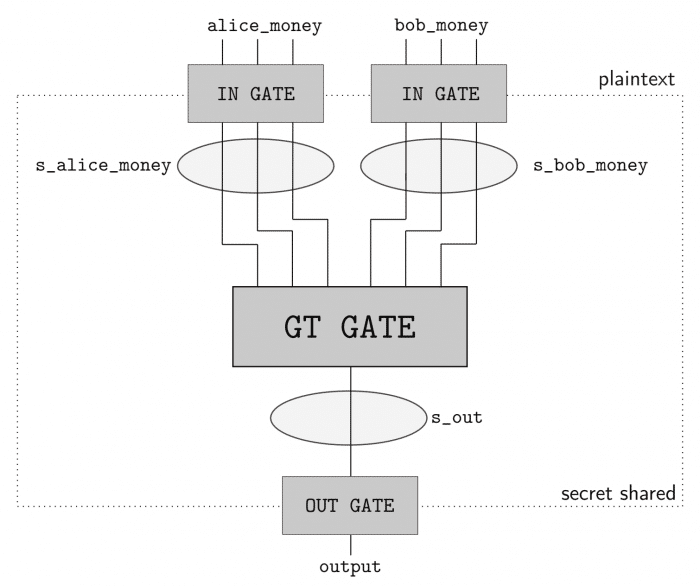
In order to perform secure computation between the two parties (Alice and Bob), we’ll use the ABY framework. ABY implements many difference secure computation schemes and allows you to describe your computation as a circuit like pictured in the image below, where the Yao’s Millionaire’s problem is described:
Yao’s Millionaires problem. Taken from ABY documentation (https://github.com/encryptogroup/ABY).
As you can see, we have two inputs entering in one GT GATE (greater than gate) and then a output. This circuit has a bit length of 3 for each input and will compute if the Alice input is greater than (GT GATE) the Bob input. The computing parties then secret share their private data and then can use arithmetic sharing, boolean sharing, or Yao sharing to securely evaluate these gates.
ABY is really easy to use because you can just describe your inputs, shares, gates and it will do the rest for you such as creating the socket communication channel, exchanging data when needed, etc. However, the implementation is entirely written in C++ and I’m not aware of any Python bindings for it (a great contribution opportunity).
Fortunately, there is an implemented example for ABY that can do dot product calculation for us, the example is here. I won’t replicate the example here, but the only part that we have to change is to read the embedding vectors that we created before instead of generating random vectors and increasing the bit length to 32-bits.
After that, we just need to execute the application on two different machines (or by emulating locally like below):
# This will execute the server part, the -r 0 specifies the role (server)
# and the -n 4096 defines the dimension of the vector (InferSent generates
# 4096-dimensional embeddings).
~# ./innerproduct -r 0 -n 4096
# And the same on another process (or another machine, however for another
# machine execution you'll have to obviously specify the IP).
~# ./innerproduct -r 1 -n 4096
And we get the following results:
Inner Product of alice_sentence1 and bob_sentence1 = 226691917
Inner Product of alice_sentence2 and bob_sentence1 = 171746521
Even in the integer representation, you can see that the inner product of the Alice’s first sentence and the Bob sentence is higher, meaning that the similarity is also higher. But let’s now convert this value back to float:
>>> SCALE = 1 << 14
# This is the dot product we should get
>>> np.dot(alice_sentence1, bob_sentence1)
0.8798542
# This is the inner product we got on secure computation
>>> 226691917 / SCALE**2.0
0.8444931
# This is the dot product we should get
>>> np.dot(alice_sentence2, bob_sentence1)
0.6297632
# This is the inner product we got on secure computation
>>> 171746521 / SCALE**2.0
0.6398056
As you can see, we got very good approximations, even in presence of low-precision math and unsigned integer requirements. Of course that in real-life you won’t have the two values and vectors, because they’re supposed to be hidden, but the changes to accommodate that are trivial, you just need to adjust ABY code to load only the vector of the party that it is executing it and using the correct IP addresses/port of the both parties.
This website uses cookies to improve your experience. We'll assume you're ok with this, but you can opt-out if you wish. Cookie settingsACCEPT
Privacy & Cookies Policy
Privacy Overview
This website uses cookies to improve your experience while you navigate through the website. Out of these cookies, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may have an effect on your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.

 One of the most interesting aspects of Wittgenstein is perhaps that fact that he had developed two very different philosophies during his life, and each of which had great influence. Something quite rare for someone who spent so much time working on these ideas and retreating even after the major influence they exerted, especially in the Vienna Circle. A true lesson of intellectual honesty, and in my opinion, one important legacy.
One of the most interesting aspects of Wittgenstein is perhaps that fact that he had developed two very different philosophies during his life, and each of which had great influence. Something quite rare for someone who spent so much time working on these ideas and retreating even after the major influence they exerted, especially in the Vienna Circle. A true lesson of intellectual honesty, and in my opinion, one important legacy.
 John R. Firth
John R. Firth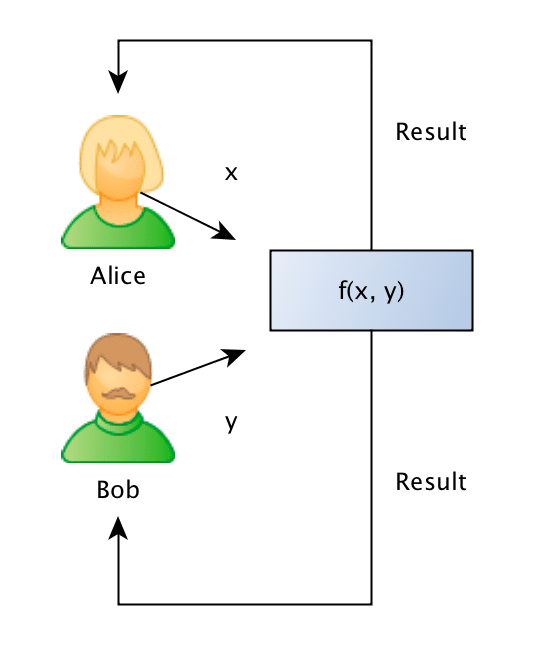
")
 What they want to do is to jointly compute the similarity between projects in order to find if they should be doing partnership on a project or not, however, and this is the important point: Bob doesn’t want Alice to know the project descriptions and neither Alice wants Bob to be aware of their projects, they want to know the closest match between the different projects they run, but without disclosing the project ideas (project descriptions).
What they want to do is to jointly compute the similarity between projects in order to find if they should be doing partnership on a project or not, however, and this is the important point: Bob doesn’t want Alice to know the project descriptions and neither Alice wants Bob to be aware of their projects, they want to know the closest match between the different projects they run, but without disclosing the project ideas (project descriptions).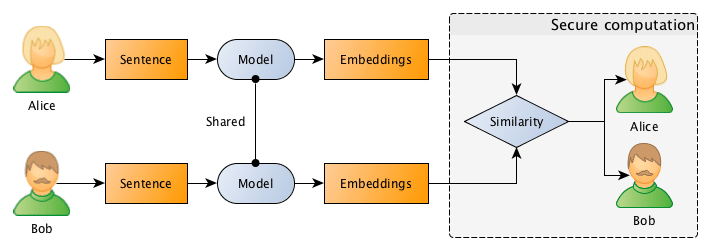
 = \frac {\pmb x \cdot \pmb y}{||\pmb x|| \cdot ||\pmb y||}")
 =\hat{x} \cdot\hat{y}")