Large language model data pipelines and Common Crawl (WARC/WAT/WET)

We have been training language models (LMs) for years, but finding valuable resources about the data pipelines commonly used to build the datasets for training these models is paradoxically challenging. It may be because we often take it for granted that these datasets exist (or at least existed? As replicating them is becoming increasingly difficult). However, one must consider the numerous decisions involved in creating such pipelines, as it can significantly impact the final model’s quality, as seen recently in the struggle of models aiming to replicate LLaMA (LLaMA: Open and Efficient Foundation Language Models). It might be tempting to think that now, with large models that can scale well, data is becoming more critical than modeling, since model architectures are not radically changing much. However, data has always been critical.
This article provides a short introduction to the pipeline used to create the data to train LLaMA, but it allows for many variations and I will add details about other similar pipelines when relevant, such as RefinedWeb (The RefinedWeb Dataset for Falcon LLM: Outperforming Curated Corpora with Web Data, and Web Data Only) and The Pile (The Pile: An 800GB Dataset of Diverse Text for Language Modeling). This article is mainly based on the pipeline described in CCNet (CCNet: Extracting High Quality Monolingual Datasets from Web Crawl Data) and LLaMA’s paper, both from Meta. CCNet was developed focusing on the data source that is often the largest one, but also the most challenging in terms of quality: Common Crawl.
The big picture
The entire pipeline of CCNet (plus some minor modifications made by LLaMA’s paper) can be seen below. It has the following stages: data source, deduplication, language, filtering, and the “is-reference” filtering which was added in LLaMA. I will go through each one of them in the sections below.
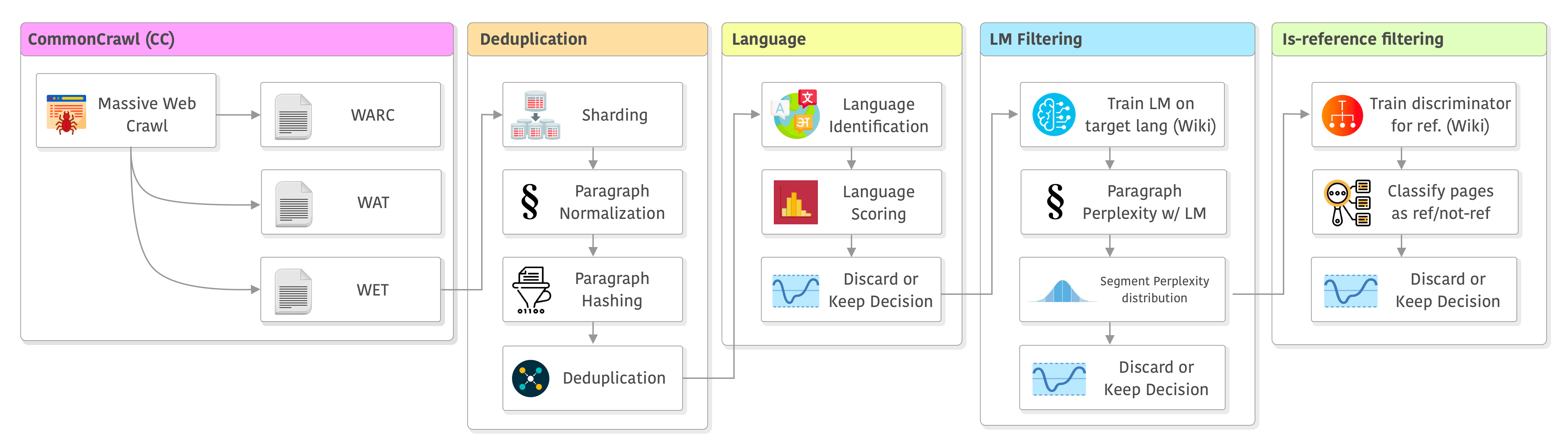
Let’s dive into it !
Common Crawl
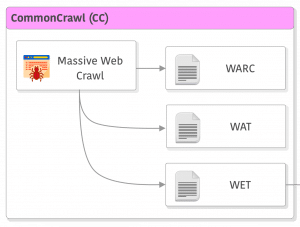
Common Crawl (or CC) data is the data coming from a non-profit organization of the same name that does massive crawling of websites and releases this archive under permissive terms. This is by no means an easy feat, consider the tasks of filtering spam, deciding which URLs to crawl, crawling massive amounts of data from different servers, data formats, etc. That’s why you should consider donating if you use it.
Common Crawl provides different archival formats that you can use and this format evolved over time. Nowadays they are available in 3 main different formats (besides the index): WARC, WAT, and WET.
WARC/WAT/WET formats
WARC: the WARC format is the largest one as it is the least processed version of the crawl process, it is the raw data and has a very clever format that records the HTTP response headers, so you can even get information about the server being used on each host. This format is seldom used for NLP as it is really huge and has data that is not used for LLMs training. However, this is the primary data format of CC so it is very rich and might be useful for multimodal datasets, that’s why I think that WARC and WAT (described below) might start to see more uses in the next years.
WAT and WET: these are secondary data sources of CC as they are processed data. These two are the ones that are often used for training LMs and here is where different pipelines start to diverge as well. These formats contain different types of records with the WAT having more metadata than WET and also HTML tags content and links. WET is mainly only a textual format.
If you want to see real examples of WARC/WAT/WET, take a look at this link as I omitted examples here to keep things short, but they are very interesting formats that are worth a look if you want to use them or understand how to load and parse them.
Now, CCNet (CCNet: Extracting High Quality Monolingual Datasets from Web Crawl Data) uses the WET format which is purely textual, and that is where we will focus, however, there are some other pipelines that use WAT with the argument that to extract high-quality textual data you have to go to WAT instead of WET (bypassing the CommonCrawl processing to extract text). One example of a pipeline that doesn’t use the WET files is The Pile (The Pile: An 800GB Dataset of Diverse Text for Language Modeling), where they use jusText. They mentioned that they can extract higher-quality text than using WET files.
You probably realized that we just started with CC and there are already multiple options to extract data from it. Another recent pipeline called RefinedWeb (used in Falcon) also uses WARC directly and skip the CC pipeline for text extraction (the one which generates the WET files). RefinedWeb, however, uses trafilatura instead of jusText for text extraction.
URL Filtering
Although it is not mentioned in CCNet, many pipelines do URL filtering using public available blocklists of adult/violent/malware/etc websites. In RefinedWeb for example, they filter URLs using a blocklist of 4.6M domains and also use a word-based filtering of the URL. You can be very creative here and aggregate multiple blocklists from different sources.
Deduplication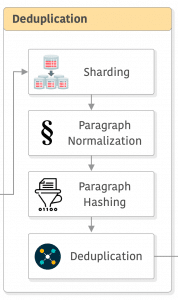
Let’s now talk about deduplication, which can be a controversial matter. In Deduplicating Training Data Makes Language Models Better you can have an idea of what they found. There is, however, Pythia (Pythia: A Suite for Analyzing Large Language Models Across Training and Scaling) that said that “… deduplication of our training data has no clear benefit on language modeling performance.” [emphasis added]. Therefore I think it is still an open debate, but given excellent results from LLaMA, I wouldn’t leave deduplication aside for any new model, but we will probably see more works about it in the near future.
Let’s discuss now how deduplication works on CCNet. CC snapshots are big, if we look at the size of WET files for March/April 2023, WET is 8.7 TiB and WAT is 21.1 TiB (both compressed already!). The first thing that CCNet does is to break these WET snapshots into 5GB shards that are saved in JSON where each entry corresponds to a crawled web page.

The next step after sharding is paragraph normalization, as deduplication happens at the paragraph level. They normalize each paragraph by lower-casing it, replacing numbers with a placeholder, and removing all Unicode punctuation (you can also replace them) and accent marks. Next, they compute the SHA1 of each paragraph and use the first 64 bits to deduplicate them. After that, there is the option to do deduplication by comparing among all shards or a fixed number of shards, more details in their paper if you are interested in this comparison.
It is interesting to note that on the RefinedWeb dataset, they seem to be much more aggressive by employing fuzzy deduplication and using “strict settings” that led to the removal rates “far higher than other datasets have reported” (as a baseline, CCNet reported that duplicated data accounted for 70% of the text). This can certainly have a significant impact on dataset diversity.
Another important aspect of deduplication is described in CCNet paper: this step removes a lot of boilerplate (e.g. navigation menus, cookie warnings, and contact information). It also removes English content from pages in other languages and makes language identification which we will discuss next, more robust.
Here is an overview of the process:
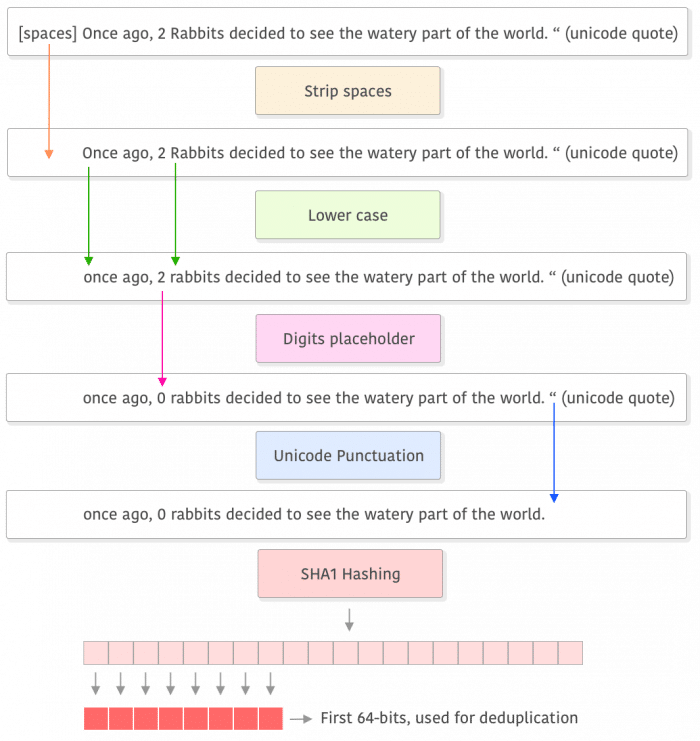
As you can see, it starts by stripping spaces, then lower cases it and replaces the digits with a placeholder (e.g. zero). After that it removes (or replaces) Unicode punctuation, performs a SHA1 hashing, and uses the first 8 bytes for deduplication comparisons (paragraph level). Do not confuse the deduplication process with training data, this is done only to compute the final hash and deduplicate data, not to use this data to train the model.
Now, on RefinedWeb, they followed what was done in Gopher as well which is to remove repetitions before filtering for deduplication by removing any document with excessive line, paragraph, or n-gram repetitions. After that, they used a deduplication pipeline using MinHash (On the resemblance and containment of documents) which they found to be very effective at removing SEO templates (placeholder SEO text repeated across websites, etc). They also did exact deduplication, but since CC is enormous, they did something similar to what was mentioned as an alternative in CCNet, where it is first sharded and deduplication happens at individual shard level.
Language
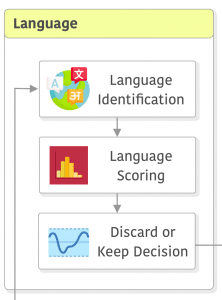 Let’s take a look now at language identification, scoring, and filtering. In CCNet they employed fastText (Bag of Tricks for Efficient Text Classification), which was trained with data from Wikipedia, Tatoeba, and SETimes. fastText supports 176 languages and reports a score for each one of them.
Let’s take a look now at language identification, scoring, and filtering. In CCNet they employed fastText (Bag of Tricks for Efficient Text Classification), which was trained with data from Wikipedia, Tatoeba, and SETimes. fastText supports 176 languages and reports a score for each one of them.
In CCNet, if the score for the most probable language is not higher than 0.5 (50%), they discard the web page, otherwise, the language is classified as being of the most probable language identified.
Note that although the LLaMA dataset filtered non-English data from the CC dataset, it was trained with other datasets that had other languages (e.g. Wikipedia). In my experience, LLaMA is impressively good at other languages as well (e.g. Portuguese).
RefinedWeb pipeline, just like CCNet, also employed fastText to identify languages. One important distinction here is that the RefinedWeb pipeline uses a different threshold of 0.65 instead of 0.5 and they have switched the order of deduplication and language identification, they do language identification before the deduplication, as opposed to CCNet which does the reverse.
LM Filtering
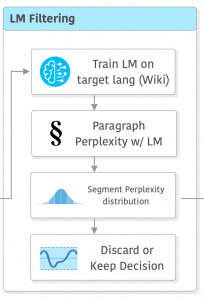 At this point, we have deduplicated data, and language was identified and filtered. It doesn’t mean, however, that the quality is good. That’s the reason why CCNet does another filtering step: they use the perplexity from a language model trained on the target domain language, as they found this score to be a relatively good proxy for quality. They train a 5-gram Kneser-Ney model on the Wikipedia of the same language as the target domain and then use these models to compute per-paragraph perplexity.
At this point, we have deduplicated data, and language was identified and filtered. It doesn’t mean, however, that the quality is good. That’s the reason why CCNet does another filtering step: they use the perplexity from a language model trained on the target domain language, as they found this score to be a relatively good proxy for quality. They train a 5-gram Kneser-Ney model on the Wikipedia of the same language as the target domain and then use these models to compute per-paragraph perplexity.
With the perplexities in hand, you need to find a threshold. What CCNet paper describes is that they computed 3 parts of equal size (head, middle, tail) from the distribution of perplexities of each language (as different languages showed very different perplexity distributions), however, there is an important excerpt from the paper that I quote below:
(…) Some documents despite being valid text ends up in the tail because they have a vocabulary very different from Wikipedia. This includes blog comments with spokenlike text, or very specialized forums with specific jargon. We decided to not remove content based on the LM score because we think that some of it could be useful for specific applications. (…)
This means that it really depends on your application, as you might be ending up removing important data by blind thresholding just using an LM trained on Wikipedia. In RefineWeb, they avoided using LM for filtering and relied only on simple rules and heuristics. They used a pipeline very similar to the one used in Gopher, where outliers are filtered “... in terms of overall length, symbol-to-word ratio, and other criteria ensuring the document is actual natural language“, they remark that this needs to be done per language as well, the usual issue with using heuristics too tied to the language characteristics.
“Is reference” filtering
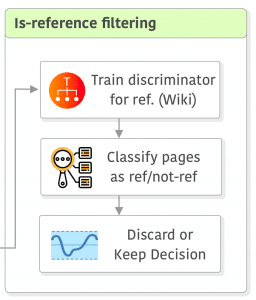 This section is not present in CCNet but it was used as an extra step in the LLaMA dataset so I decided to add it here as well. This step is also not very well described in LLaMA’s paper, but it seems that a simple linear classifier was trained (not sure with which features) to classify pages used as references in Wikipedia v.s. randomly sampled pages, then pages classified as non-reference were discarded.
This section is not present in CCNet but it was used as an extra step in the LLaMA dataset so I decided to add it here as well. This step is also not very well described in LLaMA’s paper, but it seems that a simple linear classifier was trained (not sure with which features) to classify pages used as references in Wikipedia v.s. randomly sampled pages, then pages classified as non-reference were discarded.
I think that this step might look simple at first hand, but it can have a significant impact on dataset quality depending on the threshold used. It seems to me that for LLaMA’s dataset, the LM filtering was more conservative to avoid removing relevant data and then they added this extra step to deal with remaining quality issues, but this is me hypothesizing.
Addendum: RefinedWeb diagram
RefinedWeb paper has a very nice Sankey diagram of their pipeline:
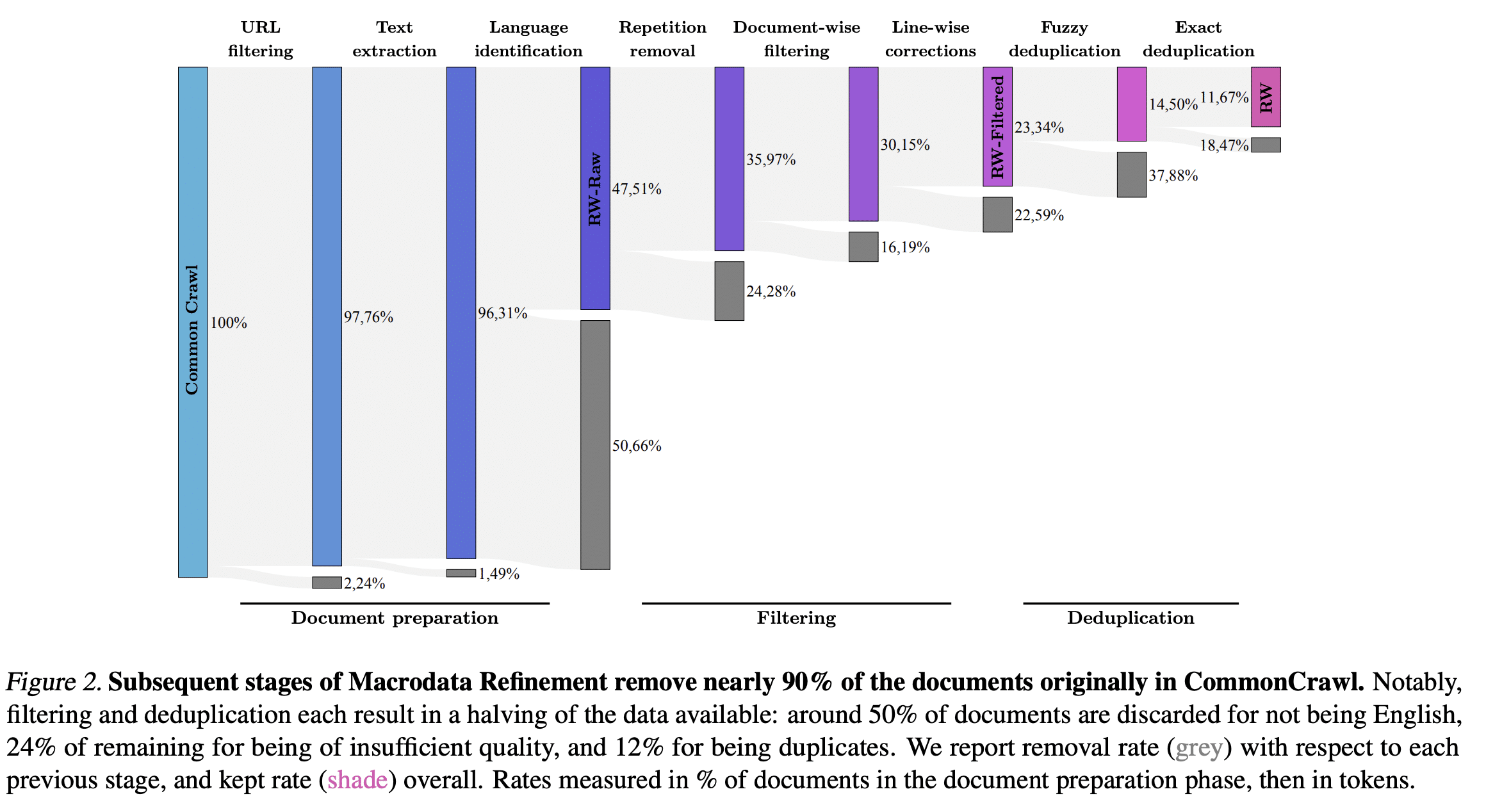
This is a very informative figure that tells us how much of the data was discarded. I was personally impressed by the amount of data removed during the repetition removal step.
Closing remarks

I hope you enjoyed this article, the main goal was to give a brief overview of the steps and decisions you need to take before being able to train a large language model (LLM). There are obviously many other important aspects, such as proportions of different datasets (mixing), tokenization, etc. Given that CC dataset is usually the largest dataset in LLM training, I decided to focus on the pipelines that directly deal with this particular set before tokenization.
Many design decisions on data pre-processing pipelines are made with performance in mind, as we are dealing with large chunks of data from CC dataset. It seems to me that you can find a better balance by investing a little more of the computing budget on the data side, especially when you consider the cost of LLMs training. It is, however, very difficult to anticipate what would be the impact of different decisions taken in the data pipeline on LLMs after training, that’s why small experiments, manual data inspection, and exploratory data analysis are paramount to get an understanding of what is going on.
In summary, every company has the dataset it deserves. It is a long-term investment that requires substantial experimentation, engineering effort, attention to detail, and good intuition to make bets under uncertainty. But it is an investment that pays off in the long run.
– Christian S. Perone
Changelog
6 June 2023: updated with more information made available by RefinedWeb paper.
3 June 2023: first version published.

Hey, this is a very nice article. I’ve been wondering how the data is gathered to train LLMs and this blog shares a nice intuition on the same. thanks for Sharing.
This is a great article, thanks for the hard work!
Thank you Meng !
very insightful share!
One of the finest articles I have ever read! Great work. Like to see more coming on similar fields.
I love to connect to have a small chat.