So, my request to enter on the free and private beta season of the new HP Cloud Services was gently accepted by the HP Cloud team, and today I finally got some time to play with the OpenStack API at HP Cloud. I’ll start with the first impressions I had with the service:
The user interface of the management is very user-friendly, the design is much like of the Twitter Bootstrap, see the screenshot below of the “Compute” page from the “Manage” section:

As you can see, they have a set of 4 Ubuntu images and a CentOS, I think that since they are still in the beta period, soon we’ll have more default images to use.
Here is a screenshot of the instance size set:

Since they are using OpenStack, I really think that they should have imported the vocabulary of the OpenStack into the user interface, and instead of calling it “Size”, it would be more sensible to use “Flavour“.
The user interface still doesn’t have many features, something that I would really like to have is a “Stop” or something like that for the instances, only the “Terminate” function is present on the Manage interface, but those are details that they should be still working on since they’re only in beta.
Another important info to cite is that the access to the instances are done through SSH using a generated RSA key that they provide to you.
Let’s dig into the OpenStack API now.
OpenStack API
To access the OpenStack API you’ll need the credentials for the authentication, HP Cloud services provide these keys on the Manage interface for each zone/service you have, see the screenshot below (with keys anonymized of course):
 Now, OpenStack authentication could be done in different schemes, the scheme that I know that HP supports is the token authentication. I know that there is a lot of clients already supporting the OpenStack API (some have no documentation, some have weird API design, etc.), but the aim of this post is to show how easy would be to create a simple interface to access the OpenStack API using Python and Requests (HTTP for Humans !).
Now, OpenStack authentication could be done in different schemes, the scheme that I know that HP supports is the token authentication. I know that there is a lot of clients already supporting the OpenStack API (some have no documentation, some have weird API design, etc.), but the aim of this post is to show how easy would be to create a simple interface to access the OpenStack API using Python and Requests (HTTP for Humans !).
Let’s start defining our authentication scheme by sub-classing Requests AuthBase:
[enlighter lang=”python” ]
class OpenStackAuth(AuthBase):
def __init__(self, auth_user, auth_key):
self.auth_key = auth_key
self.auth_user = auth_user
def __call__(self, r):
r.headers[‘X-Auth-User’] = self.auth_user
r.headers[‘X-Auth-Key’] = self.auth_key
return r
[/enlighter]
As you can see, we’re defining the X-Auth-User and the X-Auth-Key in the header of the request with the parameters. These parameters are respectively your Account ID and Access Key we cited earlier. Now, all you have to do is to make the request itself using the authentication scheme, which is pretty easy using Requests:
[enlighter lang=”python”]
ENDPOINT_URL = ‘https://az-1.region-a.geo-1.compute.hpcloudsvc.com/v1.1/’
ACCESS_KEY = ‘Your Access Key’
ACCOUNT_ID = ‘Your Account ID’
response = requests.get(ENDPOINT_URL, auth=OpenStackAuth(ACCOUNT_ID, ACCESS_KEY))
[/enlighter]
And that is it, you’re done with the authentication mechanism using just a few lines of code, and this is how the request is going to be sent to the HP Cloud service server:

This request is sent to the HP Cloud Endpoint URL (https://az-1.region-a.geo-1.compute.hpcloudsvc.com/v1.1/). Let’s see now how the server answered this authentication request:

You can show this authentication response using Requests by printing the header attribute of the request Response object. You can see that the server answered our request with two important header items: X-Server-Management-URL and the X-Auth-Token. The management URL is now our new endpoint, is the URL we should use to do further requests to the HP Cloud services and the X-Auth-Token is the authentication Token that the server generated based on our credentials, these tokens are usually valid for 24 hours, although I haven’t tested it.
What we need to do now is to sub-class the Requests AuthBase class again but this time defining only the authentication token that we need to use on each new request we’re going to make to the management URL:
[enlighter lang=”python”]
class OpenStackAuthToken(AuthBase):
def __init__(self, request):
self.auth_token = request.headers[‘x-auth-token’]
def __call__(self, r):
r.headers[‘X-Auth-Token’] = self.auth_token
return r
[/enlighter]
Note that the OpenStackAuthToken is receiving now a response request as parameter, copying the X-Auth-Token and setting it on the request.
Let’s consume a service from the OpenStack API v.1.1, I’m going to call the List Servers API function, parse the results using JSON and then show the results on the screen:
[enlighter lang=”python”]
# Get the management URL from the response header
mgmt_url = response.headers[‘x-server-management-url’]
# Create a new request to the management URL using the /servers path
# and the OpenStackAuthToken scheme we created
r_server = requests.get(mgmt_url + ‘/servers’, auth=OpenStackAuthToken(response))
# Parse the response and show it to the screen
json_parse = json.loads(r_server.text)
print json.dumps(json_parse, indent=4)
[/enlighter]
And this is what we get in response to this request:
[enlighter]
{
“servers”: [
{
“id”: 22378,
“uuid”: “e2964d51-fe98-48f3-9428-f3083aa0318e”,
“links”: [
{
“href”: “https://az-1.region-a.geo-1.compute.hpcloudsvc.com/v1.1/20817201684751/servers/22378”,
“rel”: “self”
},
{
“href”: “https://az-1.region-a.geo-1.compute.hpcloudsvc.com/20817201684751/servers/22378”,
“rel”: “bookmark”
}
],
“name”: “Server 22378”
},
{
“id”: 11921,
“uuid”: “312ff473-3d5d-433e-b7ee-e46e4efa0e5e”,
“links”: [
{
“href”: “https://az-1.region-a.geo-1.compute.hpcloudsvc.com/v1.1/20817201684751/servers/11921”,
“rel”: “self”
},
{
“href”: “https://az-1.region-a.geo-1.compute.hpcloudsvc.com/20817201684751/servers/11921”,
“rel”: “bookmark”
}
],
“name”: “Server 11921”
}
]
}
[/enlighter]
And that is it, now you know how to use Requests and Python to consume OpenStack API. If you wish to read more information about the API and how does it works, you can read the documentation here.
– Christian S. Perone










") which is actually the term count of the term
which is actually the term count of the term  in the document
in the document  . The use of this simple term frequency could lead us to problems like keyword spamming, which is when we have a repeated term in a document with the purpose of improving its ranking on an IR (Information Retrieval) system or even create a bias towards long documents, making them look more important than they are just because of the high frequency of the term in the document.
. The use of this simple term frequency could lead us to problems like keyword spamming, which is when we have a repeated term in a document with the purpose of improving its ranking on an IR (Information Retrieval) system or even create a bias towards long documents, making them look more important than they are just because of the high frequency of the term in the document. that we have calculated in the first part of this tutorial. The document
that we have calculated in the first part of this tutorial. The document  from the first part of this tutorial had this textual representation:
from the first part of this tutorial had this textual representation:")
 . The definition of the unit vector
. The definition of the unit vector  is:
is:
 is the norm (magnitude, length) of the vector
is the norm (magnitude, length) of the vector  space (don’t worry, I’m going to explain it all).
space (don’t worry, I’m going to explain it all).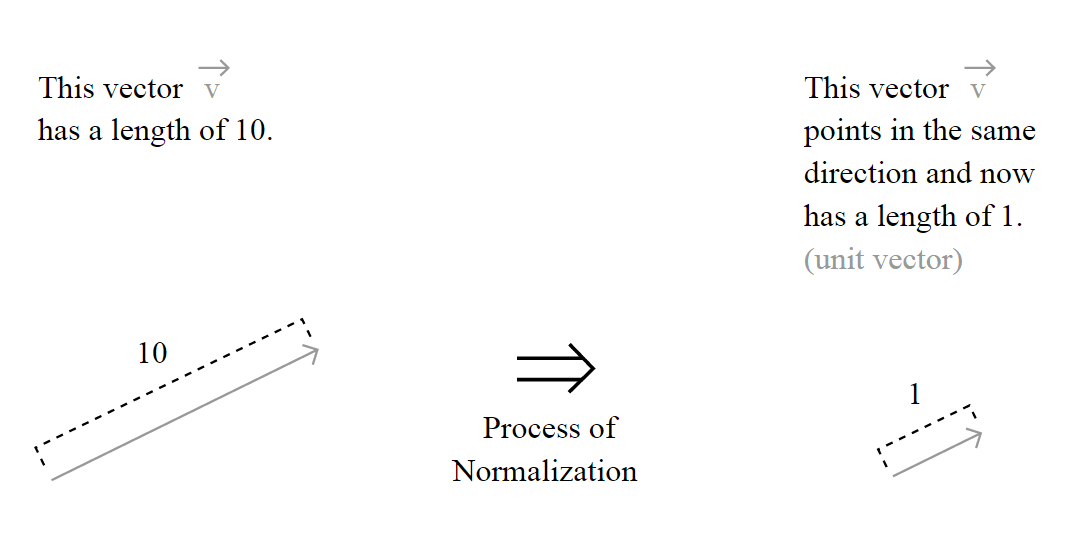
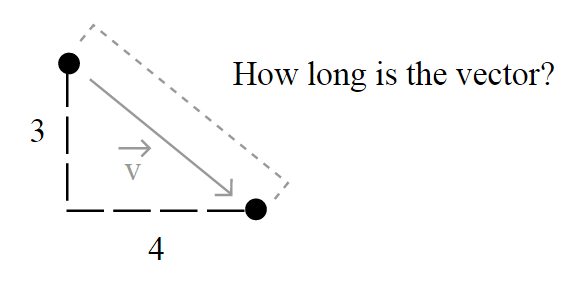
") is calculated using the
is calculated using the 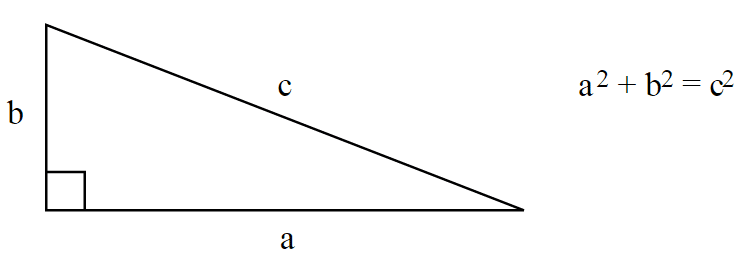

 together with the norm notation, like in
together with the norm notation, like in  . That’s because it could be generalized as:
. That’s because it could be generalized as:^\frac{1}{p}")
^\frac{1}{p}")
 , the most common norm used to measure the length of a vector, typically called “magnitude”; actually, when you have an unqualified length measure (without the
, the most common norm used to measure the length of a vector, typically called “magnitude”; actually, when you have an unqualified length measure (without the  , defined as:
, defined as:")

 , and is the unique shortest path.
, and is the unique shortest path. . To do that, we’ll simple plug it into the definition of the unit vector to evaluate it:
. To do that, we’ll simple plug it into the definition of the unit vector to evaluate it:}{\sqrt{0^2 + 2^2 + 1^2 + 0^2}} \\ \\ \hat{v_{d_4}} = \frac{(0,2,1,0)}{\sqrt{5}} \\ \\ \small \hat{v_{d_4}} = (0.0, 0.89442719, 0.4472136, 0.0)")
 .
. where
where  is the number of documents in your corpus, and in our case as
is the number of documents in your corpus, and in our case as  and
and  . The cardinality of our document space is defined by
. The cardinality of our document space is defined by  and
and  , since we have only 2 two documents for training and testing, but they obviously don’t need to have the same cardinality.
, since we have only 2 two documents for training and testing, but they obviously don’t need to have the same cardinality. = \log{\frac{\left|D\right|}{1+\left|\{d : t \in d\}\right|}}")
 is the number of documents where the term
is the number of documents where the term  \neq 0") , we’re only adding 1 into the formula to avoid zero-division.
, we’re only adding 1 into the formula to avoid zero-division. = \mathrm{tf}(t, d) \times \mathrm{idf}(t)")

") ,
, ") ,
, ") ,
, ") :
: = \log{\frac{\left|D\right|}{1+\left|\{d : t_1 \in d\}\right|}} = \log{\frac{2}{1}} = 0.69314718")
 = \log{\frac{\left|D\right|}{1+\left|\{d : t_2 \in d\}\right|}} = \log{\frac{2}{3}} = -0.40546511")
 = \log{\frac{\left|D\right|}{1+\left|\{d : t_3 \in d\}\right|}} = \log{\frac{2}{3}} = -0.40546511")
 = \log{\frac{\left|D\right|}{1+\left|\{d : t_4 \in d\}\right|}} = \log{\frac{2}{2}} = 0.0")
")
 ) and the vector representing the idf for each feature of our matrix (
) and the vector representing the idf for each feature of our matrix ( ), we can calculate our tf-idf weights. What we have to do is a simple multiplication of each column of the matrix
), we can calculate our tf-idf weights. What we have to do is a simple multiplication of each column of the matrix  with both the vertical and horizontal dimensions equal to the vector
with both the vertical and horizontal dimensions equal to the vector 

 will be different than the result of the
will be different than the result of the  , and this is why the
, and this is why the  & \mathrm{tf}(t_2, d_1) & \mathrm{tf}(t_3, d_1) & \mathrm{tf}(t_4, d_1)\\ \mathrm{tf}(t_1, d_2) & \mathrm{tf}(t_2, d_2) & \mathrm{tf}(t_3, d_2) & \mathrm{tf}(t_4, d_2) \end{bmatrix} \times \begin{bmatrix} \mathrm{idf}(t_1) & 0 & 0 & 0\\ 0 & \mathrm{idf}(t_2) & 0 & 0\\ 0 & 0 & \mathrm{idf}(t_3) & 0\\ 0 & 0 & 0 & \mathrm{idf}(t_4) \end{bmatrix} \\ = \begin{bmatrix} \mathrm{tf}(t_1, d_1) \times \mathrm{idf}(t_1) & \mathrm{tf}(t_2, d_1) \times \mathrm{idf}(t_2) & \mathrm{tf}(t_3, d_1) \times \mathrm{idf}(t_3) & \mathrm{tf}(t_4, d_1) \times \mathrm{idf}(t_4)\\ \mathrm{tf}(t_1, d_2) \times \mathrm{idf}(t_1) & \mathrm{tf}(t_2, d_2) \times \mathrm{idf}(t_2) & \mathrm{tf}(t_3, d_2) \times \mathrm{idf}(t_3) & \mathrm{tf}(t_4, d_2) \times \mathrm{idf}(t_4) \end{bmatrix}")

 matrix. Please note that this normalization is “row-wise” because we’re going to handle each row of the matrix as a separated vector to be normalized, and not the matrix as a whole:
matrix. Please note that this normalization is “row-wise” because we’re going to handle each row of the matrix as a separated vector to be normalized, and not the matrix as a whole:

 and
and  from the document set, we’ll have the following index vocabulary denoted as
from the document set, we’ll have the following index vocabulary denoted as ") where the
where the  = \begin{cases} 1, & \mbox{if } t\mbox{ is \"blue\"} \\ 2, & \mbox{if } t\mbox{ is \"sun\"} \\ 3, & \mbox{if } t\mbox{ is \"bright\"} \\ 4, & \mbox{if } t\mbox{ is \"sky\"} \\ \end{cases}")
 or
or  = \sum\limits_{x\in d} \mathrm{fr}(x, t)")
") is a simple function defined as:
is a simple function defined as: = \begin{cases} 1, & \mbox{if } x = t \\ 0, & \mbox{otherwise} \\ \end{cases}")
") returns is how many times is the term
returns is how many times is the term  = 2") since we have only two occurrences of the term “sun” in the document
since we have only two occurrences of the term “sun” in the document , \mathrm{tf}(t_2,d_n), \mathrm{tf}(t_3,d_n), \ldots, \mathrm{tf}(t_n,d_n))")
") represents the frequency-term of the term 1 or
represents the frequency-term of the term 1 or  (which is our “blue” term of the vocabulary) in the document
(which is our “blue” term of the vocabulary) in the document  .
. and
and  are represented as vectors:
are represented as vectors:, \mathrm{tf}(t_2,d_3), \mathrm{tf}(t_3,d_3), \ldots, \mathrm{tf}(t_n,d_3)) \\ \vec{v_{d_4}} = (\mathrm{tf}(t_1,d_4), \mathrm{tf}(t_2,d_4), \mathrm{tf}(t_3,d_4), \ldots, \mathrm{tf}(t_n,d_4))")
 \\ \vec{v_{d_4}} = (0, 2, 1, 0)")
 shows that we have, in order, 0 occurrences of the term “blue”, 1 occurrence of the term “sun”, and so on. In the
shows that we have, in order, 0 occurrences of the term “blue”, 1 occurrence of the term “sun”, and so on. In the  shape, where
shape, where  is the cardinality of the document space, or how many documents we have and the
is the cardinality of the document space, or how many documents we have and the  is the number of features, in our case represented by the vocabulary size. An example of the matrix representation of the vectors described above is:
is the number of features, in our case represented by the vocabulary size. An example of the matrix representation of the vectors described above is:
") (except because it is zero-indexed).
(except because it is zero-indexed). we cited earlier in this post, which represents the two document vectors
we cited earlier in this post, which represents the two document vectors 
