Concentration inequalities, or probability bounds, are very important tools for the analysis of Machine Learning algorithms or randomized algorithms. In statistical learning theory, we often want to show that random variables, given some assumptions, are close to its expectation with high probability. This article provides an overview of the most basic inequalities in the analysis of these concentration measures.
Markov’s Inequality
The Markov’s inequality is one of the most basic bounds and it assumes almost nothing about the random variable. The assumptions that Markov’s inequality makes is that the random variable \(X\) is non-negative \(X > 0\) and has a finite expectation \(\mathbb{E}\left[X\right] < \infty\). The Markov’s inequality is given by:
$$\underbrace{P(X \geq \alpha)}_{\text{Probability of being greater than constant } \alpha} \leq \underbrace{\frac{\mathbb{E}\left[X\right]}{\alpha}}_{\text{Bounded above by expectation over constant } \alpha}$$
What this means is that the probability that the random variable \(X\) will be bounded by the expectation of \(X\) divided by the constant \(\alpha\). What is remarkable about this bound, is that it holds for any distribution with positive values and it doesn’t depend on any feature of the probability distribution, it only requires some weak assumptions and its first moment, the expectation.
Example: A grocery store sells an average of 40 beers per day (it’s summer !). What is the probability that it will sell 80 or more beers tomorrow ?
The Markov’s inequality doesn’t depend on any property of the random variable probability distribution, so it’s obvious that there are better bounds to use if information about the probability distribution is available.
Chebyshev’s Inequality
When we have information about the underlying distribution of a random variable, we can take advantage of properties of this distribution to know more about the concentration of this variable. Let’s take for example a normal distribution with mean \(\mu = 0\) and unit standard deviation \(\sigma = 1\) given by the probability density function (PDF) below:
$$ f(x) = \frac{1}{\sqrt{2\pi}}e^{-x^2/2} $$
Integrating from -1 to 1: \(\int_{-1}^{1} \frac{1}{\sqrt{2\pi}}e^{-x^2/2}\), we know that 68% of the data is within \(1\sigma\) (one standard deviation) from the mean \(\mu\) and 95% is within \(2\sigma\) from the mean. However, when it’s not possible to assume normality, any other amount of data can be concentrated within \(1\sigma\) or \(2\sigma\).
Chebyshev’s inequality provides a way to get a bound on the concentration for any distribution, without assuming any underlying property except a finite mean and variance. Chebyshev’s also holds for any random variable, not only for non-negative variables as in Markov’s inequality.
The Chebyshev’s inequality is given by the following relation:
For the concrete case of \(k = 2\), the Chebyshev’s tells us that at least 75% of the data is concentrated within 2 standard deviations of the mean. And this holds for any distribution.
Now, when we compare this result for \( k = 2 \) with the 95% concentration of the normal distribution for \(2\sigma\), we can see how conservative is the Chebyshev’s bound. However, one must not forget that this holds for any distribution and not only for a normally distributed random variable, and all that Chebyshev’s needs, is the first and second moments of the data. Something important to note is that in absence of more information about the random variable, this cannot be improved.
Chebyshev’s Inequality and the Weak Law of Large Numbers
Chebyshev’s inequality can also be used to prove the weak law of large numbers, which says that the sample mean converges in probability towards the true mean.
That can be done as follows:
Consider a sequence of i.i.d. (independent and identically distributed) random variables \(X_1, X_2, X_3, \ldots\) with mean \(\mu\) and variance \(\sigma^2\);
The sample mean is \(M_n = \frac{X_1 + \ldots + X_n}{n}\) and the true mean is \(\mu\);
For the expectation of the sample mean we have: $$\mathbb{E}\left[M_n\right] = \frac{\mathbb{E}\left[X_1\right] + \ldots +\mathbb{E}\left[X_n\right]}{n} = \frac{n\mu}{n} = \mu$$
For the variance of the sample we have: $$Var\left[M_n\right] = \frac{Var\left[X_1\right] + \ldots +Var\left[X_n\right]}{n^2} = \frac{n\sigma^2}{n^2} = \frac{\sigma^2}{n}$$
By the application of the Chebyshev’s inequality we have: $$ P(\mid M_n – \mu \mid \geq \epsilon) \leq \frac{\sigma^2}{n\epsilon^2}$$ for any (fixed) \(\epsilon > 0\), as \(n\) increases, the right side of the inequality goes to zero. Intuitively, this means that for a large \(n\) the concentration of the distribution of \(M_n\) will be around \(\mu\).
Improving on Markov’s and Chebyshev’s with Chernoff Bounds
Before getting into the Chernoff bound, let’s understand the motivation behind it and how one can improve on Chebyshev’s bound. To understand it, we first need to understand the difference between a pairwise independence and mutual independence. For the pairwise independence, we have the following for A, B, and C:
$$
P(A \cap B) = P(A)P(B) \\
P(A \cap C) = P(A)P(C) \\
P(B \cap C) = P(B)P(C)
$$
Which means that any pair (any two events) are independent, but not necessarily that:
$$
P(A \cap B\cap C) = P(A)P(B)P(C)
$$
which is called “mutual independence” and it is a stronger independence. By definition, the mutual independence assumes the pairwise independence but the opposite isn’t always true. And this is the case where we can improve on Chebyshev’s bound, as it is not possible without doing these further assumptions (stronger assumptions leads to stronger bounds).
We’ll talk about the Chernoff bounds in the second part of this tutorial !
I made an introductory talk on word embeddings in the past and this write-up is an extended version of the part about philosophical ideas behind word vectors. The aim of this article is to provide an introduction to Ludwig Wittgenstein’s main ideas on linguistics that are closely related to techniques that are distributional (I’ll talk what this means later) by design, such as word2vec [Mikolov et al., 2013], GloVe [Pennington et al., 2014], Skip-Thought Vectors [Kiros et al., 2015], among others.
One of the most interesting aspects of Wittgenstein is perhaps that fact that he had developed two very different philosophies during his life, and each of which had great influence. Something quite rare for someone who spent so much time working on these ideas and retreating even after the major influence they exerted, especially in the Vienna Circle. A true lesson of intellectual honesty, and in my opinion, one important legacy.
Wittgenstein was an avid reader of the Schopenhauer’s philosophy, and in the same way that Schopenhauer inherited his philosophy from Kant, especially regarding the division of what can be experimented (phenomena) or not (noumena), contrasting things as they appear for us from things as they are in themselves, Wittgenstein concluded that Schopenhauer philosophy was fundamentally right. He believed that in the noumena realm, we have no conceptual understanding and therefore we will never be able to say anything (without becoming nonsense), in contrast to the phenomena realm of our experience, where we can indeed talk about and try to understand. By adding secure foundations, such as logic, to the phenomenal world, he was able to reason about how the world is describable by language and thus mapping what are the limits of how and what can be expressed in language or in conceptual thought.
The first main theory of language from Wittgenstein, described in his Tractatus Logico-Philosophicus, is known as the “Picture theory of language” (aka Picture theory of meaning). This theory is based on an analogy with painting, where Wittgenstein realized that a painting is something very different than a natural landscape, however, a skilled painter can still represent the real landscape by placing patches or strokes corresponding to the natural landscape reality. Wittgenstein gave the name “logical form” to this set of relationships between the painting and the natural landscape. This logical form, the set of internal relationships common to both representations, is why the painter was able to represent reality because the logical form was the same in both representations (here I call both as “representations” to be coherent with Schopenhauer and Kant terms because the reality is also a representation for us, to distinguish between it and the thing-in-itself).
This theory was important, especially in our context (NLP), because Wittgenstein realized that the same thing happens with language. We are able to assemble words in sentences to match the same logical form of what we want to describe. The logical form was the core idea that made us able to talk about the world. However, later Wittgenstein realized that he had just picked a single task, out of the vast amount of tasks that language can perform and created a whole theory of meaning around it.
The fact is, language can do many other tasks besides representing (picturing) the reality. With language, as Wittgenstein noticed, we can give orders, and we can’t say that this is a picture of something. Soon as he realized these counter-examples, Wittgenstein abandoned the picture theory of language and adopted a much more powerful metaphor of a tool. And here we’re approaching the modern view of the meaning in language as well as the main foundational idea behind many modern Machine Learning techniques for word/sentence representations that works quite well. Once you realize that language works as a tool, if you want to understand the meaning of it, you just need to understand all the possible things you can do with it. And if you take for instance a word or concept in isolation, the meaning of it is the sum of all its uses, and this meaning is fluid and can have many different faces. This important thought can be summarized in the well-known quote below:
The meaning of a word is its use in the language.
(…)
One cannot guess how a word functions. One has to look at its use, and learn from that.
– Ludwig Wittgenstein, Philosophical Investigations
And indeed it makes complete sense because once you exhaust all the uses of a word, there is nothing left on it. Reality is also by far more fluid than usually thought, because:
Our language can be seen as an ancient city: a maze of little streets and squares, of old and new houses, and of houses with additions from various periods (…)
– Ludwig Wittgenstein, Philosophical Investigations
John R. Firth was a linguist also known for the popularization of this context-dependent nature of the meaning who also used Wittgenstein’s Philosophical Investigations as a recourse to emphasize the importance of the context in meaning, in which I quote below:
The placing of a text as a constituent in a context of situation contributes to the statement of meaning since situations are set up to recognize use. As Wittgenstein says, ‘the meaning of words lies in their use.’ (Phil. Investigations, 80, 109). The day-to-day practice of playing language games recognizes customs and rules. It follows that a text in such established usage may contain sentences such as ‘Don’t be such an ass !’, ‘You silly ass !’, ‘What an ass he is !’ In these examples, the word ass is in familiar and habitual company, commonly collocated with you silly-, he is a silly-, don’t be such an-. You shall know a word by the company it keeps ! One of the meanings of ass is its habitual collocation with such other words as those above quoted. Though Wittgenstein was dealing with another problem, he also recognizes the plain face-value, the physiognomy of words. They look at us ! ‘The sentence is composed of words and that is enough’.
– John R. Firth
This idea of learning the meaning of a word by the company it keeps is exactly what word2vec (and other count-based methods based on co-occurrence as well) is doing by means of data and learning on an unsupervised fashion with a supervised task that was by design built to predict context (or vice-versa, depending if you use skip-gram or cbow), which was also a source of inspiration for the Skip-Thought Vectors. Nowadays, this idea is also known as the “Distributional Hypothesis“, which is also being used on fields other than linguistics.
Now, it is quite amazing that if we look at the work by Neelakantan, et al., 2015, called “Efficient Non-parametric Estimation of Multiple Embeddings per Word in Vector Space“, where they mention about an important deficiency in word2vec in which each word type has only one vector representation, you’ll see that this has deep philosophical motivations if we relate it to the Wittgenstein and Firth ideas, because, as Wittgenstein noticed, the meaning of a word is unlikely to wear a single face and word2vec seems to be converging to an approximation of the average meaning of a word instead of capturing the polysemy inherent in language.
A concrete example of the multi-faceted nature of words can be seen in the example of the word “evidence”, where the meaning can be quite different to a historian, a lawyer and a physicist. The hearsay cannot count as evidence in a court while it is many times the only evidence that a historian has, whereas the hearsay doesn’t even arise in physics. Recent works such as ELMo [Peters, Matthew E. et al. 2018], which used different levels of features from a LSTM trained with a language model objective are also a very interesting direction with excellent results towards incorporating a context-dependent semantics into the word representations and breaking the tradition of shallow representations as seen in word2vec.
We’re in an exciting time where it is really amazing to see how many deep philosophical foundations are actually hidden in Machine Learning techniques. It is also very interesting that we’re learning a lot of linguistic lessons from Machine Learning experimentation, that we can see as important means for discovery that is forming an amazing virtuous circle. I think that we have never been self-conscious and concerned with language as in the past years.
This post is a tour around the PyTorch codebase, it is meant to be a guide for the architectural design of PyTorch and its internals. My main goal is to provide something useful for those who are interested in understanding what happens beyond the user-facing API and show something new beyond what was already covered in other tutorials.
Note: PyTorch build system uses code generation extensively so I won’t repeat here what was already described by others. If you’re interested in understanding how this works, please read the following tutorials:
As you probably know, you can extend Python using C and C++ and develop what is called as “extension”. All the PyTorch heavy work is implemented in C/C++ instead of pure-Python. To define a new Python object type in C/C++, you define a structure like this one example below (which is the base for the autograd Variable class):
As you can see, there is a macro at the beginning of the definition, called PyObject_HEAD, this macro’s goal is the standardization of Python objects and will expand to another structure that contains a pointer to a type object (which defines initialization methods, allocators, etc) and also a field with a reference counter.
There are two extra macros in the Python API called Py_INCREF() and Py_DECREF(), which are used to increment and decrement the reference counter of Python objects. Multiple entities can borrow or own a reference to other objects (the reference counter is increased), and only when this reference counter reaches zero (when all references get destroyed), Python will automatically delete the memory from that object using its garbage collector.
You can read more about Python C/++ extensions here.
Funny fact: it is very common in many applications to use small integer numbers as indexing, counters, etc. For efficiency, the official CPython interpreter caches the integers from -5 up to 256. For that reason, the statement a = 200; b = 200; a is b will be True, while the statement a = 300; b = 300; a is b will be False.
Zero-copy PyTorch Tensor to Numpy and vice-versa
PyTorch has its own Tensor representation, which decouples PyTorch internal representation from external representations. However, as it is very common, especially when data is loaded from a variety of sources, to have Numpy arrays everywhere, therefore we really need to make conversions between Numpy and PyTorch tensors. For that reason, PyTorch provides two methods called from_numpy() and numpy(), that converts a Numpy array to a PyTorch array and vice-versa, respectively. If we look the code that is being called to convert a Numpy array into a PyTorch tensor, we can get more insights on the PyTorch’s internal representation:
at::Tensor tensor_from_numpy(PyObject* obj) {
if (!PyArray_Check(obj)) {
throw TypeError("expected np.ndarray (got %s)", Py_TYPE(obj)->tp_name);
}
auto array = (PyArrayObject*)obj;
int ndim = PyArray_NDIM(array);
auto sizes = to_aten_shape(ndim, PyArray_DIMS(array));
auto strides = to_aten_shape(ndim, PyArray_STRIDES(array));
// NumPy strides use bytes. Torch strides use element counts.
auto element_size_in_bytes = PyArray_ITEMSIZE(array);
for (auto& stride : strides) {
stride /= element_size_in_bytes;
}
// (...) - omitted for brevity
void* data_ptr = PyArray_DATA(array);
auto& type = CPU(dtype_to_aten(PyArray_TYPE(array)));
Py_INCREF(obj);
return type.tensorFromBlob(data_ptr, sizes, strides, [obj](void* data) {
AutoGIL gil;
Py_DECREF(obj);
});
}
As you can see from this code, PyTorch is obtaining all information (array metadata) from Numpy representation and then creating its own. However, as you can note from the marked line 18, PyTorch is getting a pointer to the internal Numpy array raw data instead of copying it. This means that PyTorch will create a reference for this data, sharing the same memory region with the Numpy array object for the raw Tensor data.
There is also an important point here: when Numpy array object goes out of scope and get a zero reference count, it will be garbage collected and destroyed, that’s why there is an increment in the reference counting of the Numpy array object at line 20.
After this, PyTorch will create a new Tensor object from this Numpy data blob, and in the creation of this new Tensor it passes the borrowed memory data pointer, together with the memory size and strides as well as a function that will be used later by the Tensor Storage (we’ll discuss this in the next section) to release the data by decrementing the reference counting to the Numpy array object and let Python take care of this object life cycle.
The tensorFromBlob() method will create a new Tensor, but only after creating a new “Storage” for this Tensor. The storage is where the actual data pointer will be stored (and not in the Tensor structure itself). This takes us to the next section about Tensor Storages.
Tensor Storage
The actual raw data of the Tensor is not directly kept in the Tensor structure, but on another structure called Storage, which in turn is part of the Tensor structure.
As we saw in the previous code from tensor_from_numpy(), there is a call for tensorFromBlob() that will create a Tensor from the raw data blob. This last function will call another function called storageFromBlob() that will, in turn, create a storage for this data according to its type. In the case of a CPU float type, it will return a new CPUFloatStorage instance.
The CPUFloatStorage is basically a wrapper with utility functions around the actual storage structure called THFloatStorage that we show below:
As you can see, the THStorage holds a pointer to the raw data, its size, flags and also an interesting field called allocator that we’ll soon discuss. It is also important to note that there is no metadata regarding on how to interpret the data inside the THStorage, this is due to the fact that the storage is “dumb” regarding of its contents and it is the Tensor responsibility to know how to “view” or interpret this data.
From this, you already probably realized that we can have multiple tensors pointing to the same storage but with different views of this data, and that’s why viewing a tensor with a different shape (but keeping the same number of elements) is so efficient. This Python code below shows that the data pointer in the storage is being shared after changing the way Tensor views its data:
As we can see in the example above, the data pointer on the storage of both Tensors are the same, but the Tensors represent a different interpretation of the storage data.
Now, as we saw in line 7 of the THFloatStorage structure, there is a pointer to a THAllocator structure there. And this is very important because it brings flexibility regarding the allocator that can be used to allocate the storage data. This structure is represented by the following code:
As you can see, there are three function pointer fields in this structure to define what an allocator means: a malloc, realloc and free. For CPU-allocated memory, these functions will, of course, relate to the traditional malloc/realloc/free POSIX functions, however, when we want a storage allocated on GPUs we’ll end up using the CUDA allocators such as the cudaMallocHost(), like we can see in the THCudaHostAllocator malloc function below:
You probably noticed a pattern in the repository organization, but it is important to keep in mind these conventions when navigating the repository, as summarized here (taken from the PyTorch lib readme):
TH = TorcH
THC = TorcHCuda
THCS = TorcHCuda Sparse
THCUNN = TorcHCUda Neural Network
THD = TorcHDistributed
THNN = TorcHNeural Network
THS = TorcH Sparse
This convention is also present in the function/class names and other objects, so it is important to always keep these patterns in mind. While you can find CPU allocators in the TH code, you’ll find CUDA allocators in the THC code.
Finally, we can see the composition of the main Tensor THTensor structure:
typedef struct THTensor
{
int64_t *size;
int64_t *stride;
int nDimension;
THStorage *storage;
ptrdiff_t storageOffset;
int refcount;
char flag;
} THTensor;
And as you can see, the main THTensor structure holds the size/strides/dimensions/offsets/etc as well as the storage (THStorage) for the Tensor data.
We can summarize all this structure that we saw in the diagram below:
Now, once we have requirements such as multi-processing where we want to share tensor data among multiple different processes, we need a shared memory approach to solve it, otherwise, every time another process needs a tensor or even when you want to implement Hogwild training procedure where all different processes will write to the same memory region (where the parameters are), you’ll need to make copies between processes, and this is very inefficient. Therefore we’ll discuss in the next section a special kind of storage for Shared Memory.
Shared Memory
Shared memory can be implemented in many different ways depending on the platform support. PyTorch supports some of them, but for the sake of simplicity, I’ll talk here about what happens on MacOS using the CPU (instead of GPU). Since PyTorch supports multiple shared memory approaches, this part is a little tricky to grasp into since it involves more levels of indirection in the code.
PyTorch provides a wrapper around the Python multiprocessing module and can be imported from torch.multiprocessing. The changes they implemented in this wrapper around the official Python multiprocessing were done to make sure that everytime a tensor is put on a queue or shared with another process, PyTorch will make sure that only a handle for the shared memory will be shared instead of a new entire copy of the Tensor.
Now, many people aren’t aware of a Tensor method from PyTorch called share_memory_(), however, this function is what triggers an entire rebuild of the storage memory for that particular Tensor. What this method does is to create a region of shared memory that can be used among different processes. This function will, in the end, call this following function below:
And as you can see, this function will create another storage using a special allocator called THManagedSharedAllocator. This function first defines some flags and then it creates a handle which is a string in the format /torch_[process id]_[random number], and after that, it will then create a new storage using the special THManagedSharedAllocator. This allocator has function pointers to an internal PyTorch library called libshm, that will implement a Unix Domain Socket communication to share the shared memory region handles. This allocator is actual an especial case and it is a kind of “smart allocator” because it contains the communication control logic as well as it uses another allocator called THRefcountedMapAllocator that will be responsible for creating the actual shared memory region and call mmap() to map this region to the process virtual address space.
Note: when a method ends with a underscore in PyTorch, such as the method called share_memory_(), it means that this method has an in-place effect, and it will change the current object instead of creating a new one with the modifications.
I’ll now show a Python example of one processing using the data from a Tensor that was allocated on another process by manually exchanging the shared memory handle:
In this code, executed in the process A, we create a new Tensor of 5×5 filled with ones. After that we make it shared and print the tuple with the Unix Domain Socket address as well as the handle. Now we can access this memory region from another process B as shown below:
As you can see, using the tuple information about the Unix Domain Socket address and the handle we were able to access the Tensor storage from another process. If you change the tensor in this process B, you’ll also see that it will reflect in the process A because these Tensors are sharing the same memory region.
DLPack: a hope for the Deep Learning frameworks Babel
Now I would like to talk about something recent in the PyTorch code base, that is called DLPack. DLPack is an open standardization of an in-memory tensor structure that will allow exchange tensor data between frameworks, and what is quite interesting is that since this memory representation is standardized and very similar to the memory representation already in use by many frameworks, it will allow a zero-copy data sharing between frameworks, which is a quite amazing initiative given the variety of frameworks we have today without inter-communication among them.
This will certainly help to overcome the “island model” that we have today between tensor representations in MXNet, PyTorch, etc, and will allow developers to mix framework operations between frameworks and all the benefits that a standardization can bring to the frameworks.
The core of DLPack os a very simple structure called DLTensor, as shown below:
/*!
* \brief Plain C Tensor object, does not manage memory.
*/
typedef struct {
/*!
* \brief The opaque data pointer points to the allocated data.
* This will be CUDA device pointer or cl_mem handle in OpenCL.
* This pointer is always aligns to 256 bytes as in CUDA.
*/
void* data;
/*! \brief The device context of the tensor */
DLContext ctx;
/*! \brief Number of dimensions */
int ndim;
/*! \brief The data type of the pointer*/
DLDataType dtype;
/*! \brief The shape of the tensor */
int64_t* shape;
/*!
* \brief strides of the tensor,
* can be NULL, indicating tensor is compact.
*/
int64_t* strides;
/*! \brief The offset in bytes to the beginning pointer to data */
uint64_t byte_offset;
} DLTensor;
As you can see, there is a data pointer for the raw data as well as shape/stride/offset/GPU vs CPU, and other metadata information about the data that the DLTensor pointing to.
There is also a managed version of the tensor that is called DLManagedTensor, where the frameworks can provide a context and also a “deleter” function that can be called by the framework who borrowed the Tensor to inform the other framework that the resources are no longer required.
In PyTorch, if you want to convert to or from a DLTensor format, you can find both C/C++ methods for doing that or even in Python you can do that as shown below:
import torch
from torch.utils import dlpack
t = torch.ones((5, 5))
dl = dlpack.to_dlpack(t)
This Python function will call the toDLPack function from ATen, shown below:
As you can see, it’s a pretty simple conversion, casting the metadata from the PyTorch format to the DLPack format and assigning a pointer to the internal Tensor data representation.
I really hope that more frameworks adopt this standard that will certainly give benefits to the ecosystem. It is also interesting to note that a potential integration with Apache Arrow would be amazing.
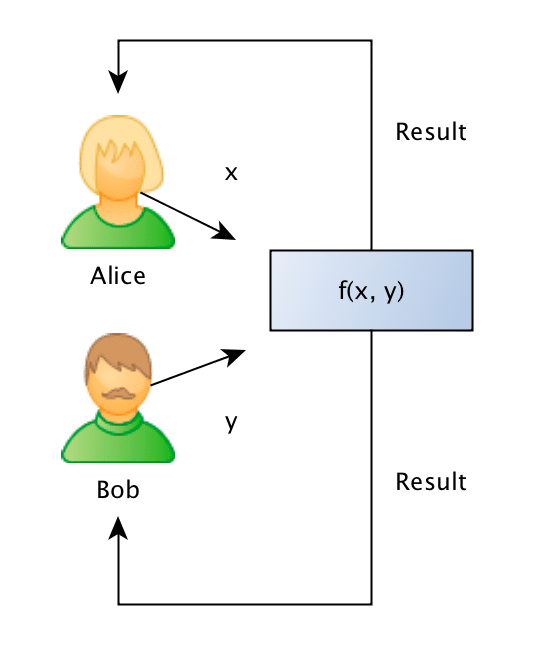
Privacy-preserving computation or secure computation is a sub-field of cryptography where two (two-party, or 2PC) or multiple (multi-party, or MPC) parties can evaluate a function together without revealing information about the parties private input data to each other. The problem and the first solution to it were introduced in 1982 by an amazing breakthrough done by Andrew Yao on what later became known as the “Yao’s Millionaires’ problem“.
The Yao’s Millionaires Problem is where two millionaires, Alice and Bob, who are interested in knowing which of them is richer but without revealing to each other their actual wealth. In other words, what they want can be generalized as that: Alice and Bob want jointly compute a function securely, without knowing anything other than the result of the computation on the input data (that remains private to them).
To make the problem concrete, Alice has an amount A such as $10, and Bob has an amount B such as $ 50, and what they want to know is which one is larger, without Bob revealing the amount B to Alice or Alice revealing the amount A to Bob. It is also important to note that we also don’t want to trust on a third-party, otherwise the problem would just be a simple protocol of information exchange with the trusted party.
Formally what we want is to jointly evaluate the following function:
Such as the private values A and B are held private to the sole owner of it and where the result r will be known to just one or both of the parties.
It seems very counterintuitive that a problem like that could ever be solved, but for the surprise of many people, it is possible to solve it on some security requirements. Thanks to the recent developments in techniques such as FHE (Fully Homomorphic Encryption), Oblivious Transfer, Garbled Circuits, problems like that started to get practical for real-life usage and they are being nowadays being used by many companies in applications such as information exchange, secure location, advertisement, satellite orbit collision avoidance, etc.
I’m not going to enter into details of these techniques, but if you’re interested in the intuition behind the OT (Oblivious Transfer), you should definitely read the amazing explanation done by Craig Gidney here. There are also, of course, many different protocols for doing 2PC or MPC, where each one of them assumes some security requirements (semi-honest, malicious, etc), I’m not going to enter into the details to keep the post focused on the goal, but you should be aware of that.
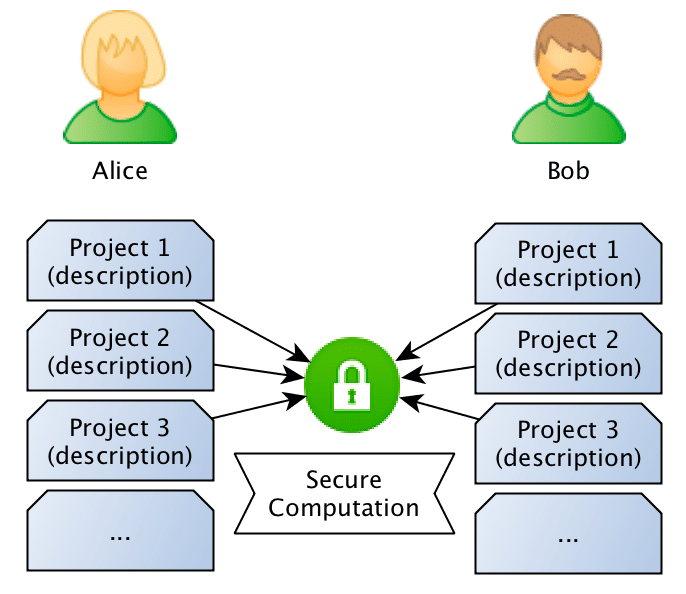
The problem: sentence similarity
What we want to achieve is to use privacy-preserving computation to calculate the similarity between sentences without disclosing the content of the sentences. Just to give a concrete example: Bob owns a company and has the description of many different projects in sentences such as: “This project is about building a deep learning sentiment analysis framework that will be used for tweets“, and Alice who owns another competitor company, has also different projects described in similar sentences. What they want to do is to jointly compute the similarity between projects in order to find if they should be doing partnership on a project or not, however, and this is the important point: Bob doesn’t want Alice to know the project descriptions and neither Alice wants Bob to be aware of their projects, they want to know the closest match between the different projects they run, but without disclosing the project ideas (project descriptions).
Sentence Similarity Comparison
Now, how can we exchange information about the Bob and Alice’s project sentences without disclosing information about the project descriptions ?
One naive way to do that would be to just compute the hashes of the sentences and then compare only the hashes to check if they match. However, this would assume that the descriptions are exactly the same, and besides that, if the entropy of the sentences is small (like small sentences), someone with reasonable computation power can try to recover the sentence.
Another approach for this problem (this is the approach that we’ll be using), is to compare the sentences in the sentence embeddings space. We just need to create sentence embeddings using a Machine Learning model (we’ll use InferSent later) and then compare the embeddings of the sentences. However, this approach also raises another concern: what if Bob or Alice trains a Seq2Seq model that would go from the embeddings of the other party back to an approximate description of the project ?
It isn’t unreasonable to think that one can recover an approximate description of the sentence given their embeddings. That’s why we’ll use the two-party secure computation for computing the embeddings similarity, in a way that Bob and Alice will compute the similarity of the embeddings without revealing their embeddings, keeping their project ideas safe.
The entire flow is described in the image below, where Bob and Alice shares the same Machine Learning model, after that they use this model to go from sentences to embeddings, followed by a secure computation of the similarity in the embedding space.
Diagram overview of the entire process.
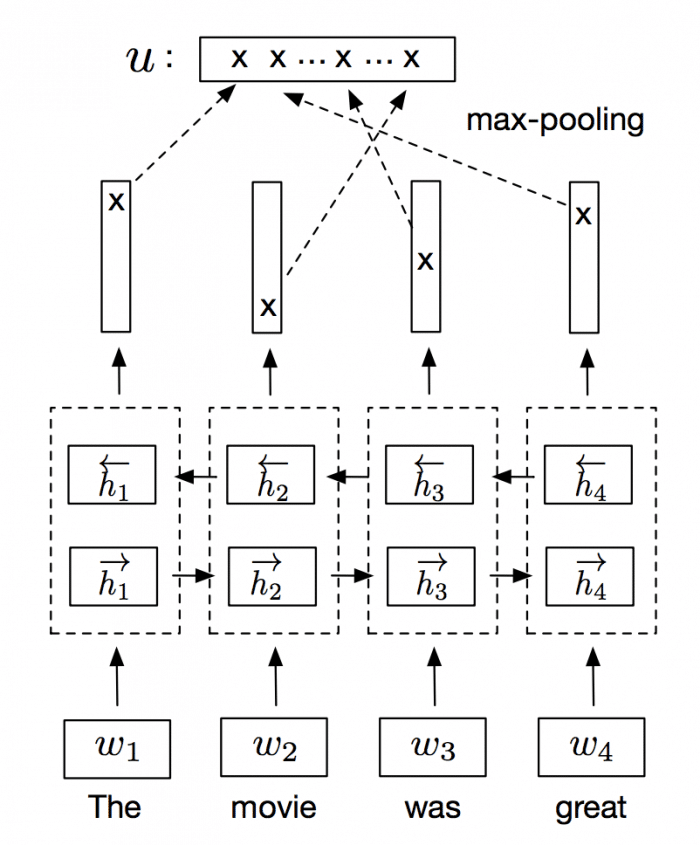
Generating sentence embeddings with InferSent
Bi-LSTM max-pooling network. Source: Supervised Learning of Universal Sentence Representations from Natural Language Inference Data. Alexis Conneau et al.
InferSent is an NLP technique for universal sentence representation developed by Facebook that uses supervised training to produce high transferable representations.
They used a Bi-directional LSTM with attention that consistently surpassed many unsupervised training methods such as the SkipThought vectors. They also provide a Pytorch implementation that we’ll use to generate sentence embeddings.
Note: even if you don’t have GPU, you can have reasonable performance doing embeddings for a few sentences.
The first step to generate the sentence embeddings is to download and load a pre-trained InferSent model:
import numpy as np
import torch
# Trained model from: https://github.com/facebookresearch/InferSent
GLOVE_EMBS = '../dataset/GloVe/glove.840B.300d.txt'
INFERSENT_MODEL = 'infersent.allnli.pickle'
# Load trained InferSent model
model = torch.load(INFERSENT_MODEL,
map_location=lambda storage, loc: storage)
model.set_glove_path(GLOVE_EMBS)
model.build_vocab_k_words(K=100000)
As you can see, if we have two unit vectors (vectors with norm 1), the two terms in the equation denominator will be 1 and we will be able to remove the entire denominator of the equation, leaving only:
So, if we normalize our vectors to have a unit norm (that’s why the vectors are wearing hats in the equation above), we can make the computation of the cosine similarity become just a simple dot product. That will help us a lot in computing the similarity distance later when we’ll use a framework to do the secure computation of this dot product.
So, the next step is to define a function that will take some sentence text and forward it to the model to generate the embeddings and then normalize them to unit vectors:
# This function will forward the text into the model and
# get the embeddings. After that, it will normalize it
# to a unit vector.
def encode(model, text):
embedding = model.encode([text])[0]
embedding /= np.linalg.norm(embedding)
return embedding
As you can see, this function is pretty simple, it feeds the text into the model, and then it will divide the embedding vector by the embedding norm.
Now, for practical reasons, I’ll be using integer computation later for computing the similarity, however, the embeddings generated by InferSent are of course real values. For that reason, you’ll see in the code below that we create another function to scale the float values and remove the radix point andconverting them to integers. There is also another important issue, the framework that we’ll be using later for secure computation doesn’t allow signed integers, so we also need to clip the embeddings values between 0.0 and 1.0. This will of course cause some approximation errors, however, we can still get very good approximations after clipping and scaling with limited precision (I’m using 14 bits for scaling to avoid overflow issues later during dot product computations):
# This function will scale the embedding in order to
# remove the radix point.
def scale(embedding):
SCALE = 1 << 14
scale_embedding = np.clip(embedding, 0.0, 1.0) * SCALE
return scale_embedding.astype(np.int32)
You can use floating-point in your secure computations and there are a lot of frameworks that support them, however, it is more tricky to do that, and for that reason, I used integer arithmetic to simplify the tutorial. The function above is just a hack to make it simple. It’s easy to see that we can recover this embedding later without too much loss of precision.
Now we just need to create some sentence samples that we’ll be using:
# The list of Alice sentences
alice_sentences = [
'my cat loves to walk over my keyboard',
'I like to pet my cat',
]
# The list of Bob sentences
bob_sentences = [
'the cat is always walking over my keyboard',
]
And convert them to embeddings:
# Alice sentences
alice_sentence1 = encode(model, alice_sentences[0])
alice_sentence2 = encode(model, alice_sentences[1])
# Bob sentences
bob_sentence1 = encode(model, bob_sentences[0])
Since we have now the sentences and every sentence is also normalized, we can compute cosine similarity just by doing a dot product between the vectors:
As we can see, the first sentence of Bob is most similar (~0.87) with Alice first sentence than to the Alice second sentence (~0.62).
Since we have now the embeddings, we just need to convert them to scaled integers:
# Scale the Alice sentence embeddings
alice_sentence1_scaled = scale(alice_sentence1)
alice_sentence2_scaled = scale(alice_sentence2)
# Scale the Bob sentence embeddings
bob_sentence1_scaled = scale(bob_sentence1)
# This is the unit vector embedding for the sentence
>>> alice_sentence1
array([ 0.01698913, -0.0014404 , 0.0010993 , ..., 0.00252409,
0.00828147, 0.00466533], dtype=float32)
# This is the scaled vector as integers
>>> alice_sentence1_scaled
array([278, 0, 18, ..., 41, 135, 76], dtype=int32)
Now with these embeddings as scaled integers, we can proceed to the second part, where we’ll be doing the secure computation between two parties.
Two-party secure computation
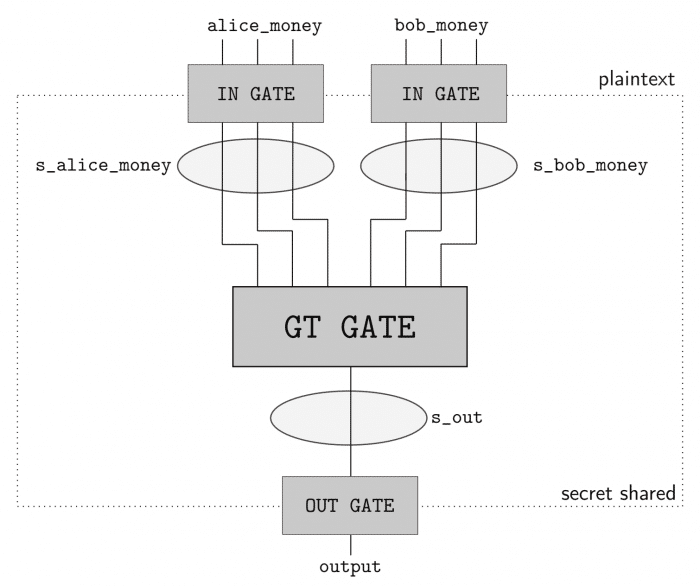
In order to perform secure computation between the two parties (Alice and Bob), we’ll use the ABY framework. ABY implements many difference secure computation schemes and allows you to describe your computation as a circuit like pictured in the image below, where the Yao’s Millionaire’s problem is described:
Yao’s Millionaires problem. Taken from ABY documentation (https://github.com/encryptogroup/ABY).
As you can see, we have two inputs entering in one GT GATE (greater than gate) and then a output. This circuit has a bit length of 3 for each input and will compute if the Alice input is greater than (GT GATE) the Bob input. The computing parties then secret share their private data and then can use arithmetic sharing, boolean sharing, or Yao sharing to securely evaluate these gates.
ABY is really easy to use because you can just describe your inputs, shares, gates and it will do the rest for you such as creating the socket communication channel, exchanging data when needed, etc. However, the implementation is entirely written in C++ and I’m not aware of any Python bindings for it (a great contribution opportunity).
Fortunately, there is an implemented example for ABY that can do dot product calculation for us, the example is here. I won’t replicate the example here, but the only part that we have to change is to read the embedding vectors that we created before instead of generating random vectors and increasing the bit length to 32-bits.
After that, we just need to execute the application on two different machines (or by emulating locally like below):
# This will execute the server part, the -r 0 specifies the role (server)
# and the -n 4096 defines the dimension of the vector (InferSent generates
# 4096-dimensional embeddings).
~# ./innerproduct -r 0 -n 4096
# And the same on another process (or another machine, however for another
# machine execution you'll have to obviously specify the IP).
~# ./innerproduct -r 1 -n 4096
And we get the following results:
Inner Product of alice_sentence1 and bob_sentence1 = 226691917
Inner Product of alice_sentence2 and bob_sentence1 = 171746521
Even in the integer representation, you can see that the inner product of the Alice’s first sentence and the Bob sentence is higher, meaning that the similarity is also higher. But let’s now convert this value back to float:
>>> SCALE = 1 << 14
# This is the dot product we should get
>>> np.dot(alice_sentence1, bob_sentence1)
0.8798542
# This is the inner product we got on secure computation
>>> 226691917 / SCALE**2.0
0.8444931
# This is the dot product we should get
>>> np.dot(alice_sentence2, bob_sentence1)
0.6297632
# This is the inner product we got on secure computation
>>> 171746521 / SCALE**2.0
0.6398056
As you can see, we got very good approximations, even in presence of low-precision math and unsigned integer requirements. Of course that in real-life you won’t have the two values and vectors, because they’re supposed to be hidden, but the changes to accommodate that are trivial, you just need to adjust ABY code to load only the vector of the party that it is executing it and using the correct IP addresses/port of the both parties.
The receptive field in Convolutional Neural Networks (CNN) is the region of the input space that affects a particular unit of the network. Note that this input region can be not only the input of the network but also output from other units in the network, therefore this receptive field can be calculated relative to the input that we consider and also relative the unit that we are taking into consideration as the “receiver” of this input region. Usually, when the receptive field term is mentioned, it is taking into consideration the final output unit of the network (i.e. a single unit on a binary classification task) in relation to the network input (i.e. input image of the network).
It is easy to see that on a CNN, the receptive field can be increased using different methods such as: stacking more layers (depth), subsampling (pooling, striding), filter dilation (dilated convolutions), etc. In theory, when you stack more layers you can increase your receptive field linearly, however, in practice, things aren’t simple as we thought, as shown by Luo, Wenjie et al. article. In the article, they introduce the concept of the “Effective Receptive Field”, or ERF; the intuition behind the concept is that not all pixels in the receptive field contribute equally to the output unit’s response. When doing the forward pass, we can see that the central receptive field pixels can propagate their information to the output using many different paths, as they are part of multiple output unit’s calculations.
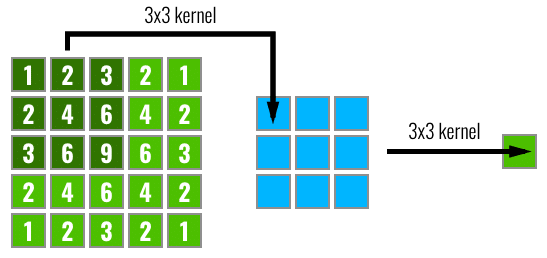
In the figure below, we can see in left the input pixels, after that we have a feature map calculated from the input pixels using a 3×3 convolution filter and then finally the output after another 3×3 filtering. The numbers inside the pixels on the left image represent how many times this pixel was part of a convolution step (each sliding step of the filter). As we can see, some pixels like the central ones will have their information propagated through many different paths in the network, while the pixels on the borders are propagated along a single path.
Receptive Field across 3 different layers using 3×3 filters.
By looking at the image above, it isn’t that surprising that the effective receptive field impact on the final output computation will look more like a Gaussian distribution instead of a uniform distribution. What is actually more even interesting is that this receptive field is dynamic and changes during the training. The impact of this on the backpropagation is that the central pixels will have a larger gradient magnitude when compared to the border pixels.
In the article written by Luo, Wenjie et al., they devised a way to quantify the effect on each input pixel of the network by calculating the quantity that represents how much each pixel contributes to the output .
In the paper, they did experimentations to visualize the effective receptive field using multiple different architectures, activations, etc. I replicate here the ones that I found most interesting:
Figure 1 from the paper “Understanding the Effective Receptive Field in Deep Convolutional Neural Networks”, by Luo, Wenjie et al.
As we can see from the Figure 1 of the paper, where they compare the effect of the number of layers, initialization schemes, and different activations, the results are amazing. We can clearly see the Gaussian and also the sparsity added by the ReLU activations.
There are also some comparisons on Figure 3 of the paper, where CIFAR-10 and CamVid datasets were used to train the network.
Figure 3 of the paper “Understanding the Effective Receptive Field in Deep Convolutional Neural Networks”, by Luo, Wenjie et al.
As we can see, the size of the effective receptive field is very dynamic and it is increased by a large margin after the training, which implies, as stated by authors of the paper, that better initialization schemes can be employed to increase the receptive field in the beginning of the training. They actually developed a different initialization scheme and were able to get 30% training speed-up, however, these results weren’t consistent.
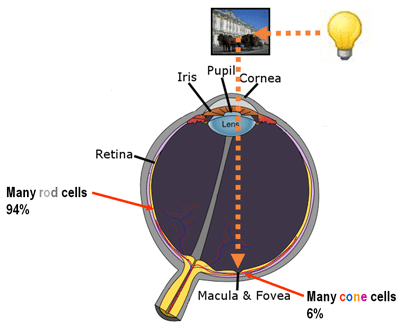
Foveal vision on reading activity. Image from http://www.learning-systems.ch.
What is also very interesting, is that the effective receptive field has a very close relationship with the foveal vision of the human eye, which produces the sharp central vision, effect of the high-density region of cone cells (as shown in the image below) present in the eye fundus.
Fovea region on the human eye. Image from http://eyetracking.me.
Our central sharp vision also decays rapidly like the effective receptive field that is very similar to a Gaussian. It is amazing that this effect is also naturally present on the CNN networks.
PS: Just for the sake of curiosity, some birds that do complex aerial movements such as the hummingbird, have two foveas instead of a single one, which means that they have a sharp accurate vision not only on the central region but also on the sides.
One of the most amazing components of the TensorFlow architecture is the computation graph that can be serialized using Protocol Buffers. This computation graph follows a well-defined format (click here for the proto files) and describes the computation that you specify (it can be a Deep Learning model like a CNN, a simple Logistic Regression or even any computation you want). For instance, here is an example of a very simple TensorFlow computation graph that we will use in this tutorial (using TensorFlow Python API):
As you can see, this is a very simple computation graph. First, we define the placeholder that will hold the input tensor and after that we specify the computation that should happen using this input tensor as input data. Here we can also see that we’re defining two important nodes of this graph, one is called “input” (the aforementioned placeholder) and the other is called “output“, that will hold the result of the final computation. This graph is the same as the following formula for a scalar: , where I intentionally added redundant operations to see LLVM constant propagation later.
In the last line of the code, we’re persisting this computation graph (including the constant values) into a serialized protobuf file. The final True parameter is to output a textual representation instead of binary, so it will produce the following human-readable output protobuf file (I omitted a part of it for brevity):
This is a very simple graph, and TensorFlow graphs are actually never that simple, because TensorFlow models can easily contain more than 300 nodes depending on the model you’re specifying, specially for Deep Learning models.
We’ll use the above graph to show how we can JIT native code for this simple graph using LLVM framework.
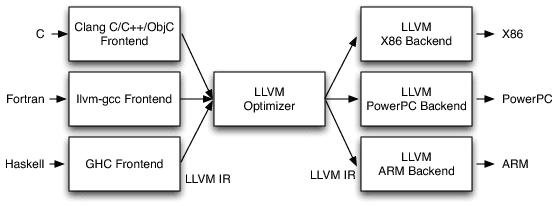
The LLVM Frontend, IR and Backend
The LLVM framework is a really nice, modular and complete ecosystem for building compilers and toolchains. A very nice description of the LLVM architecture that is important for us is shown in the picture below:
LLVM Compiler Architecture (AOSA/LLVM, Chris Lattner)
(The picture above is just a small part of the LLVM architecture, for a comprehensive description of it, please see the nice article from the AOSA book written by Chris Lattner)
Looking in the image above, we can see that LLVM provides a lot of core functionality, in the left side you see that many languages can write code for their respective language frontends, after that it doesn’t matter in which language you wrote your code, everything is transformed into a very powerful language called LLVM IR (LLVM Intermediate Representation) which is as you can imagine, a intermediate representation of the code just before the assembly code itself. In my opinion, the IR is the key component of what makes LLVM so amazing, because it doesn’t matter in which language you wrote your code (or even if it was a JIT’ed IR), everything ends in the same representation, and then here is where the magic happens, because the IR can take advantage of the LLVM optimizations (also known as transform and analysis passes).
After this IR generation, you can feed it into any LLVM backend to generate native code for any architecture supported by LLVM (such as x86, ARM, PPC, etc) and then you can finally execute your code with the native performance and also after LLVM optimization passes.
In order to JIT code using LLVM, all you need is to build the IR programmatically, create a execution engine to convert (during execution-time) the IR into native code, get a pointer for the function you have JIT’ed and then finally execute it. I’ll use here a Python binding for LLVM called llvmlite, which is very Pythonic and easy to use.
JIT’ing TensorFlow Graph using Python and LLVM
Let’s now use the LLVM and Python to JIT the TensorFlow computational graph. This is by no means a comprehensive implementation, it is very simplistic approach, a oversimplification that assumes some things: a integer closure type, just some TensorFlow operations and also a single scalar support instead of high rank tensors.
So, let’s start building our JIT code; first of all, let’s import the required packages, initialize some LLVM sub-systems and also define the LLVM respective type for the TensorFlow integer type:
from ctypes import CFUNCTYPE, c_int
import tensorflow as tf
from google.protobuf import text_format
from tensorflow.core.framework import graph_pb2
from tensorflow.core.framework import types_pb2
from tensorflow.python.framework import ops
import llvmlite.ir as ll
import llvmlite.binding as llvm
llvm.initialize()
llvm.initialize_native_target()
llvm.initialize_native_asmprinter()
TYPE_TF_LLVM = {
types_pb2.DT_INT32: ll.IntType(32),
}
After that, let’s define a class to open the TensorFlow exported graph and also declare a method to get a node of the graph by name:
class TFGraph(object):
def __init__(self, filename="graph.pb", binary=False):
self.graph_def = graph_pb2.GraphDef()
with open("graph.pb", "rb") as f:
if binary:
self.graph_def.ParseFromString(f.read())
else:
text_format.Merge(f.read(), self.graph_def)
def get_node(self, name):
for node in self.graph_def.node:
if node.name == name:
return node
And let’s start by defining our main function that will be the starting point of the code:
As you can see in the code above, we open the serialized protobuf graph and then get the input and output nodes of this graph. After that we also map the type of the both graph nodes (input/output) to the LLVM type (from TensorFlow integer to LLVM integer). We start then by defining a LLVM Module, which is the top level container for all IR objects. One module in LLVM can contain many different functions, here we will create just one function that will represent the graph, this function will receive as input argument the input data of the same type of the input node and then it will return a value with the same type of the output node.
After that we start by creating the entry block of the function and using this block we instantiate our IR Builder, which is a object that will provide us the building blocks for JIT’ing operations of TensorFlow graph.
Let’s now define the function that will do the real work of converting TensorFlow nodes into LLVM IR:
def build_graph(ir_builder, graph, node):
if node.op == "Add":
left_op_node = graph.get_node(node.input[0])
right_op_node = graph.get_node(node.input[1])
left_op = build_graph(ir_builder, graph, left_op_node)
right_op = build_graph(ir_builder, graph, right_op_node)
return ir_builder.add(left_op, right_op)
if node.op == "Sub":
left_op_node = graph.get_node(node.input[0])
right_op_node = graph.get_node(node.input[1])
left_op = build_graph(ir_builder, graph, left_op_node)
right_op = build_graph(ir_builder, graph, right_op_node)
return ir_builder.sub(left_op, right_op)
if node.op == "Placeholder":
function_args = ir_builder.function.args
for arg in function_args:
if arg.name == node.name:
return arg
raise RuntimeError("Input [{}] not found !".format(node.name))
if node.op == "Const":
llvm_const_type = TYPE_TF_LLVM[node.attr["dtype"].type]
const_value = node.attr["value"].tensor.int_val[0]
llvm_const_value = llvm_const_type(const_value)
return llvm_const_value
In this function, we receive by parameters the IR Builder, the graph class that we created earlier and the output node. This function will then recursively build the LLVM IR by means of the IR Builder. Here you can see that I only implemented the Add/Sub/Placeholder and Const operations from the TensorFlow graph, just to be able to support the graph that we defined earlier.
After that, we just need to define a function that will take a LLVM Module and then create a execution engine that will execute the LLVM optimization over the LLVM IR before doing the hard-work of converting the IR into native x86 code:
In the code above, you can see that we first get the CPU features (SSE, etc) into a list, after that we parse the LLVM IR from the module and then we create a engine using maximum optimization level (opt=3, roughly equivalent to the GCC -O3 parameter), we’re also printing the assembly code (in my case, the x86 assembly built by LLVM).
And here we just finish our run_main() function:
ret = build_graph(ir_builder, graph, output_node)
ir_builder.ret(ret)
with open("output.ir", "w") as f:
f.write(str(module))
engine = create_engine(module)
func_ptr = engine.get_function_address("tensorflow_graph")
cfunc = CFUNCTYPE(c_int, c_int)(func_ptr)
ret = cfunc(10)
print "Execution output: {}".format(ret)
As you can see in the code above, we just call the build_graph() method and then use the IR Builder to add the “ret” LLVM IR instruction (ret = return) to return the output of the IR function we just created based on the TensorFlow graph. We’re also here writing the IR output to a external file, I’ll use this LLVM IR file later to create native assembly for other different architectures such as ARM architecture. And finally, just get the native code function address, create a Python wrapper for this function and then call it with the argument “10”, which will be input data and then output the resulting output value.
And that is it, of course that this is just a oversimplification, but now we understand the advantages of having a JIT for our TensorFlow models.
The output LLVM IR, the advantage of optimizations and multiple architectures (ARM, PPC, x86, etc)
For instance, lets create the LLVM IR (using the code I shown above) of the following TensorFlow graph:
As you can see, the LLVM IR looks a lot like an assembly code, but this is not the final assembly code, this is just a non-optimized IR yet. Just before generating the x86 assembly code, LLVM runs a lot of optimization passes over the LLVM IR, and it will do things such as dead code elimination, constant propagation, etc. And here is the final native x86 assembly code that LLVM generates for the above LLVM IR of the TensorFlow graph:
As you can see, the optimized code removed a lot of redundant operations, and ended up just doing a add operation of 103, which is the correct simplification of the computation that we defined in the graph. For large graphs, you can see that these optimizations can be really powerful, because we are reusing the compiler optimizations that were developed for years in our Machine Learning model computation.
You can also use a LLVM tool called “llc”, that can take an LLVM IR file and the generate assembly for any other platform you want, for instance, the command-line below will generate native code for ARM architecture:
As you can see above, the ARM assembly code is also just a “add” assembly instruction followed by a return instruction.
This is really nice because we can take natural advantage of the LLVM framework. For instance, today ARM just announced the ARMv8-A with Scalable Vector Extensions (SVE) that will support 2048-bit vectors, and they are already working on patches for LLVM. In future, a really nice addition to LLVM would be the development of LLVM Passes for analysis and transformation that would take into consideration the nature of Machine Learning models.
And that’s it, I hope you liked the post ! Is really awesome what you can do with a few lines of Python, LLVM and TensorFlow.
Update 22 Aug 2016: TensorFlow team is actually working on a JIT (I don’t know if they are using LLVM, but it seems the most reasonable way to go in my opinion). In their paper, there is also a very important statement regarding Future Work that I cite here:
“We also have a number of concrete directions to improve the performance of TensorFlow. One such direction is our initial work on a just-in-time compiler that can take a subgraph of a TensorFlow execution, perhaps with some runtime profiling information about the typical sizes and shapes of tensors, and can generate an optimized routine for this subgraph. This compiler will understand the semantics of perform a number of optimizations such as loop fusion, blocking and tiling for locality, specialization for particular shapes and sizes, etc.” – TensorFlow White Paper
Full code
from ctypes import CFUNCTYPE, c_int
import tensorflow as tf
from google.protobuf import text_format
from tensorflow.core.framework import graph_pb2
from tensorflow.core.framework import types_pb2
from tensorflow.python.framework import ops
import llvmlite.ir as ll
import llvmlite.binding as llvm
llvm.initialize()
llvm.initialize_native_target()
llvm.initialize_native_asmprinter()
TYPE_TF_LLVM = {
types_pb2.DT_INT32: ll.IntType(32),
}
class TFGraph(object):
def __init__(self, filename="graph.pb", binary=False):
self.graph_def = graph_pb2.GraphDef()
with open("graph.pb", "rb") as f:
if binary:
self.graph_def.ParseFromString(f.read())
else:
text_format.Merge(f.read(), self.graph_def)
def get_node(self, name):
for node in self.graph_def.node:
if node.name == name:
return node
def build_graph(ir_builder, graph, node):
if node.op == "Add":
left_op_node = graph.get_node(node.input[0])
right_op_node = graph.get_node(node.input[1])
left_op = build_graph(ir_builder, graph, left_op_node)
right_op = build_graph(ir_builder, graph, right_op_node)
return ir_builder.add(left_op, right_op)
if node.op == "Sub":
left_op_node = graph.get_node(node.input[0])
right_op_node = graph.get_node(node.input[1])
left_op = build_graph(ir_builder, graph, left_op_node)
right_op = build_graph(ir_builder, graph, right_op_node)
return ir_builder.sub(left_op, right_op)
if node.op == "Placeholder":
function_args = ir_builder.function.args
for arg in function_args:
if arg.name == node.name:
return arg
raise RuntimeError("Input [{}] not found !".format(node.name))
if node.op == "Const":
llvm_const_type = TYPE_TF_LLVM[node.attr["dtype"].type]
const_value = node.attr["value"].tensor.int_val[0]
llvm_const_value = llvm_const_type(const_value)
return llvm_const_value
def create_engine(module):
features = llvm.get_host_cpu_features().flatten()
llvm_module = llvm.parse_assembly(str(module))
target = llvm.Target.from_default_triple()
target_machine = target.create_target_machine(opt=3, features=features)
engine = llvm.create_mcjit_compiler(llvm_module, target_machine)
engine.finalize_object()
print target_machine.emit_assembly(llvm_module)
return engine
def run_main():
graph = TFGraph("graph.pb", False)
input_node = graph.get_node("input")
output_node = graph.get_node("output")
input_type = TYPE_TF_LLVM[input_node.attr["dtype"].type]
output_type = TYPE_TF_LLVM[output_node.attr["T"].type]
module = ll.Module()
func_type = ll.FunctionType(output_type, [input_type])
func = ll.Function(module, func_type, name='tensorflow_graph')
func.args[0].name = 'input'
bb_entry = func.append_basic_block('entry')
ir_builder = ll.IRBuilder(bb_entry)
ret = build_graph(ir_builder, graph, output_node)
ir_builder.ret(ret)
with open("output.ir", "w") as f:
f.write(str(module))
engine = create_engine(module)
func_ptr = engine.get_function_address("tensorflow_graph")
cfunc = CFUNCTYPE(c_int, c_int)(func_ptr)
ret = cfunc(10)
print "Execution output: {}".format(ret)
if __name__ == "__main__":
run_main()
Presentation about an “Achitectural Zoo” of different applications and architectures of CNNs. Presented at Machine Learning Meetup in Porto Alegre yesterday.
This website uses cookies to improve your experience. We'll assume you're ok with this, but you can opt-out if you wish. Cookie settingsACCEPT
Privacy & Cookies Policy
Privacy Overview
This website uses cookies to improve your experience while you navigate through the website. Out of these cookies, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may have an effect on your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.
 One of the most interesting aspects of Wittgenstein is perhaps that fact that he had developed two very different philosophies during his life, and each of which had great influence. Something quite rare for someone who spent so much time working on these ideas and retreating even after the major influence they exerted, especially in the Vienna Circle. A true lesson of intellectual honesty, and in my opinion, one important legacy.
One of the most interesting aspects of Wittgenstein is perhaps that fact that he had developed two very different philosophies during his life, and each of which had great influence. Something quite rare for someone who spent so much time working on these ideas and retreating even after the major influence they exerted, especially in the Vienna Circle. A true lesson of intellectual honesty, and in my opinion, one important legacy.
 John R. Firth
John R. Firth


")
 What they want to do is to jointly compute the similarity between projects in order to find if they should be doing partnership on a project or not, however, and this is the important point: Bob doesn’t want Alice to know the project descriptions and neither Alice wants Bob to be aware of their projects, they want to know the closest match between the different projects they run, but without disclosing the project ideas (project descriptions).
What they want to do is to jointly compute the similarity between projects in order to find if they should be doing partnership on a project or not, however, and this is the important point: Bob doesn’t want Alice to know the project descriptions and neither Alice wants Bob to be aware of their projects, they want to know the closest match between the different projects they run, but without disclosing the project ideas (project descriptions).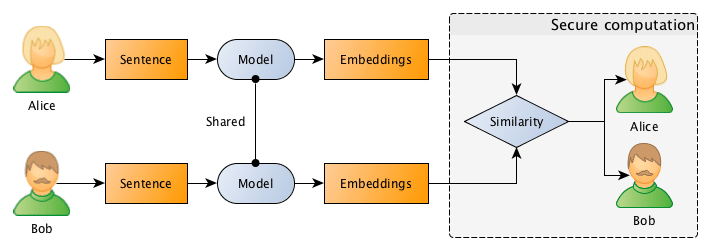
 = \frac {\pmb x \cdot \pmb y}{||\pmb x|| \cdot ||\pmb y||}")
 =\hat{x} \cdot\hat{y}")
 that represents how much each pixel
that represents how much each pixel  contributes to the output
contributes to the output  .
.

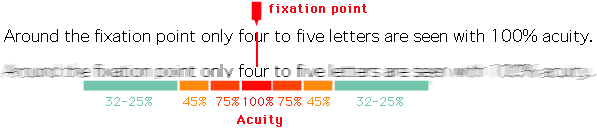

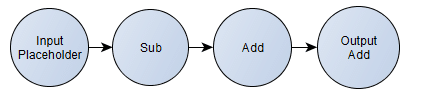
-5)+100)") , where I intentionally added redundant operations to see LLVM constant propagation later.
, where I intentionally added redundant operations to see LLVM constant propagation later.