Concentration inequalities, or probability bounds, are very important tools for the analysis of Machine Learning algorithms or randomized algorithms. In statistical learning theory, we often want to show that random variables, given some assumptions, are close to its expectation with high probability. This article provides an overview of the most basic inequalities in the analysis of these concentration measures.
Markov’s Inequality
The Markov’s inequality is one of the most basic bounds and it assumes almost nothing about the random variable. The assumptions that Markov’s inequality makes is that the random variable \(X\) is non-negative \(X > 0\) and has a finite expectation \(\mathbb{E}\left[X\right] < \infty\). The Markov’s inequality is given by:
$$\underbrace{P(X \geq \alpha)}_{\text{Probability of being greater than constant } \alpha} \leq \underbrace{\frac{\mathbb{E}\left[X\right]}{\alpha}}_{\text{Bounded above by expectation over constant } \alpha}$$
What this means is that the probability that the random variable \(X\) will be bounded by the expectation of \(X\) divided by the constant \(\alpha\). What is remarkable about this bound, is that it holds for any distribution with positive values and it doesn’t depend on any feature of the probability distribution, it only requires some weak assumptions and its first moment, the expectation.
Example: A grocery store sells an average of 40 beers per day (it’s summer !). What is the probability that it will sell 80 or more beers tomorrow ?
The Markov’s inequality doesn’t depend on any property of the random variable probability distribution, so it’s obvious that there are better bounds to use if information about the probability distribution is available.
Chebyshev’s Inequality
When we have information about the underlying distribution of a random variable, we can take advantage of properties of this distribution to know more about the concentration of this variable. Let’s take for example a normal distribution with mean \(\mu = 0\) and unit standard deviation \(\sigma = 1\) given by the probability density function (PDF) below:
$$ f(x) = \frac{1}{\sqrt{2\pi}}e^{-x^2/2} $$
Integrating from -1 to 1: \(\int_{-1}^{1} \frac{1}{\sqrt{2\pi}}e^{-x^2/2}\), we know that 68% of the data is within \(1\sigma\) (one standard deviation) from the mean \(\mu\) and 95% is within \(2\sigma\) from the mean. However, when it’s not possible to assume normality, any other amount of data can be concentrated within \(1\sigma\) or \(2\sigma\).
Chebyshev’s inequality provides a way to get a bound on the concentration for any distribution, without assuming any underlying property except a finite mean and variance. Chebyshev’s also holds for any random variable, not only for non-negative variables as in Markov’s inequality.
The Chebyshev’s inequality is given by the following relation:
For the concrete case of \(k = 2\), the Chebyshev’s tells us that at least 75% of the data is concentrated within 2 standard deviations of the mean. And this holds for any distribution.
Now, when we compare this result for \( k = 2 \) with the 95% concentration of the normal distribution for \(2\sigma\), we can see how conservative is the Chebyshev’s bound. However, one must not forget that this holds for any distribution and not only for a normally distributed random variable, and all that Chebyshev’s needs, is the first and second moments of the data. Something important to note is that in absence of more information about the random variable, this cannot be improved.
Chebyshev’s Inequality and the Weak Law of Large Numbers
Chebyshev’s inequality can also be used to prove the weak law of large numbers, which says that the sample mean converges in probability towards the true mean.
That can be done as follows:
Consider a sequence of i.i.d. (independent and identically distributed) random variables \(X_1, X_2, X_3, \ldots\) with mean \(\mu\) and variance \(\sigma^2\);
The sample mean is \(M_n = \frac{X_1 + \ldots + X_n}{n}\) and the true mean is \(\mu\);
For the expectation of the sample mean we have: $$\mathbb{E}\left[M_n\right] = \frac{\mathbb{E}\left[X_1\right] + \ldots +\mathbb{E}\left[X_n\right]}{n} = \frac{n\mu}{n} = \mu$$
For the variance of the sample we have: $$Var\left[M_n\right] = \frac{Var\left[X_1\right] + \ldots +Var\left[X_n\right]}{n^2} = \frac{n\sigma^2}{n^2} = \frac{\sigma^2}{n}$$
By the application of the Chebyshev’s inequality we have: $$ P(\mid M_n – \mu \mid \geq \epsilon) \leq \frac{\sigma^2}{n\epsilon^2}$$ for any (fixed) \(\epsilon > 0\), as \(n\) increases, the right side of the inequality goes to zero. Intuitively, this means that for a large \(n\) the concentration of the distribution of \(M_n\) will be around \(\mu\).
Improving on Markov’s and Chebyshev’s with Chernoff Bounds
Before getting into the Chernoff bound, let’s understand the motivation behind it and how one can improve on Chebyshev’s bound. To understand it, we first need to understand the difference between a pairwise independence and mutual independence. For the pairwise independence, we have the following for A, B, and C:
$$
P(A \cap B) = P(A)P(B) \\
P(A \cap C) = P(A)P(C) \\
P(B \cap C) = P(B)P(C)
$$
Which means that any pair (any two events) are independent, but not necessarily that:
$$
P(A \cap B\cap C) = P(A)P(B)P(C)
$$
which is called “mutual independence” and it is a stronger independence. By definition, the mutual independence assumes the pairwise independence but the opposite isn’t always true. And this is the case where we can improve on Chebyshev’s bound, as it is not possible without doing these further assumptions (stronger assumptions leads to stronger bounds).
We’ll talk about the Chernoff bounds in the second part of this tutorial !
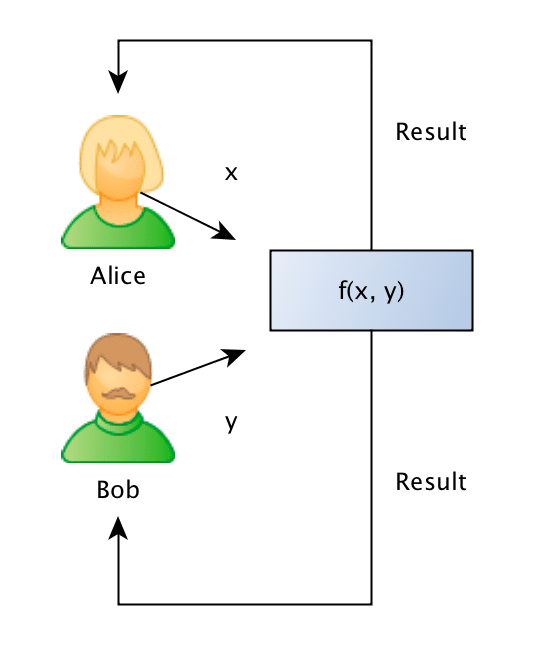
Privacy-preserving computation or secure computation is a sub-field of cryptography where two (two-party, or 2PC) or multiple (multi-party, or MPC) parties can evaluate a function together without revealing information about the parties private input data to each other. The problem and the first solution to it were introduced in 1982 by an amazing breakthrough done by Andrew Yao on what later became known as the “Yao’s Millionaires’ problem“.
The Yao’s Millionaires Problem is where two millionaires, Alice and Bob, who are interested in knowing which of them is richer but without revealing to each other their actual wealth. In other words, what they want can be generalized as that: Alice and Bob want jointly compute a function securely, without knowing anything other than the result of the computation on the input data (that remains private to them).
To make the problem concrete, Alice has an amount A such as $10, and Bob has an amount B such as $ 50, and what they want to know is which one is larger, without Bob revealing the amount B to Alice or Alice revealing the amount A to Bob. It is also important to note that we also don’t want to trust on a third-party, otherwise the problem would just be a simple protocol of information exchange with the trusted party.
Formally what we want is to jointly evaluate the following function:
Such as the private values A and B are held private to the sole owner of it and where the result r will be known to just one or both of the parties.
It seems very counterintuitive that a problem like that could ever be solved, but for the surprise of many people, it is possible to solve it on some security requirements. Thanks to the recent developments in techniques such as FHE (Fully Homomorphic Encryption), Oblivious Transfer, Garbled Circuits, problems like that started to get practical for real-life usage and they are being nowadays being used by many companies in applications such as information exchange, secure location, advertisement, satellite orbit collision avoidance, etc.
I’m not going to enter into details of these techniques, but if you’re interested in the intuition behind the OT (Oblivious Transfer), you should definitely read the amazing explanation done by Craig Gidney here. There are also, of course, many different protocols for doing 2PC or MPC, where each one of them assumes some security requirements (semi-honest, malicious, etc), I’m not going to enter into the details to keep the post focused on the goal, but you should be aware of that.
The problem: sentence similarity
What we want to achieve is to use privacy-preserving computation to calculate the similarity between sentences without disclosing the content of the sentences. Just to give a concrete example: Bob owns a company and has the description of many different projects in sentences such as: “This project is about building a deep learning sentiment analysis framework that will be used for tweets“, and Alice who owns another competitor company, has also different projects described in similar sentences. What they want to do is to jointly compute the similarity between projects in order to find if they should be doing partnership on a project or not, however, and this is the important point: Bob doesn’t want Alice to know the project descriptions and neither Alice wants Bob to be aware of their projects, they want to know the closest match between the different projects they run, but without disclosing the project ideas (project descriptions).
Sentence Similarity Comparison
Now, how can we exchange information about the Bob and Alice’s project sentences without disclosing information about the project descriptions ?
One naive way to do that would be to just compute the hashes of the sentences and then compare only the hashes to check if they match. However, this would assume that the descriptions are exactly the same, and besides that, if the entropy of the sentences is small (like small sentences), someone with reasonable computation power can try to recover the sentence.
Another approach for this problem (this is the approach that we’ll be using), is to compare the sentences in the sentence embeddings space. We just need to create sentence embeddings using a Machine Learning model (we’ll use InferSent later) and then compare the embeddings of the sentences. However, this approach also raises another concern: what if Bob or Alice trains a Seq2Seq model that would go from the embeddings of the other party back to an approximate description of the project ?
It isn’t unreasonable to think that one can recover an approximate description of the sentence given their embeddings. That’s why we’ll use the two-party secure computation for computing the embeddings similarity, in a way that Bob and Alice will compute the similarity of the embeddings without revealing their embeddings, keeping their project ideas safe.
The entire flow is described in the image below, where Bob and Alice shares the same Machine Learning model, after that they use this model to go from sentences to embeddings, followed by a secure computation of the similarity in the embedding space.
Diagram overview of the entire process.
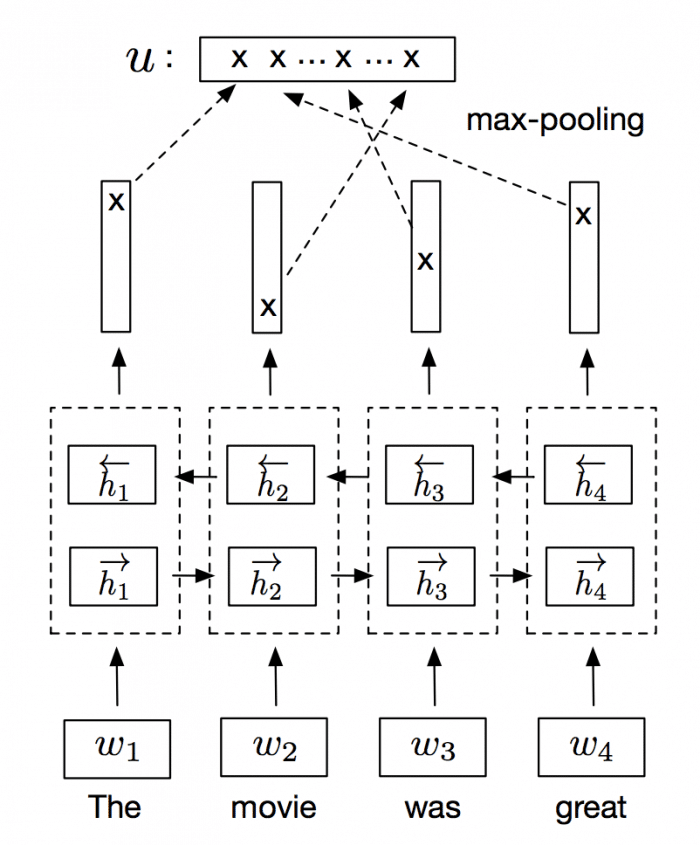
Generating sentence embeddings with InferSent
Bi-LSTM max-pooling network. Source: Supervised Learning of Universal Sentence Representations from Natural Language Inference Data. Alexis Conneau et al.
InferSent is an NLP technique for universal sentence representation developed by Facebook that uses supervised training to produce high transferable representations.
They used a Bi-directional LSTM with attention that consistently surpassed many unsupervised training methods such as the SkipThought vectors. They also provide a Pytorch implementation that we’ll use to generate sentence embeddings.
Note: even if you don’t have GPU, you can have reasonable performance doing embeddings for a few sentences.
The first step to generate the sentence embeddings is to download and load a pre-trained InferSent model:
import numpy as np
import torch
# Trained model from: https://github.com/facebookresearch/InferSent
GLOVE_EMBS = '../dataset/GloVe/glove.840B.300d.txt'
INFERSENT_MODEL = 'infersent.allnli.pickle'
# Load trained InferSent model
model = torch.load(INFERSENT_MODEL,
map_location=lambda storage, loc: storage)
model.set_glove_path(GLOVE_EMBS)
model.build_vocab_k_words(K=100000)
As you can see, if we have two unit vectors (vectors with norm 1), the two terms in the equation denominator will be 1 and we will be able to remove the entire denominator of the equation, leaving only:
So, if we normalize our vectors to have a unit norm (that’s why the vectors are wearing hats in the equation above), we can make the computation of the cosine similarity become just a simple dot product. That will help us a lot in computing the similarity distance later when we’ll use a framework to do the secure computation of this dot product.
So, the next step is to define a function that will take some sentence text and forward it to the model to generate the embeddings and then normalize them to unit vectors:
# This function will forward the text into the model and
# get the embeddings. After that, it will normalize it
# to a unit vector.
def encode(model, text):
embedding = model.encode([text])[0]
embedding /= np.linalg.norm(embedding)
return embedding
As you can see, this function is pretty simple, it feeds the text into the model, and then it will divide the embedding vector by the embedding norm.
Now, for practical reasons, I’ll be using integer computation later for computing the similarity, however, the embeddings generated by InferSent are of course real values. For that reason, you’ll see in the code below that we create another function to scale the float values and remove the radix point andconverting them to integers. There is also another important issue, the framework that we’ll be using later for secure computation doesn’t allow signed integers, so we also need to clip the embeddings values between 0.0 and 1.0. This will of course cause some approximation errors, however, we can still get very good approximations after clipping and scaling with limited precision (I’m using 14 bits for scaling to avoid overflow issues later during dot product computations):
# This function will scale the embedding in order to
# remove the radix point.
def scale(embedding):
SCALE = 1 << 14
scale_embedding = np.clip(embedding, 0.0, 1.0) * SCALE
return scale_embedding.astype(np.int32)
You can use floating-point in your secure computations and there are a lot of frameworks that support them, however, it is more tricky to do that, and for that reason, I used integer arithmetic to simplify the tutorial. The function above is just a hack to make it simple. It’s easy to see that we can recover this embedding later without too much loss of precision.
Now we just need to create some sentence samples that we’ll be using:
# The list of Alice sentences
alice_sentences = [
'my cat loves to walk over my keyboard',
'I like to pet my cat',
]
# The list of Bob sentences
bob_sentences = [
'the cat is always walking over my keyboard',
]
And convert them to embeddings:
# Alice sentences
alice_sentence1 = encode(model, alice_sentences[0])
alice_sentence2 = encode(model, alice_sentences[1])
# Bob sentences
bob_sentence1 = encode(model, bob_sentences[0])
Since we have now the sentences and every sentence is also normalized, we can compute cosine similarity just by doing a dot product between the vectors:
As we can see, the first sentence of Bob is most similar (~0.87) with Alice first sentence than to the Alice second sentence (~0.62).
Since we have now the embeddings, we just need to convert them to scaled integers:
# Scale the Alice sentence embeddings
alice_sentence1_scaled = scale(alice_sentence1)
alice_sentence2_scaled = scale(alice_sentence2)
# Scale the Bob sentence embeddings
bob_sentence1_scaled = scale(bob_sentence1)
# This is the unit vector embedding for the sentence
>>> alice_sentence1
array([ 0.01698913, -0.0014404 , 0.0010993 , ..., 0.00252409,
0.00828147, 0.00466533], dtype=float32)
# This is the scaled vector as integers
>>> alice_sentence1_scaled
array([278, 0, 18, ..., 41, 135, 76], dtype=int32)
Now with these embeddings as scaled integers, we can proceed to the second part, where we’ll be doing the secure computation between two parties.
Two-party secure computation
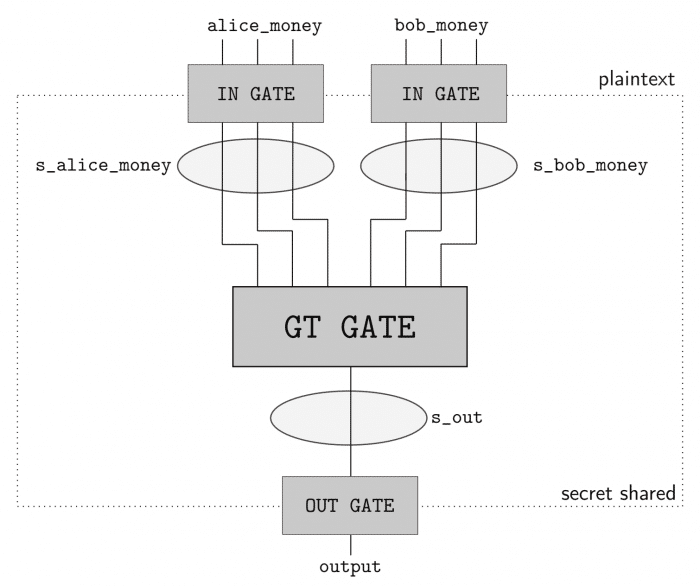
In order to perform secure computation between the two parties (Alice and Bob), we’ll use the ABY framework. ABY implements many difference secure computation schemes and allows you to describe your computation as a circuit like pictured in the image below, where the Yao’s Millionaire’s problem is described:
Yao’s Millionaires problem. Taken from ABY documentation (https://github.com/encryptogroup/ABY).
As you can see, we have two inputs entering in one GT GATE (greater than gate) and then a output. This circuit has a bit length of 3 for each input and will compute if the Alice input is greater than (GT GATE) the Bob input. The computing parties then secret share their private data and then can use arithmetic sharing, boolean sharing, or Yao sharing to securely evaluate these gates.
ABY is really easy to use because you can just describe your inputs, shares, gates and it will do the rest for you such as creating the socket communication channel, exchanging data when needed, etc. However, the implementation is entirely written in C++ and I’m not aware of any Python bindings for it (a great contribution opportunity).
Fortunately, there is an implemented example for ABY that can do dot product calculation for us, the example is here. I won’t replicate the example here, but the only part that we have to change is to read the embedding vectors that we created before instead of generating random vectors and increasing the bit length to 32-bits.
After that, we just need to execute the application on two different machines (or by emulating locally like below):
# This will execute the server part, the -r 0 specifies the role (server)
# and the -n 4096 defines the dimension of the vector (InferSent generates
# 4096-dimensional embeddings).
~# ./innerproduct -r 0 -n 4096
# And the same on another process (or another machine, however for another
# machine execution you'll have to obviously specify the IP).
~# ./innerproduct -r 1 -n 4096
And we get the following results:
Inner Product of alice_sentence1 and bob_sentence1 = 226691917
Inner Product of alice_sentence2 and bob_sentence1 = 171746521
Even in the integer representation, you can see that the inner product of the Alice’s first sentence and the Bob sentence is higher, meaning that the similarity is also higher. But let’s now convert this value back to float:
>>> SCALE = 1 << 14
# This is the dot product we should get
>>> np.dot(alice_sentence1, bob_sentence1)
0.8798542
# This is the inner product we got on secure computation
>>> 226691917 / SCALE**2.0
0.8444931
# This is the dot product we should get
>>> np.dot(alice_sentence2, bob_sentence1)
0.6297632
# This is the inner product we got on secure computation
>>> 171746521 / SCALE**2.0
0.6398056
As you can see, we got very good approximations, even in presence of low-precision math and unsigned integer requirements. Of course that in real-life you won’t have the two values and vectors, because they’re supposed to be hidden, but the changes to accommodate that are trivial, you just need to adjust ABY code to load only the vector of the party that it is executing it and using the correct IP addresses/port of the both parties.
The GIMPS (Great Internet Mersenne Prime Search) has confirmed yesterday the new largest known prime number: 277,232,917-1. This new largest known prime has 23,249,425 digits and is, of course, a Mersenne prime, prime numbers expressed in the form of 2n – 1, where the primality can be efficiently calculated using Lucas-Lehmer primality test.
One of the most asked questions about these largest primes is how the number of digits is calculated, given the size of these numbers (23,249,425 digits for the new largest known prime). And indeed there is a trick that avoids you to evaluate the number to calculate the number of digits, using Python you can just do:
>>> import numpy as np
>>> a = 2
>>> b = 77232917
>>> num_digits = int(1 + b * np.log10(a))
>>> print(num_digits)
23249425
The reason why this works is that the log base 10 of a number is how many times this number should be divided by 10 to get to 1, so you get the number of digits after 1 and just need to add 1 back.
Another interesting fact is that we can also get the last digit of this very large number again without evaluating the entire number by using congruence. Since we’re interested in the number mod 10 and we know that the Mersenne prime has the form of 277,232,917-1, we can check that the powers 2n have an easy cycling pattern:
(… repeat)
Which means that powers of 2 mod 10 repeats at every 4 numbers, thus we just need to compute 77,232,917 mod 4, which is 1. Given that the part 277,232,917 ends in 2 and when you subtract 1 you end up with 1 as the last digit, as you can confirm by looking at the entire number (~10Mb zipfile).
Since Benford’s law got some attention in the past years, I decided to make a list of the previous posts I made on the subject in the context of elections, fraud, corruption, universality and prime numbers:
So, in mathematics, we have the concept of universality in which we have laws like the law of large numbers, the Benford’s law (that I cited a lot in previous posts), the central limit theorem, and many other laws that act like laws of physics for the world of mathematics. These laws are not our inventions, I mean, the concepts are our inventions but the laws per se are universal, they are true no matter where you are on the earth or if you live far away in the universe. And that is why Frank Drake, one of the founders of SETI and also one of the pioneers in the search for extraterrestrial intelligence came with this brilliant idea of using prime numbers (another example of universality) to communicate with distant worlds. The idea that Frank Drake had was the use of prime numbers to hide (not actually hide, but to make self-evident, you’ll understand later) the dimension of a transmitted image in the image size itself.
So, imagine you are receiving a message that is a sequence of dashes and dots like “—.-.—.-.——–…-.—” that repeats after a short pause and then again and again. Let’s suppose that this message has a size of 1679 symbols. So you begin analyzing the number, which is, in fact, a semiprime number (the same used in cryptography, a number that is a product of two prime numbers) that can be factored in prime factors as 23*73=1679, and this is the only way to factor it in prime factors (actually all numbers have only a single set of prime factors that are unique, see Fundamental theorem of arithmetic). So, since there are only two prime factors, you will try to reshape the signal in a 2D image and this image can have the dimension of 23×73 or 73×23, when you arrange the image in one of these dimensions you’ll see that the image makes sense and the other will be just a random and strange sequence. By using prime numbers (or semiprimes) you just used the total image size to define the only two possible ways of arranging the image dimension.
Arecibo Observatory
This idea was actually used in reality in 1974 by the Arecibo radio telescope when a message was broadcast in frequency modulation (FM) aiming the M13 globular star cluster at 25.000 light-years away:
M13 Globular Star Cluster
This message had the size (surprise) of 1679 binary digits and carried a lot of information about your world like a graphical representation of a human, numbers from 1 to 10, a graphical representation of the Arecibo radio telescope, etc.
The message decoded as 23 rows and 73 columns are this:
Arecibo Message Shifted (Source: Wikipedia)
As you can see, the message looks a lot nonsensical, but when it is decoded as an image with 73 rows and 23 columns, it will show its real significance:
Arecibo Message with the correct dimension (Source: Wikipedia)
While playing with mpmpath and it’s Riemann Zeta function evaluator, I came upon those interesting animated plottings using Matplotlib (the source code is in the end of the post).
Riemann zeta function is an analytic function and is defined over the complex plane with one complex variable denoted as ““. Riemann zeta is very important to mathematics due it’s deep relation with primes; the zeta function is given by:
for .
So, let where and .
The first plot uses the triplet coordinates to plot a 3D space where each component is given by:
(or , previously defined);
(or , previously defined);
(or , previously defined);
The time component used in the animation is called and it’s given by or simply .
To plot the animation I’ve used the follow intervals:
For : from , this were calculated at every 0.01 step – shown in the plot at top right;
For : from , calculated at every 0.1 step – shown as the axis.
This plot were done using a fixed interval (no auto scale) for the coordinates. Where () is when the non-trivial zeroes of Riemann Zeta function lies.
Now see the same plot but this time using auto scale (automatically resized coordinates):
Note the auto scaling.
See now from another plotting using a 2D space where each component is given by:
(or , previously defined);
(blue) and (green);
The time component used in the animation is called and it’s given by or simply .
To plot the animation I’ve used the follow intervals:
For : from , this were calculated at every 0.01 step – shown in title of the plot at top;
For : from , calculated at every 0.1 step – shown as the axis.
This plot were done using a fixed interval (no auto scale) for the coordinates. Where () is when the non-trivial zeroes of Riemann Zeta function lies. The first 10 non-trivial zeroes from Riemann Zeta function is shown as a red dot, when the two series, the and cross each other on the red dot at the critical line () is where lies the zeroes of the Zeta Function, note how the real and imaginary part turns away from each other as the increases.
Now see the same plot but this time using auto scale (automatically resized coordinate):
If you are interested in more visualizations of Riemann Zeta function, you’ll like the well-done paper from J. Arias-de-Reyna called “X-Ray of Riemann zeta-function“.
I always liked the way visualization affects the understanding of math functions. Anscombe’s quartet is a clear example of how important visualization is.
The source-code used to create the plot are available here:
This website uses cookies to improve your experience. We'll assume you're ok with this, but you can opt-out if you wish. Cookie settingsACCEPT
Privacy & Cookies Policy
Privacy Overview
This website uses cookies to improve your experience while you navigate through the website. Out of these cookies, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may have an effect on your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.
")
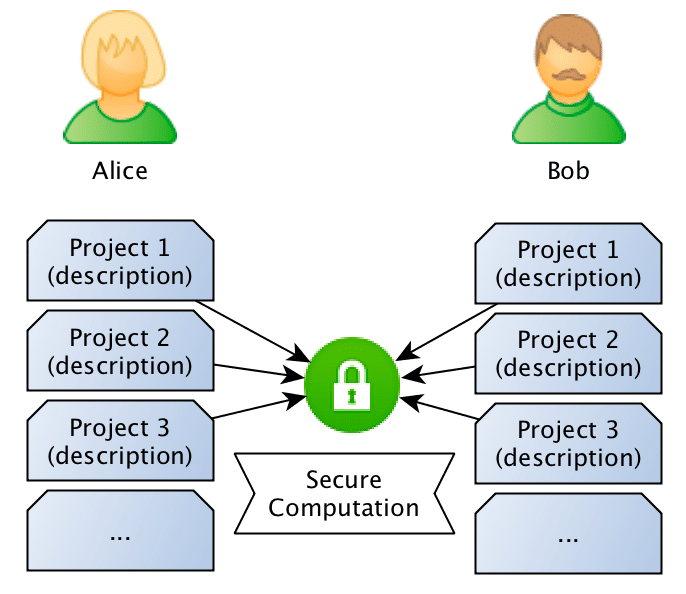 What they want to do is to jointly compute the similarity between projects in order to find if they should be doing partnership on a project or not, however, and this is the important point: Bob doesn’t want Alice to know the project descriptions and neither Alice wants Bob to be aware of their projects, they want to know the closest match between the different projects they run, but without disclosing the project ideas (project descriptions).
What they want to do is to jointly compute the similarity between projects in order to find if they should be doing partnership on a project or not, however, and this is the important point: Bob doesn’t want Alice to know the project descriptions and neither Alice wants Bob to be aware of their projects, they want to know the closest match between the different projects they run, but without disclosing the project ideas (project descriptions).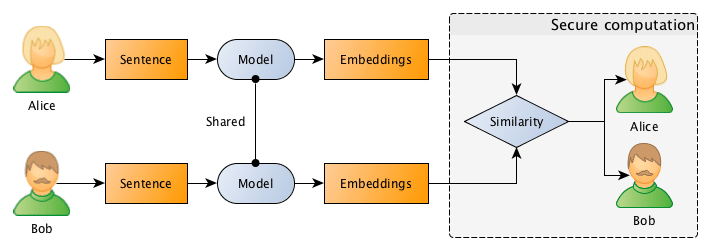
 = \frac {\pmb x \cdot \pmb y}{||\pmb x|| \cdot ||\pmb y||}")
 =\hat{x} \cdot\hat{y}")






 the part 277,232,917 ends in 2 and when you subtract 1 you end up with 1 as the last digit, as you can confirm by looking at the
the part 277,232,917 ends in 2 and when you subtract 1 you end up with 1 as the last digit, as you can confirm by looking at the 


 “. Riemann zeta is very important to mathematics due it’s deep relation with primes; the zeta function is given by:
“. Riemann zeta is very important to mathematics due it’s deep relation with primes; the zeta function is given by: = \sum_{n=1}^\infty \frac{1}{n^s} = \frac{1}{1^s} + \frac{1}{2^s} + \frac{1}{3^s} + \cdots")
 > 1") .
.=v") where
where  and
and  .
.") coordinates to plot a 3D space where each component is given by:
coordinates to plot a 3D space where each component is given by:") (or
(or  , previously defined);
, previously defined);") (or
(or  , previously defined);
, previously defined);") (or
(or  , previously defined);
, previously defined); and it’s given by
and it’s given by ") or simply
or simply  .
.") : from
: from ") , this were calculated at every 0.01 step – shown in the plot at top right;
, this were calculated at every 0.01 step – shown in the plot at top right;") : from
: from ") , calculated at every 0.1 step – shown as the
, calculated at every 0.1 step – shown as the  axis.
axis. = 1/2") (
( ) is when the non-trivial zeroes of Riemann Zeta function lies.
) is when the non-trivial zeroes of Riemann Zeta function lies. coordinates):
coordinates):") auto scaling.
auto scaling.") (or
(or  , previously defined);
, previously defined);") (green);
(green);") , this were calculated at every 0.01 step – shown in title of the plot at top;
, this were calculated at every 0.01 step – shown in title of the plot at top;") , calculated at every 0.1 step – shown as the
, calculated at every 0.1 step – shown as the  axis.
axis.") and
and  coordinate):
coordinate):