Benford’s law emerges from deep language model
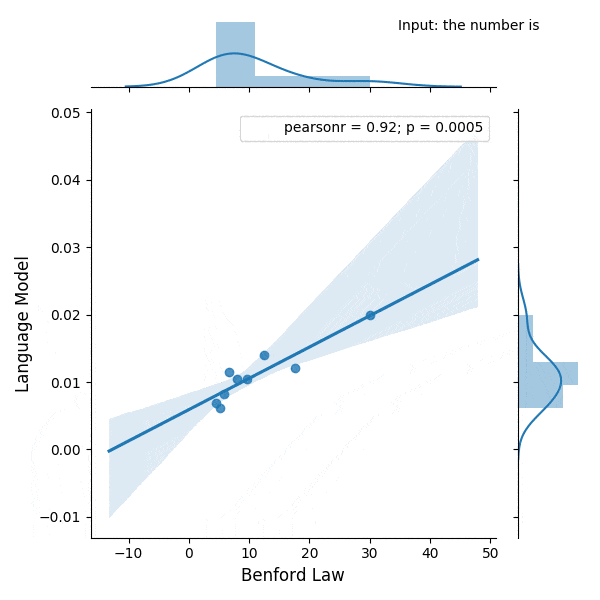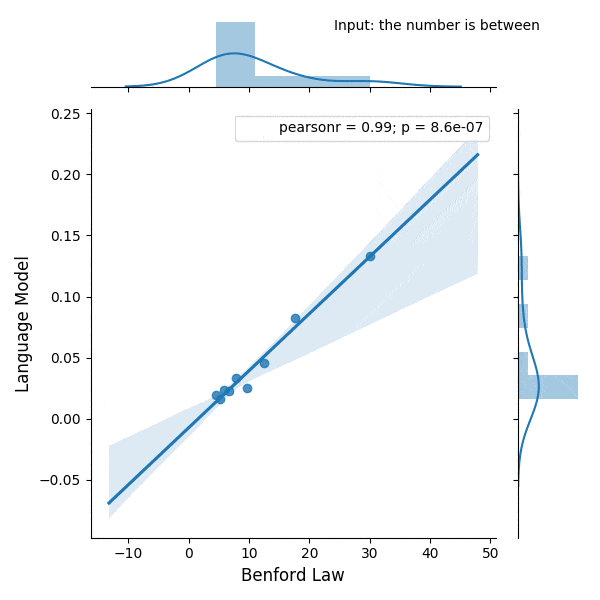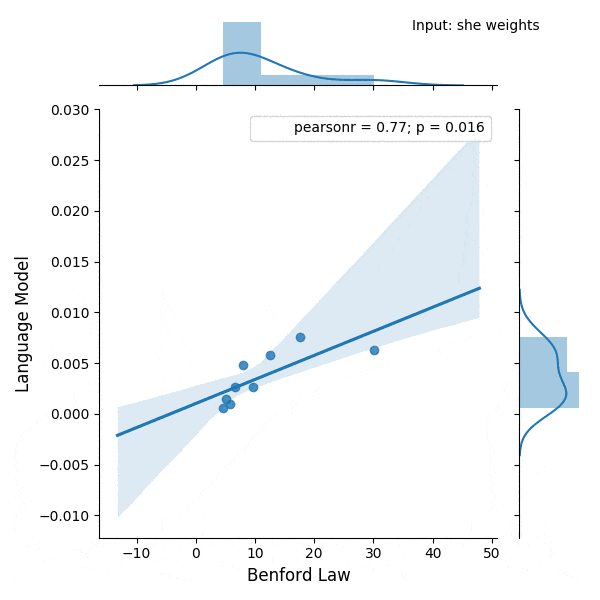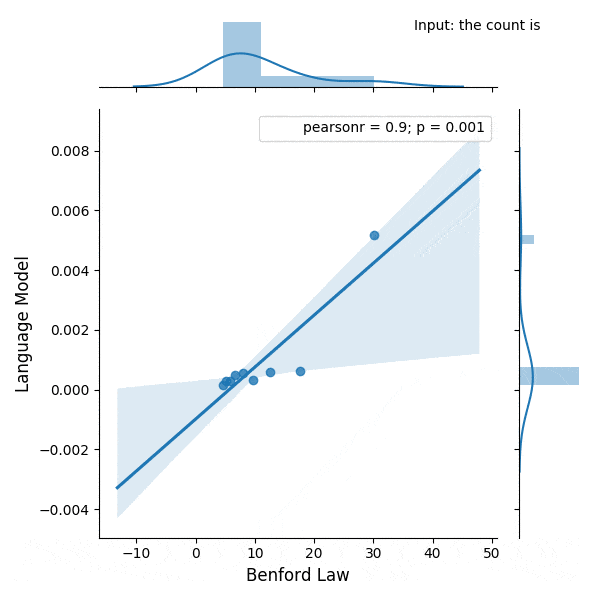
I was experimenting with the digits distribution from a pre-trained (weights from the OpenAI repository) Transformer language model (LM) and I found a very interesting correlation between the Benford’s law and the digit distribution of the language model after conditioning it with some particular phrases.
Below is the correlation between the Benford’s law and the language model with conditioning on the phrase (shown in the figure):