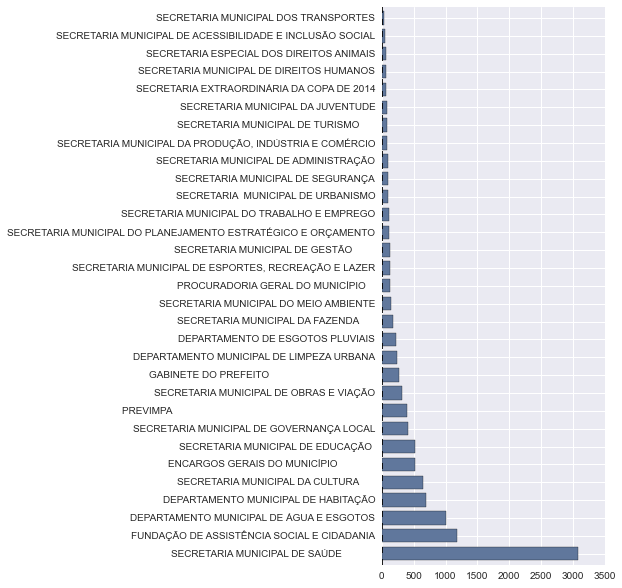
Há poucos dias, a prefeitura de Porto Alegre liberou os datasets com os dados de despesas de custeio de vários órgãos municipais (Secretaria Municipal de Saúde, Secretaria Municipal de Cultura, Gabinete do Prefeito, etc.). O plot abaixo mostra a quantidade de empenhos para cada órgão municipal:
Plot – Qtd Empenhos vs Órgãos
Uma das maneiras utilizadas geralmente para verificar fraudes é o uso da Lei de Benford[1][2][3], que fala sobre a distribuição das frequências de dígitos em vários datasets da vida real, incluindo valores de ações, número de populações, tamanhos de rios, etc.
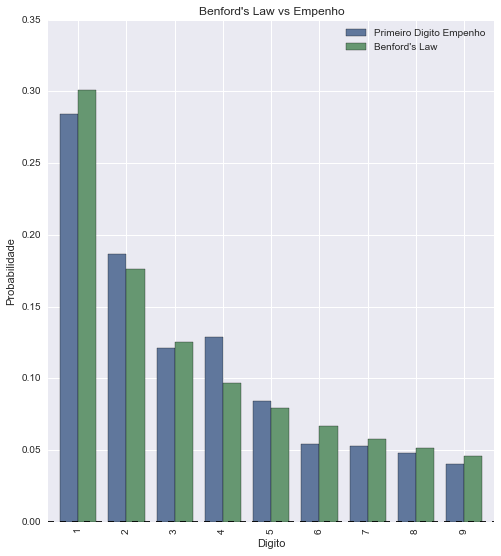
Ao correlacionar a distribuição de números dos primeiros digitos dos valores de empenhos dos dados de Despesas de Custeio do 2º bimestre de 2014 com a distribuição da Lei de Benford, a correlação ficou muito clara:
Lei de Benford vs Despesas de Custeio (Empenho)
Segue aí mais um exemplo de correlação da Lei de Benford. Um sistema legal para ser construído seria um monitor de despesas que verificasse a correlação da Lei de Benford automaticamente e alertasse a cada anomalia encontrada.
So, in mathematics, we have the concept of universality in which we have laws like the law of large numbers, the Benford’s law (that I cited a lot in previous posts), the central limit theorem, and many other laws that act like laws of physics for the world of mathematics. These laws are not our inventions, I mean, the concepts are our inventions but the laws per se are universal, they are true no matter where you are on the earth or if you live far away in the universe. And that is why Frank Drake, one of the founders of SETI and also one of the pioneers in the search for extraterrestrial intelligence came with this brilliant idea of using prime numbers (another example of universality) to communicate with distant worlds. The idea that Frank Drake had was the use of prime numbers to hide (not actually hide, but to make self-evident, you’ll understand later) the dimension of a transmitted image in the image size itself.
So, imagine you are receiving a message that is a sequence of dashes and dots like “—.-.—.-.——–…-.—” that repeats after a short pause and then again and again. Let’s suppose that this message has a size of 1679 symbols. So you begin analyzing the number, which is, in fact, a semiprime number (the same used in cryptography, a number that is a product of two prime numbers) that can be factored in prime factors as 23*73=1679, and this is the only way to factor it in prime factors (actually all numbers have only a single set of prime factors that are unique, see Fundamental theorem of arithmetic). So, since there are only two prime factors, you will try to reshape the signal in a 2D image and this image can have the dimension of 23×73 or 73×23, when you arrange the image in one of these dimensions you’ll see that the image makes sense and the other will be just a random and strange sequence. By using prime numbers (or semiprimes) you just used the total image size to define the only two possible ways of arranging the image dimension.
Arecibo Observatory
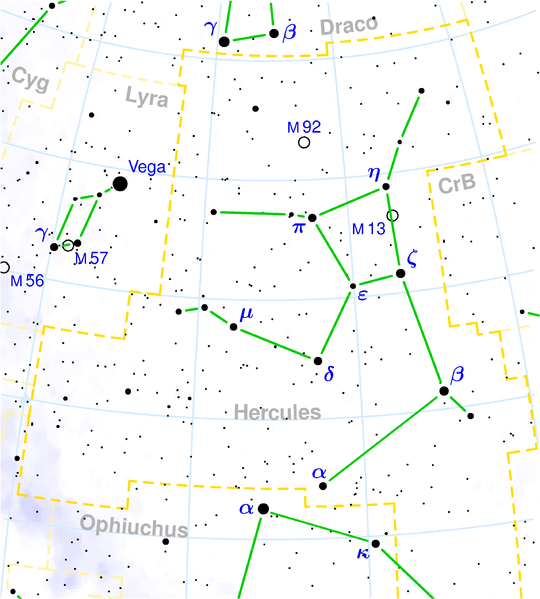
This idea was actually used in reality in 1974 by the Arecibo radio telescope when a message was broadcast in frequency modulation (FM) aiming the M13 globular star cluster at 25.000 light-years away:
M13 Globular Star Cluster
This message had the size (surprise) of 1679 binary digits and carried a lot of information about your world like a graphical representation of a human, numbers from 1 to 10, a graphical representation of the Arecibo radio telescope, etc.
The message decoded as 23 rows and 73 columns are this:
Arecibo Message Shifted (Source: Wikipedia)
As you can see, the message looks a lot nonsensical, but when it is decoded as an image with 73 rows and 23 columns, it will show its real significance:
Arecibo Message with the correct dimension (Source: Wikipedia)
So, in the last days I just released Protocoin, a framework in pure Python with a Bitcoin P2P network implementation. While I’m in process of development of the v.0.2 of the framework (with new and nice features like Bitcoin keys management – you can see some preview here) I would like to show a real-time visualization I’ve made with Protocoin and Ubigraph of a node connecting to a seed node and then issuing GetAddr message for each node and connecting on the received nodes in a breadth-first search fashion. I’ll release the code used to create this visualization in the next release of Protocoin as soon as possible. I hope you enjoy it !
Color legend
Yellow = Connecting Green = Connected Blue = Disconnected after connection
Just release the first version of Protocoin, a pure Python Bitcoin protocol implementation, for more information see the documentation or the project in Github.
If you want to donate for the project, my Bitcoin address is: 1Q6JZEE5turJXaTn1fburWkqjhC4oMJ4yV.
Esta semana será disponibilzada a nova versão do Django GIS Brasil, segue abaixo um exemplo de mapa criado usando os novos dados do Django GIS Brasil importados do DataPoa.
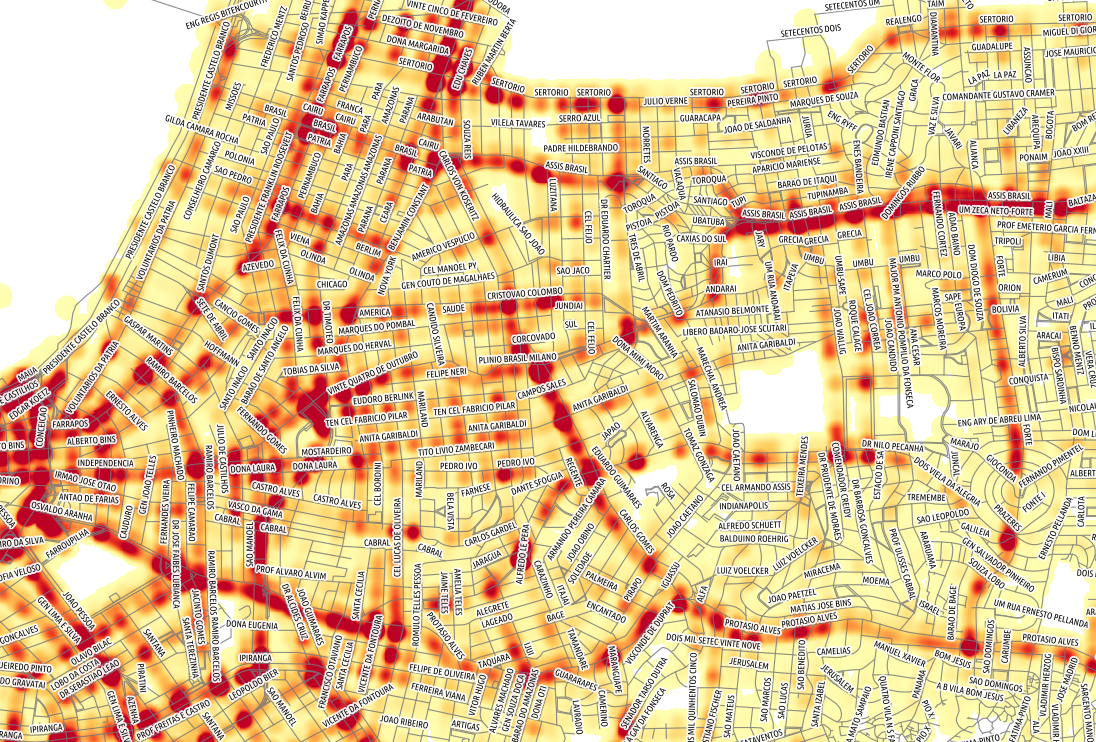
O exemplo abaixo é um mapa de calor utilizando os dados de acidentes de trânsito em Porto Alegre /RS durante os anos de 2000 até 2012. Os eixos (ruas, avenidas, etc.) também estarão presentes no Django GIS Brasil.
Mapa de Acidentes de Trânsito em PoA/RS. Clique para ampliar.
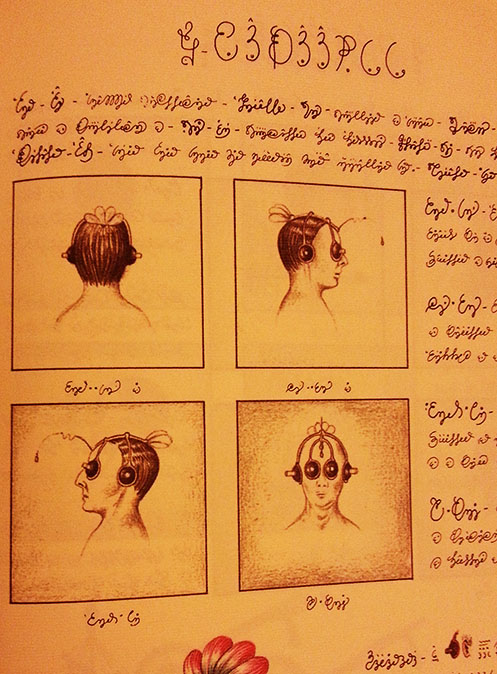
Today the Codex Seraphinianus just arrived (after months waiting in the pre-order state). I bought it from Amazon and I really recommend this edition for those who are interested because this is a very large edition with high quality textured paper and beautiful printing style. The book has also in the end a pocket with a small brochure called “Decodex” with a letter from Luigi Serafini.
The book is a very impressive creation by Luigi Serafini (or by the cat) dating from 1981 and presenting an impossible world that will cause to you the most strange feelings. See the photo of the cover and some pages below.
* It has been a long time since I wrote the TF-IDF tutorial (Part I and Part II) and as I promissed, here is the continuation of the tutorial. Unfortunately I had no time to fix the previous tutorials for the newer versions of the scikit-learn (sklearn) package nor to answer all the questions, but I hope to do that in a close future.
So, on the previous tutorials we learned how a document can be modeled in the Vector Space, how the TF-IDF transformation works and how the TF-IDF is calculated, now what we are going to learn is how to use a well-known similarity measure (Cosine Similarity) to calculate the similarity between different documents.
The Dot Product
Let’s begin with the definition of the dot product for two vectors: and , where and are the components of the vector (features of the document, or TF-IDF values for each word of the document in our example) and the is the dimension of the vectors:
As you can see, the definition of the dot product is a simple multiplication of each component from the both vectors added together. See an example of a dot product for two vectors with 2 dimensions each (2D):
The first thing you probably noticed is that the result of a dot product between two vectors isn’t another vector but a single value, a scalar.
This is all very simple and easy to understand, but what is a dot product ? What is the intuitive idea behind it ? What does it mean to have a dot product of zero ? To understand it, we need to understand what is the geometric definition of the dot product:
Rearranging the equation to understand it better using the commutative property, we have:
So, what is the term ? This term is the projection of the vector into the vector as shown on the image below:
The projection of the vector A into the vector B. By Wikipedia.
Now, what happens when the vector is orthogonal (with an angle of 90 degrees) to the vector like on the image below ?
Two orthogonal vectors (with 90 degrees angle).
There will be no adjacent side on the triangle, it will be equivalent to zero, the term will be zero and the resulting multiplication with the magnitude of the vector will also be zero. Now you know that, when the dot product between two different vectors is zero, they are orthogonal to each other (they have an angle of 90 degrees), this is a very neat way to check the orthogonality of different vectors. It is also important to note that we are using 2D examples, but the most amazing fact about it is that we can also calculate angles and similarity between vectors in higher dimensional spaces, and that is why math let us see far than the obvious even when we can’t visualize or imagine what is the angle between two vectors with twelve dimensions for instance.
The Cosine Similarity
The cosine similarity between two vectors (or two documents on the Vector Space) is a measure that calculates the cosine of the angle between them. This metric is a measurement of orientation and not magnitude, it can be seen as a comparison between documents on a normalized space because we’re not taking into the consideration only the magnitude of each word count (tf-idf) of each document, but the angle between the documents. What we have to do to build the cosine similarity equation is to solve the equation of the dot product for the :
And that is it, this is the cosine similarity formula. Cosine Similarity will generate a metric that says how related are two documents by looking at the angle instead of magnitude, like in the examples below:
The Cosine Similarity values for different documents, 1 (same direction), 0 (90 deg.), -1 (opposite directions).
Note that even if we had a vector pointing to a point far from another vector, they still could have an small angle and that is the central point on the use of Cosine Similarity, the measurement tends to ignore the higher term count on documents. Suppose we have a document with the word “sky” appearing 200 times and another document with the word “sky” appearing 50, the Euclidean distance between them will be higher but the angle will still be small because they are pointing to the same direction, which is what matters when we are comparing documents.
Now that we have a Vector Space Model of documents (like on the image below) modeled as vectors (with TF-IDF counts) and also have a formula to calculate the similarity between different documents in this space, let’s see now how we do it in practice using scikit-learn (sklearn).
Vector Space Model
Practice Using Scikit-learn (sklearn)
* In this tutorial I’m using the Python 2.7.5 and Scikit-learn 0.14.1.
The first thing we need to do is to define our set of example documents:
documents = (
"The sky is blue",
"The sun is bright",
"The sun in the sky is bright",
"We can see the shining sun, the bright sun"
)
And then we instantiate the Sklearn TF-IDF Vectorizer and transform our documents into the TF-IDF matrix:
Now we have the TF-IDF matrix (tfidf_matrix) for each document (the number of rows of the matrix) with 11 tf-idf terms (the number of columns from the matrix), we can calculate the Cosine Similarity between the first document (“The sky is blue”) with each of the other documents of the set:
The tfidf_matrix[0:1] is the Scipy operation to get the first row of the sparse matrix and the resulting array is the Cosine Similarity between the first document with all documents in the set. Note that the first value of the array is 1.0 because it is the Cosine Similarity between the first document with itself. Also note that due to the presence of similar words on the third document (“The sun in the sky is bright”), it achieved a better score.
If you want, you can also solve the Cosine Similarity for the angle between vectors:
We only need to isolate the angle () and move the to the right hand of the equation:
The is the same as the inverse of the cosine ().
Lets for instance, check the angle between the first and third documents:
import math
# This was already calculated on the previous step, so we just use the value
cos_sim = 0.52305744
angle_in_radians = math.acos(cos_sim)
print math.degrees(angle_in_radians)
58.462437107432784
And that angle of ~58.5 is the angle between the first and the third document of our document set.
That is it, I hope you liked this third tutorial !
SDR é uma área de radiocomunicação baseada em uma ideia muito simples: implementar em software o que antes era implementado em hardware (ex: mod/demod, filtros, etc). O fato do SDR estar se tornando uma tendência hoje se dá principalmente pelo baixo custo de alguns receptores como por exemplo o RTL2832U (mais sobre ele depois) que hoje você pode encontrar facilmente por uns U$ 20.00, preço este muito barato se você levar em consideração o intervalo de cobertura das frequências de 22Mhz até 2200Mhz (dependendo do tuner). Neste intervalo dá pra se ter uma ampla cobertura de sinais de rádio AM/FM, rádio da polícia, TV, GSM, GPS, ADSB (este post é sobre o ADSB), comunicação marítma, LTE (ainda em definição no Brasil) e outras aplicações que estão inseridas neste intervalo de frequência.
Um sistema SDR é composto geralmente por: um receptor ligado ao computador ou qualquer outro dispositivo embarcado com um poder de processamento razoável (por meio de placa de captura de áudio, USB, etc) e um software que irá fazer o tratamento do sinal recebido. Neste post eu vou utilizar o Raspberry Pi como dispositivo embarcado para capturar e demodular os dados enviados pelos transponders presentes em aeronaves comerciais e domésticas.
Grande parte dos aviões modernos estão sendo equipados com um dispositivo que tem o objetivo de substituir os radares que existem hoje. Até o ano de 2020 todos os aviões que entrarem no espaço aéreo estadunidense deverão ter como item obrigatório um dispositivo compatível com ADS-B. O dispositivo ADS-B faz com que as aeronaves sejam visíveis aos radares em terra e também para outros aviões através do broadcast de mensagens com sua altura, velocidade, posição e muitas outras informações relevantes. A transmissão destas mensagens se dá através da frequência 1090Mhz, uma frequência dentro do intervalo de captura de maioria dos receptores SDR usando o chipset RTL2832U. A ideia deste post é usar o Raspberry Pi para receber este broadcast enviado diretamente pelo transponder dos aviões, demodular os frames e então utilizar um software para decodificar/interpretar os frames e plotar em um mapa a posição atual dos aviões em Porto Alegre / RS.
Realtek RTL2832U
Alguns receptores de TV digital USB utilizam o chipset da Realtek RTL2832U, como este meu acima. Em 2012 foi descoberto que este chipset permitia o envio de dados brutos do receptor para o host, permitindo assim seu uso para SDR. Existem alguns projetos com drivers para se comunicar com o dispositivo e receber estes dados (Linux e Windows), entre os quais o mais utilizado em Linux é o projeto rtl-sdr, que agrega além do driver alguns utilitários de linha de comando como por exemplo o “rtl_adsb” que utilizarei no Raspberry Pi para demodular o sinal ADS-B enviado pelas aeronaves; outro componente importante nos receptores USB é o tuner, que é responsável pelo ajuste da frequencia do rádio, no caso do meu dongle USB ele é o R820T que tem uma ótima sensibilidade mas tem um intervalo menor de cobertura do espectro quando comparado ao E4000 (da Elonics), veja a tabela no site do projeto para saber o intervalo de cobertura de cada tuner e de outros hardwares suportados pelo rtl-sdr.
Compilando o rtl-sdr no Raspberry Pi
Estou utilizando o Raspberry Pi como host do dongle USB porque ele é um aparelho barato e o consumo de energia é muito baixo, ou seja, você pode deixá-lo ligado capturando o sinal ADS-B por quanto tempo quiser sem se preocupar com um gasto maior que 5 watts no pior caso.
cd rtl-sdr/
mkdir build
cd build
cmake ../
make
sudo make install
sudo ldconfig
E pronto, já estamos com o rtl-sdr instalado (driver a aplicativos extras).
Recebendo sinal ADS-B
Antes de mais nada, um pequeno teste para verificar se o rtl-sdr está encontrando corretamente o dongle USB:
pi@raspberrypi ~ $ rtl_test -t
Found 1 device(s):
0: ezcap USB 2.0 DVB-T/DAB/FM dongle
Using device 0: ezcap USB 2.0 DVB-T/DAB/FM dongle
Found Rafael Micro R820T tuner
Supported gain values (29): 0.0 0.9 1.4 2.7 3.7 7.7
8.7 12.5 14.4 15.7 16.6 19.7 20.7 22.9 25.4 28.0
29.7 32.8 33.8 36.4 37.2 38.6 40.2 42.1 43.4 43.9
44.5 48.0 49.6
No E4000 tuner found, aborting.
pi@raspberrypi ~ $
Note que o meu dongle é um RTL2832U com o tuner R820T, ao executar o “rtl_test -t” é também exibida uma lista com os ganhos suportados pelo dongle.
Como a frequência utilizada pelo ADS-B é de 1090MHz, uma antena boa seria uma discone ou uma dipolo confeccionada com as dimensões corretas para esta frequência. Como ainda não tenho os plugs adequados tive que utiliar a antena que veio junto com o dongle, que mesmo sendo de baixa qualidade e não relacionada com a frequência do ADS-B ainda consegue receber os sinais (de fato, mesmo desconectando a antena eu consigo receber os frames das aeronaves), mesmo com o dongle em um ambiente fechado (minha casa fica há uns 6-10km do aeroporto de Porto Alegre / RS).
Para receber e demodular os frames eu utilizei o utilitário “rtl_adsb” (ele vem junto com o pacote do rtl-sdr). Ao ser executado, ele ajustará o tuner para a frequência do transponder das aeronaves em 1090MHz e logo após fará a demodulação dos frames para o formato hexadecimal:
pi@raspberrypi ~ $ rtl_adsb
Found 1 device(s):
0: Realtek, RTL2838UHIDIR, SN: 00000013
Using device 0: ezcap USB 2.0 DVB-T/DAB/FM dongle
Found Rafael Micro R820T tuner
Tuner gain set to automatic.
Tuned to 1090000000 Hz.
Sampling at 2000000 Hz.
Exact sample rate is: 2000000.052982 Hz
*825566cf477b3124c64b17e74b15;
*e6c7d7fdb34c855db6972204ea14;
*d1e27bb95df2454ca547c87718a2;
*906bc5a59b5c5053226fb94f3460;
*a6f51dc76353efeeabfbfe6946cb;
*e78ed3aaf547fcd87e8e4f41cea3;
*d26a5ecacdb7051f2ebe18efc613;
Cada frame inicia sempre com um asterisco na frente e cada um destes frames foi enviado diretamente por um transponder de um avião ou é uma requisição terra->ar de alguma base em terra. O que precisamos agora é fazer a decodificação destes frames para poder extrair o tipo do frame, latitude, longitude, callsign, origem e destino do avião, etc. Não existem hoje muitas alternativas open-source para fazer o plot dos aviões em um mapa, o melhor que eu encontrei foi o Virtual Radar Server que é open-source e roda também em Linux, além de ter uma interface web bem amigável e plotar as aeronaves usando o Google Maps.
Para fazer com que o Virtual Radar Server conecte no Raspberry Pi, primeiramente precisamos fazer o streaming via TCP dos frames que o “rtl_adsb” está recebendo no Raspberry Pi, o que dá para resolver utilizando o “netcat” mesmo:
rtl_adsb | netcat -lp 8080
Neste caso ele irá escutar na porta 8080 e enviar os frames ADS-B para o cliente que conectar nele. Logo após é só especificar o IP/porta do Raspberry Pi no Virtual Radar Server e se tudo der certo e você conseguir receber algum frame de algum transponder, você verá uma tela parecida com esta mostrada abaixo com o rastreamento dos aviões em tempo real:
No screenshot você pode ver um avião da GOL (GOL1446) se dirigindo ao aeroporto (logo a frente onde diz São João) a uma velocidade de 250km/h e descendo a uma velocidade de 195 metros por minuto. Geralmente os aviões enviam o broadcast da mensagem com a posição a cada segundo, tudo vai depender da sua antena, receptor e condições de difusão. Com a minha antena pequena e no meio de prédios eu consegui capturar o broadcast de aviõe em até uns 80km de distância, espero melhorar isto com uma outra antena, só preciso achar o material agora =)
This website uses cookies to improve your experience. We'll assume you're ok with this, but you can opt-out if you wish. Cookie settingsACCEPT
Privacy & Cookies Policy
Privacy Overview
This website uses cookies to improve your experience while you navigate through the website. Out of these cookies, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may have an effect on your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.




") and
and ") , where
, where  and
and  are the components of the vector (features of the document, or TF-IDF values for each word of the document in our example) and the
are the components of the vector (features of the document, or TF-IDF values for each word of the document in our example) and the  is the dimension of the vectors:
is the dimension of the vectors:
 \\ \vec{b} = (4, 0) \\ \vec{a} \cdot \vec{b} = 0*4 + 3*0 = 0")


 ? This term is the projection of the vector
? This term is the projection of the vector  into the vector
into the vector  as shown on the image below:
as shown on the image below:

 :
:



 ) and move the
) and move the  to the right hand of the equation:
to the right hand of the equation:
 is the same as the inverse of the cosine (
is the same as the inverse of the cosine ( ).
).


