É muito triste ver as enchentes devastadoras que tem atingido o Rio Grande do Sul nos últimos anos. Decidi fazer este post pra tentar compreender melhor a escala e o impacto desses eventos usando algumas fotos de satélite e dados recentes sobre as enchentes. Maioria das imagens recentes são do MODIS (Moderate Resolution Imaging Spectroradiometer) do qual fiz um post em 2009 (artigo aqui) que usam 2 satélites (Terra e Aqua) para fazer cobertura quase diária em baixa resolução da terra inteira.
Estamos no meio de uma tragédia sem precedentes, por outro lado, este é um momento único para a coleta de dados por parte de pesquisadores e governo com a esperança de melhorar a modelagem desses processos hidrológicos para desenvolver sistemas de alerta e previsão de enchentes. Nunca antes observamos estes processos complexos nos rios do Rio Grande do Sul, este momento é extremamente importante para o futuro do RS.
PS: tentarei manter atualizado este post com novas imagens.
Avisos de licença das imagens:
Sentinel images: contains modified Copernicus Sentinel data 2024 processed by Sentinel Hub.
MODIS (Aqua/Terra): NASA/OB.DAAC.

 , where the sum of all elements of the vector must equal 1. Softmax is used a lot in classification and I thought it would be interesting to visualize (when possible, on lower dimensions) the trajectories of individual samples in that simplex as predicted by the network while the network is being trained.
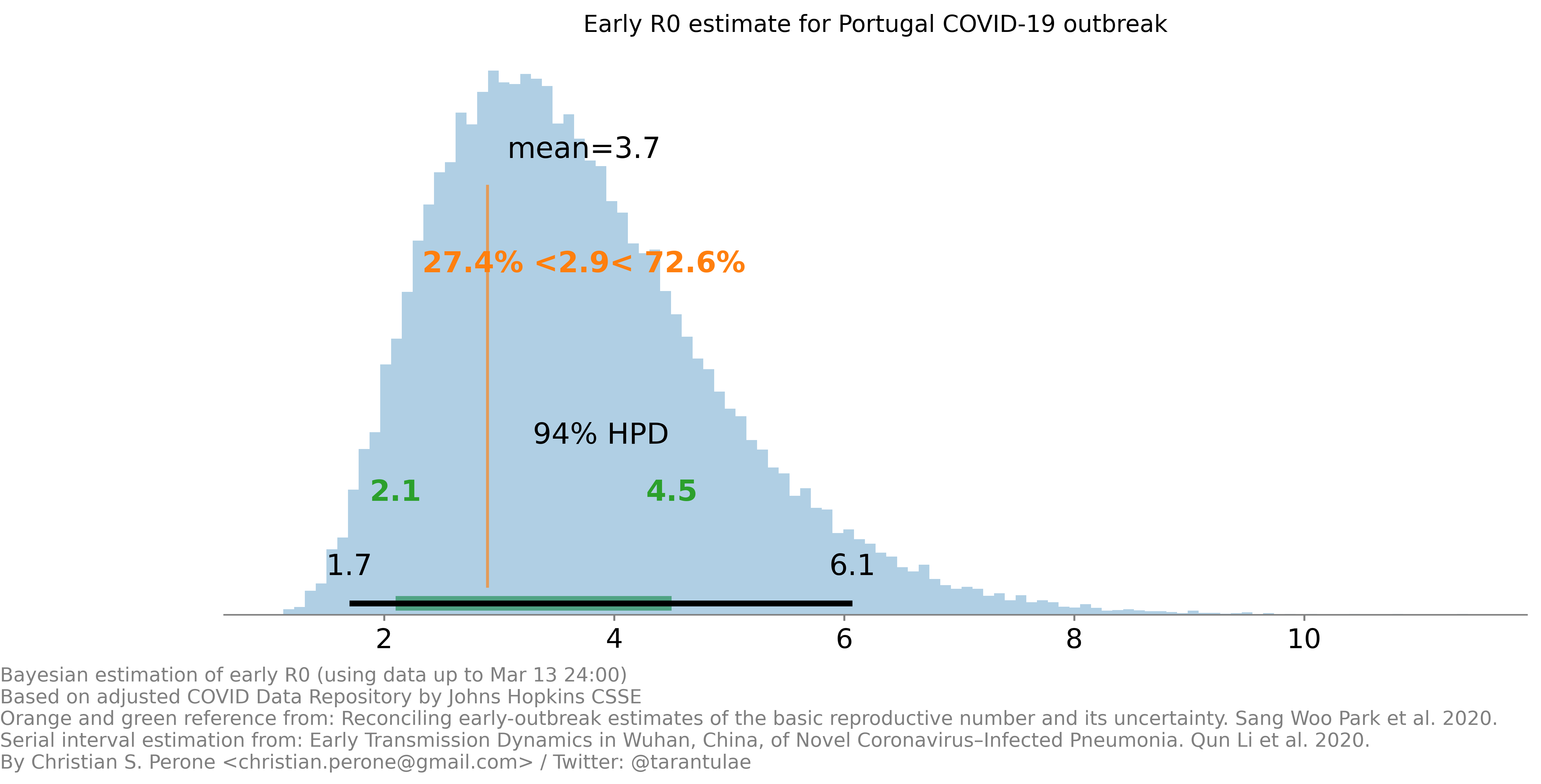
, where the sum of all elements of the vector must equal 1. Softmax is used a lot in classification and I thought it would be interesting to visualize (when possible, on lower dimensions) the trajectories of individual samples in that simplex as predicted by the network while the network is being trained. (basic reproduction number) in Portugal outbreak. Details on the image, more information to come soon. This estimate is taking into consideration the uncertainty for the generation interval and the growth.
(basic reproduction number) in Portugal outbreak. Details on the image, more information to come soon. This estimate is taking into consideration the uncertainty for the generation interval and the growth.