Update – 05 Dec 2017: Google just announced that it will be commited to the development of a new released version of the S2 library, amazing news, repository can be found here.
Google’s S2 library is a real treasure, not only due to its capabilities for spatial indexing but also because it is a library that was released more than 4 years ago and it didn’t get the attention it deserved. The S2 library is used by Google itself on Google Maps, MongoDB engine and also by Foursquare, but you’re not going to find any documentation or articles about the library anywhere except for a paper by Foursquare, a Google presentation and the source code comments. You’ll also struggle to find bindings for the library, the official repository has missing Swig files for the Python library and thanks to some forks we can have a partial binding for the Python language (I’m going to it use for this post). I heard that Google is actively working on the library right now and we are probably soon going to get more details about it when they release this work, but I decided to share some examples about the library and the reasons why I think that this library is so cool.
The way to the cells
You’ll see this “cell” concept all around the S2 code. The cells are an hierarchical decomposition of the sphere (the Earth on our case, but you’re not limited to it) into compact representations of regions or points. Regions can also be approximated using these same cells, that have some nice features:
- They are compact (represented by 64-bit integers)
- They have resolution for geographical features
- They are hierarchical (thay have levels, and similar levels have similar areas)
- The containment query for arbitrary regions are really fast
The S2 library starts by projecting the points/regions of the sphere into a cube, and each face of the cube has a quad-tree where the sphere point is projected into. After that, some transformation occurs (for more details on why, see the Google presentation) and the space is discretized, after that the cells are enumerated on a Hilbert Curve, and this is why this library is so nice, the Hilbert curve is a space-filling curve that converts multiple dimensions into one dimension that has an special spatial feature: it preserves the locality.
Hilbert Curve

The Hilbert curve is space-filling curve, which means that its range covers the entire n-dimensional space. To understand how this works, you can imagine a long string that is arranged on the space in a special way such that the string passes through each square of the space, thus filling the entire space. To convert a 2D point along to the Hilbert curve, you just need select the point on the string where the point is located. An easy way to understand it is to use this iterative example where you can click on any point of the curve and it will show where in the string the point is located and vice-versa.
In the image below, the point in the very beggining of the Hilbert curve (the string) is located also in the very beginning along curve (the curve is represented by a long string in the bottom of the image):
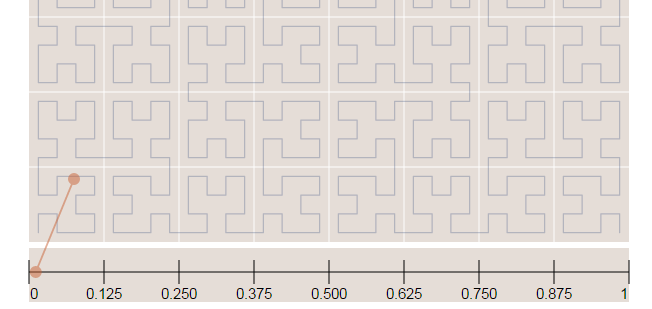
Now in the image below where we have more points, it is easy to see how the Hilbert curve is preserving the spatial locality. You can note that points closer to each other in the curve (in the 1D representation, the line in the bottom) are also closer in the 2D dimensional space (in the x,y plane). However, note that the opposite isn’t quite true because you can have 2D points that are close to each other in the x,y plane that aren’t close in the Hilbert curve.
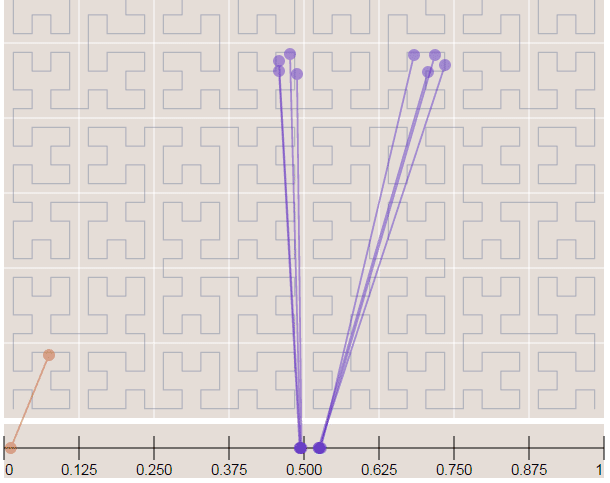
Since S2 uses the Hilbert Curve to enumerate the cells, this means that cell values close in value are also spatially close to each other. When this idea is combined with the hierarchical decomposition, you have a very fast framework for indexing and for query operations. Before we start with the pratical examples, let’s see how the cells are represented in 64-bit integers.
If you are interested in Hilbert Curves, I really recommend this article, it is very intuitive and show some properties of the curve.
The cell representation
As I already mentioned, the cells have different levels and different regions that they can cover. In the S2 library you’ll find 30 levels of hierachical decomposition. The cell level and the area range that they can cover is shown in the Google presentation in the slide that I’m reproducing below:
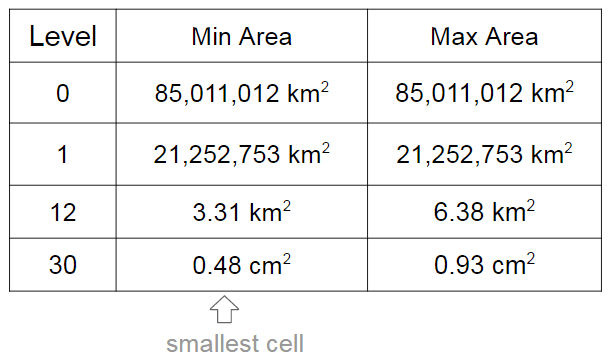
As you can see, a very cool result of the S2 geometry is that every cm² of the earth can be represented using a 64-bit integer.
The cells are represented using the following schema:
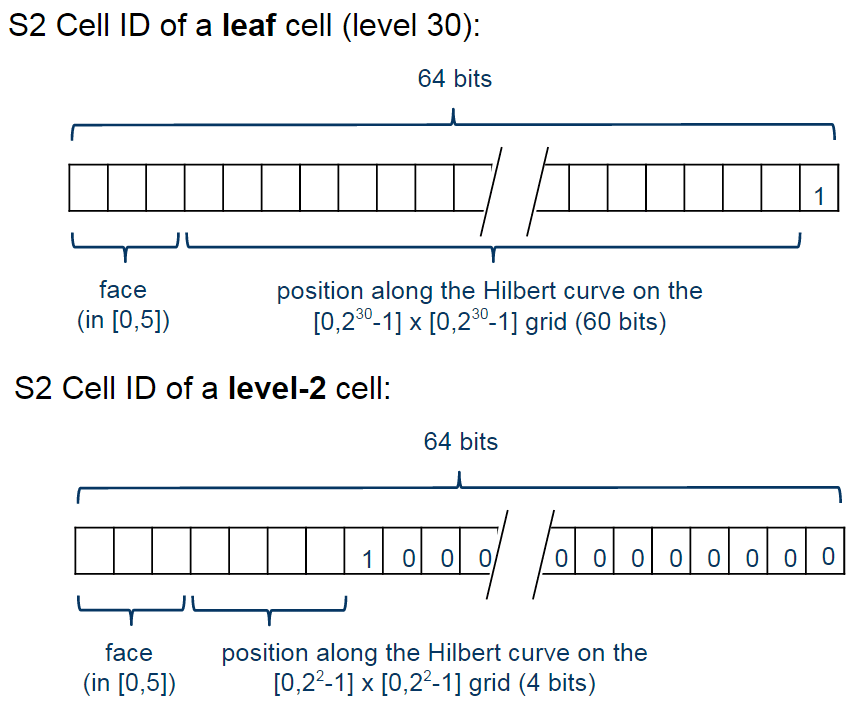
The first one is representing a leaf cell, a cell with the minimum area usually used to represent points. As you can see, the 3 initial bits are reserved to store the face of the cube where the point of the sphere was projected, then it is followed by the position of the cell in the Hilbert curve always followed by a “1” bit that is a marker that will identify the level of the cell.
So, to check the level of the cell, all that is required is to check where the last “1” bit is located in the cell representation. The checking of containment, to verify if a cell is contained in another cell, all you just have to do is to do a prefix comparison. These operations are really fast and they are possible only due to the Hilbert Curve enumeration and the hierarchical decomposition method used.
Covering regions
So, if you want to generate cells to cover a region, you can use a method of the library where you specify the maximum number of the cells, the maximum cell level and the minimum cell level to be used and an algorithm will then approximate this region using the specified parameters. In the example below, I’m using the S2 library to extract some Machine Learning binary features using level 15 cells:
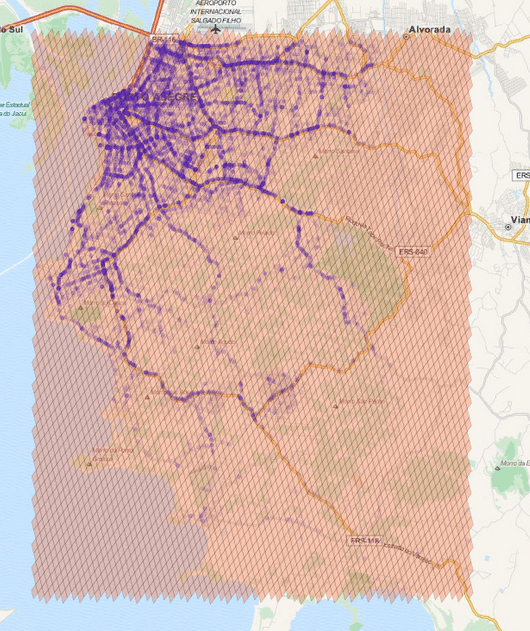
The cells regions are here represented in the image above using transparent polygons over the entire region of interest of my city. Since I used the level 15 both for minimum and maximum level, the cells are all covering similar region areas. If I change the minimum level to 8 (thus allowing the possibility of using larger cells), the algorithm will approximate the region in a way that it will provide the smaller number of cells and also trying to keep the approximation precise like in the example below:
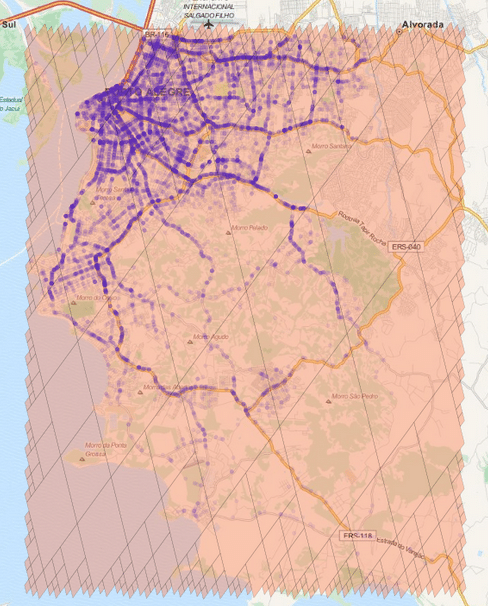
As you can see, we have now a covering using larger cells in the center and to cope with the borders we have an approximation using smaller cells (also note the quad-trees).
Examples
* In this tutorial I used the Python 2.7 bindings from the following repository. The instructions to compile and install it are present in the readme of the repository so I won’t repeat it here.
The first step to convert Latitude/Longitude points to the cell representation are shown below:
>>> import s2 >>> latlng = s2.S2LatLng.FromDegrees(-30.043800, -51.140220) >>> cell = s2.S2CellId.FromLatLng(latlng) >>> cell.level() 30 >>> cell.id() 10743750136202470315 >>> cell.ToToken() 951977d377e723ab
As you can see, we first create an object of the class S2LatLng to represent the lat/lng point and then we feed it into the S2CellId class to build the cell representation. After that, we can get the level and id of the class. There is also a method called ToToken that converts the integer representation to a compact alphanumerical representation that you can parse it later using FromToken method.
You can also get the parent cell of that cell (one level above it) and use containment methods to check if a cell is contained by another cell:
>>> parent = cell.parent() >>> print parent.level() 29 >>> parent.id() 10743750136202470316 >>> parent.ToToken() 951977d377e723ac >>> cell.contains(parent) False >>> parent.contains(cell) True
As you can see, the level of the parent is one above the children cell (in our case, a leaf cell). The ids are also very similar except for the level of the cell and the containment checking is really fast (it is only checking the range of the children cells of the parent cell).
These cells can be stored on a database and they will perform quite well on a BTree index. In order to create a collection of cells that will cover a region, you can use the S2RegionCoverer class like in the example below:
>>> region_rect = S2LatLngRect(
S2LatLng.FromDegrees(-51.264871, -30.241701),
S2LatLng.FromDegrees(-51.04618, -30.000003))
>>> coverer = S2RegionCoverer()
>>> coverer.set_min_level(8)
>>> coverer.set_max_level(15)
>>> coverer.set_max_cells(500)
>>> covering = coverer.GetCovering(region_rect)
First of all, we defined a S2LatLngRect which is a rectangle delimiting the region that we want to cover. There are also other classes that you can use (to build polygons for instance), the S2RegionCoverer works with classes that uses the S2Region class as base class. After defining the rectangle, we instantiate the S2RegionCoverer and then set the aforementioned min/max levels and the max number of the cells that we want the approximation to generate.
If you wish to plot the covering, you can use Cartopy, Shapely and matplotlib, like in the example below:
import matplotlib.pyplot as plt
from s2 import *
from shapely.geometry import Polygon
import cartopy.crs as ccrs
import cartopy.io.img_tiles as cimgt
proj = cimgt.MapQuestOSM()
plt.figure(figsize=(20,20), dpi=200)
ax = plt.axes(projection=proj.crs)
ax.add_image(proj, 12)
ax.set_extent([-51.411886, -50.922470,
-30.301314, -29.94364])
region_rect = S2LatLngRect(
S2LatLng.FromDegrees(-51.264871, -30.241701),
S2LatLng.FromDegrees(-51.04618, -30.000003))
coverer = S2RegionCoverer()
coverer.set_min_level(8)
coverer.set_max_level(15)
coverer.set_max_cells(500)
covering = coverer.GetCovering(region_rect)
geoms = []
for cellid in covering:
new_cell = S2Cell(cellid)
vertices = []
for i in xrange(0, 4):
vertex = new_cell.GetVertex(i)
latlng = S2LatLng(vertex)
vertices.append((latlng.lat().degrees(),
latlng.lng().degrees()))
geo = Polygon(vertices)
geoms.append(geo)
print "Total Geometries: {}".format(len(geoms))
ax.add_geometries(geoms, ccrs.PlateCarree(), facecolor='coral',
edgecolor='black', alpha=0.4)
plt.show()
And the result will be the one below:
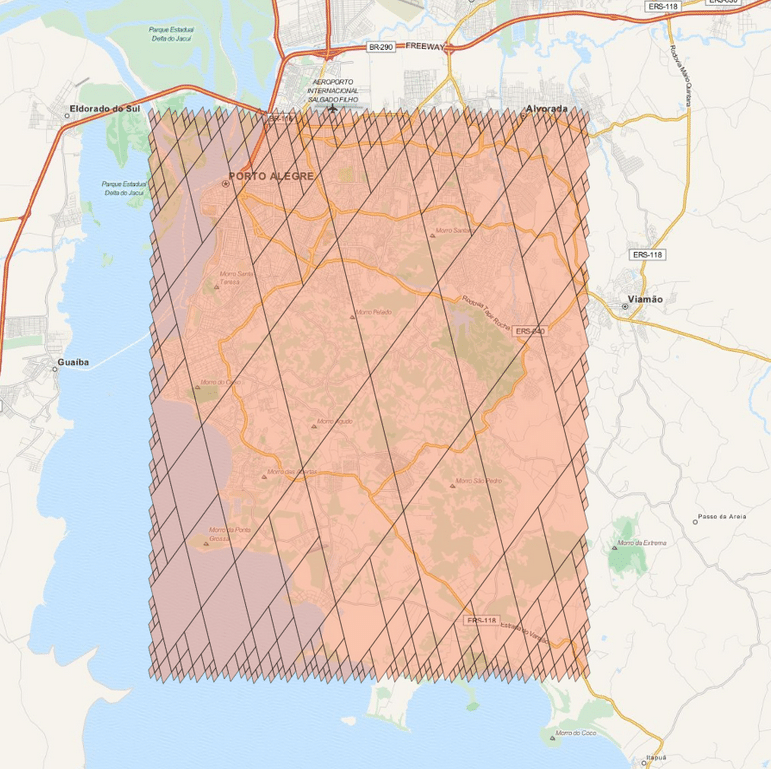
There are a lot of stuff in the S2 API, and I really recommend you to explore and read the source-code, it is really helpful. The S2 cells can be used for indexing and in key-value databases, it can be used on B Trees with really good efficiency and also even for Machine Learning purposes (which is my case), anyway, it is a very useful tool that you should keep in your toolbox. I hope you enjoyed this little tutorial !
– Christian S. Perone
