If you are following some Machine Learning news, you certainly saw the work done by Ryan Dahl on Automatic Colorization (Hacker News comments, Reddit comments). This amazing work uses pixel hypercolumn information extracted from the VGG-16 network in order to colorize images. Samim also used the network to process Black & White video frames and produced the amazing video below:
https://www.youtube.com/watch?v=_MJU8VK2PI4
Colorizing Black&White Movies with Neural Networks (video by Samim, network by Ryan)
But how does this hypercolumns works ? How to extract them to use on such variety of pixel classification problems ? The main idea of this post is to use the VGG-16 pre-trained network together with Keras and Scikit-Learn in order to extract the pixel hypercolumns and take a superficial look at the information present on it. I’m writing this because I haven’t found anything in Python to do that and this may be really useful for others working on pixel classification, segmentation, etc.
Hypercolumns
Many algorithms using features from CNNs (Convolutional Neural Networks) usually use the last FC (fully-connected) layer features in order to extract information about certain input. However, the information in the last FC layer may be too coarse spatially to allow precise localization (due to sequences of maxpooling, etc.), on the other side, the first layers may be spatially precise but will lack semantic information. To get the best of both worlds, the authors of the hypercolumn paper define the hypercolumn of a pixel as the vector of activations of all CNN units “above” that pixel.
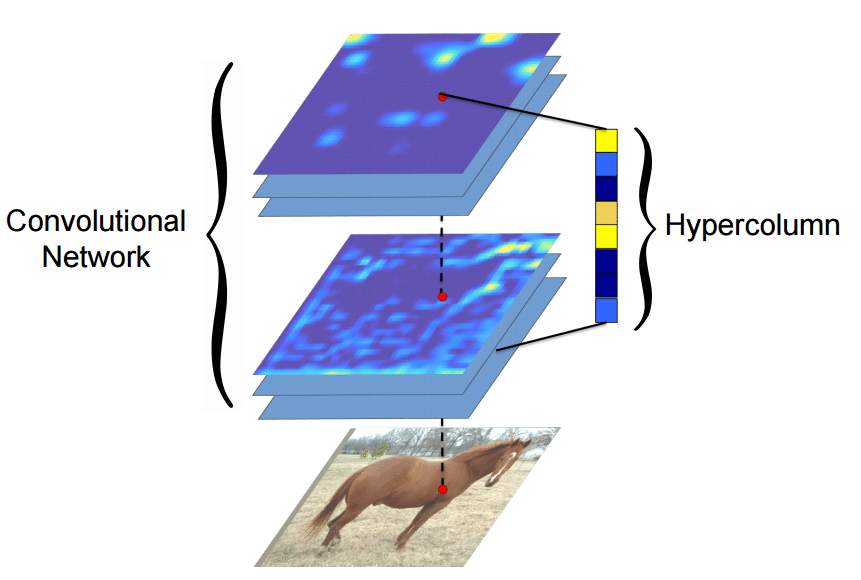
The first step on the extraction of the hypercolumns is to feed the image into the CNN (Convolutional Neural Network) and extract the feature map activations for each location of the image. The tricky part is when the feature maps are smaller than the input image, for instance after a pooling operation, the authors of the paper then do a bilinear upsampling of the feature map in order to keep the feature maps on the same size of the input. There are also the issue with the FC (fully-connected) layers, because you can’t isolate units semantically tied only to one pixel of the image, so the FC activations are seen as 1×1 feature maps, which means that all locations shares the same information regarding the FC part of the hypercolumn. All these activations are then concatenated to create the hypercolumn. For instance, if we take the VGG-16 architecture to use only the first 2 convolutional layers after the max pooling operations, we will have a hypercolumn with the size of:
64 filters (first conv layer before pooling)
+
128 filters (second conv layer before pooling ) = 192 features
This means that each pixel of the image will have a 192-dimension hypercolumn vector. This hypercolumn is really interesting because it will contain information about the first layers (where we have a lot of spatial information but little semantic) and also information about the final layers (with little spatial information and lots of semantics). Thus this hypercolumn will certainly help in a lot of pixel classification tasks such as the one mentioned earlier of automatic colorization, because each location hypercolumn carries the information about what this pixel semantically and spatially represents. This is also very helpful on segmentation tasks (you can see more about that on the original paper introducing the hypercolumn concept).
Everything sounds cool, but how do we extract hypercolumns in practice ?
VGG-16
Before being able to extract the hypercolumns, we’ll setup the VGG-16 pre-trained network, because you know, the price of a good GPU (I can’t even imagine many of them) here in Brazil is very expensive and I don’t want to sell my kidney to buy a GPU.
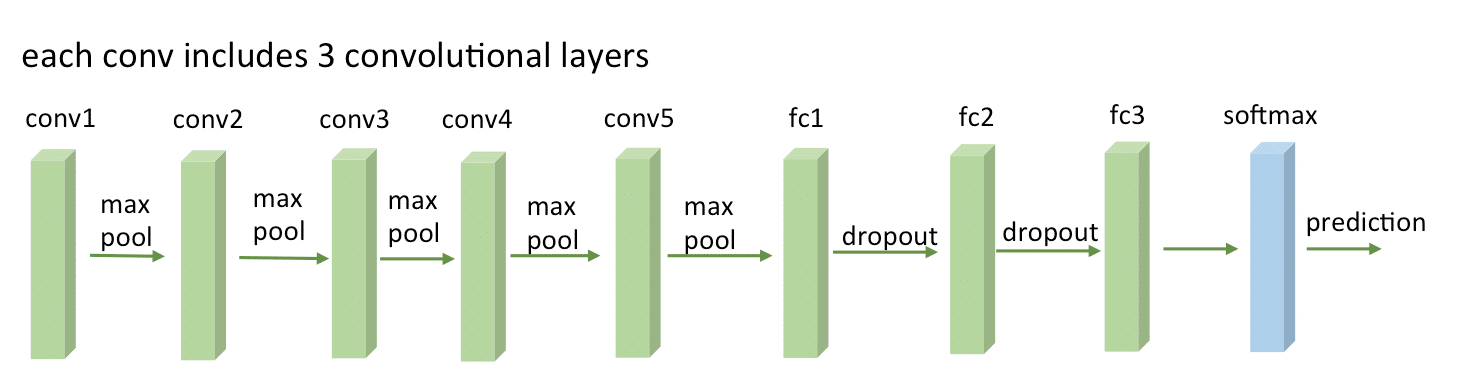
To setup a pretrained VGG-16 network on Keras, you’ll need to download the weights file from here (vgg16_weights.h5 file with approximately 500MB) and then setup the architecture and load the downloaded weights using Keras (more information about the weights file and architecture here):
from matplotlib import pyplot as plt
import theano
import cv2
import numpy as np
import scipy as sp
from keras.models import Sequential
from keras.layers.core import Flatten, Dense, Dropout
from keras.layers.convolutional import Convolution2D, MaxPooling2D
from keras.layers.convolutional import ZeroPadding2D
from keras.optimizers import SGD
from sklearn.manifold import TSNE
from sklearn import manifold
from sklearn import cluster
from sklearn.preprocessing import StandardScaler
def VGG_16(weights_path=None):
model = Sequential()
model.add(ZeroPadding2D((1,1),input_shape=(3,224,224)))
model.add(Convolution2D(64, 3, 3, activation='relu'))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(64, 3, 3, activation='relu'))
model.add(MaxPooling2D((2,2), stride=(2,2)))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(128, 3, 3, activation='relu'))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(128, 3, 3, activation='relu'))
model.add(MaxPooling2D((2,2), stride=(2,2)))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(256, 3, 3, activation='relu'))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(256, 3, 3, activation='relu'))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(256, 3, 3, activation='relu'))
model.add(MaxPooling2D((2,2), stride=(2,2)))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(512, 3, 3, activation='relu'))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(512, 3, 3, activation='relu'))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(512, 3, 3, activation='relu'))
model.add(MaxPooling2D((2,2), stride=(2,2)))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(512, 3, 3, activation='relu'))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(512, 3, 3, activation='relu'))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(512, 3, 3, activation='relu'))
model.add(MaxPooling2D((2,2), stride=(2,2)))
model.add(Flatten())
model.add(Dense(4096, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(4096, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(1000, activation='softmax'))
if weights_path:
model.load_weights(weights_path)
return model
As you can see, this is a very simple code to declare the VGG16 architecture and load the pre-trained weights (together with Python imports for the required packages). After that we’ll compile the Keras model:
model = VGG_16('vgg16_weights.h5')
sgd = SGD(lr=0.1, decay=1e-6, momentum=0.9, nesterov=True)
model.compile(optimizer=sgd, loss='categorical_crossentropy')
Now let’s test the network using an image:
im_original = cv2.resize(cv2.imread('madruga.jpg'), (224, 224))
im = im_original.transpose((2,0,1))
im = np.expand_dims(im, axis=0)
im_converted = cv2.cvtColor(im_original, cv2.COLOR_BGR2RGB)
plt.imshow(im_converted)
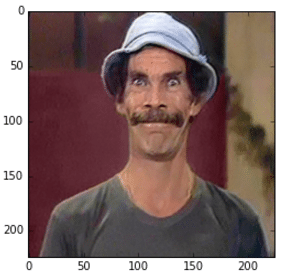
Image used
As we can see, we loaded the image, fixed the axes and then we can now feed the image into the VGG-16 to get the predictions:
out = model.predict(im) plt.plot(out.ravel())
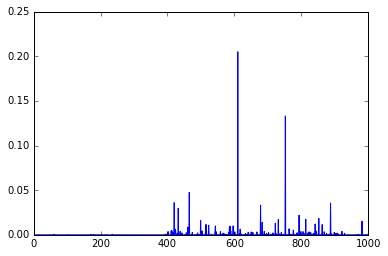
As you can see, these are the final activations of the softmax layer, the class with the “jersey, T-shirt, tee shirt” category.
Extracting arbitrary feature maps
Now, to extract the feature map activations, we’ll have to being able to extract feature maps from arbitrary convolutional layers of the network. We can do that by compiling a Theano function using the get_output() method of Keras, like in the example below:
get_feature = theano.function([model.layers[0].input], model.layers[3].get_output(train=False), allow_input_downcast=False) feat = get_feature(im) plt.imshow(feat[0][2])
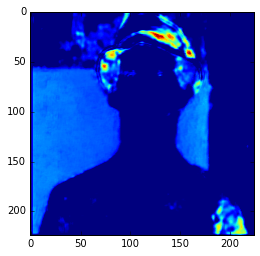
Feature Map
In the example above, I’m compiling a Theano function to get the 3 layer (a convolutional layer) feature map and then showing only the 3rd feature map. Here we can see the intensity of the activations. If we get feature maps of the activations from the final layers, we can see that the extracted features are more abstract, like eyes, etc. Look at this example below from the 15th convolutional layer:
get_feature = theano.function([model.layers[0].input], model.layers[15].get_output(train=False), allow_input_downcast=False) feat = get_feature(im) plt.imshow(feat[0][13])
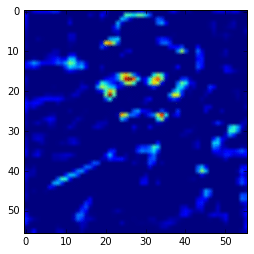
More semantic feature maps.
As you can see, this second feature map is extracting more abstract features. And you can also note that the image seems to be more stretched when compared with the feature we saw earlier, that is because the the first feature maps has 224×224 size and this one has 56×56 due to the downscaling operations of the layers before the convolutional layer, and that is why we lose a lot of spatial information.
Extracting hypercolumns
Now finally let’s extract the hypercolumns of arbitrary set of layers. To do that, we will define a function to extract these hypercolumns:
def extract_hypercolumn(model, layer_indexes, instance):
layers = [model.layers[li].get_output(train=False) for li in layer_indexes]
get_feature = theano.function([model.layers[0].input], layers,
allow_input_downcast=False)
feature_maps = get_feature(instance)
hypercolumns = []
for convmap in feature_maps:
for fmap in convmap[0]:
upscaled = sp.misc.imresize(fmap, size=(224, 224),
mode="F", interp='bilinear')
hypercolumns.append(upscaled)
return np.asarray(hypercolumns)
As we can see, this function will expect three parameters: the model itself, an list of layer indexes that will be used to extract the hypercolumn features and an image instance that will be used to extract the hypercolumns. Let’s now test the hypercolumn extraction for the first 2 convolutional layers:
layers_extract = [3, 8] hc = extract_hypercolumn(model, layers_extract, im)
That’s it, we extracted the hypercolumn vectors for each pixel. The shape of this “hc” variable is: (192L, 224L, 224L), which means that we have a 192-dimensional hypercolumn for each one of the 224×224 pixel (a total of 50176 pixels with 192 hypercolumn feature each).
Let’s plot the average of the hypercolumns activations for each pixel:
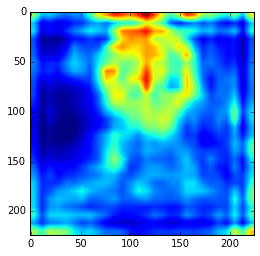
ave = np.average(hc.transpose(1, 2, 0), axis=2) plt.imshow(ave)
Ad you can see, those first hypercolumn activations are all looking like edge detectors, let’s see how these hypercolumns looks like for the layers 22 and 29:
layers_extract = [22, 29] hc = extract_hypercolumn(model, layers_extract, im) ave = np.average(hc.transpose(1, 2, 0), axis=2) plt.imshow(ave)
As we can see now, the features are really more abstract and semantically interesting but with spatial information a little fuzzy.
Remember that you can extract the hypercolumns using all the initial layers and also the final layers, including the FC layers. Here I’m extracting them separately to show how they differ in the visualization plots.
Simple hypercolumn pixel clustering
Now, you can do a lot of things, you can use these hypercolumns to classify pixels for some task, to do automatic pixel colorization, segmentation, etc. What I’m going to do here just as an experiment, is to use the hypercolumns (from the VGG-16 layers 3, 8, 15, 22, 29) and then cluster it using KMeans with 2 clusters:
m = hc.transpose(1,2,0).reshape(50176, -1) kmeans = cluster.KMeans(n_clusters=2, max_iter=300, n_jobs=5, precompute_distances=True) cluster_labels = kmeans .fit_predict(m) imcluster = np.zeros((224,224)) imcluster = imcluster.reshape((224*224,)) imcluster = cluster_labels plt.imshow(imcluster.reshape(224, 224), cmap="hot")
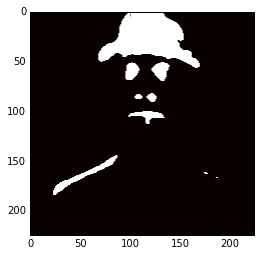
Now you can imagine how useful hypercolumns can be to tasks like keypoints extraction, segmentation, etc. It’s a very elegant, simple and useful concept.
I hope you liked it !
– Christian S. Perone
") which is actually the term count of the term
which is actually the term count of the term  in the document
in the document  . The use of this simple term frequency could lead us to problems like keyword spamming, which is when we have a repeated term in a document with the purpose of improving its ranking on an IR (Information Retrieval) system or even create a bias towards long documents, making them look more important than they are just because of the high frequency of the term in the document.
. The use of this simple term frequency could lead us to problems like keyword spamming, which is when we have a repeated term in a document with the purpose of improving its ranking on an IR (Information Retrieval) system or even create a bias towards long documents, making them look more important than they are just because of the high frequency of the term in the document. that we have calculated in the first part of this tutorial. The document
that we have calculated in the first part of this tutorial. The document  from the first part of this tutorial had this textual representation:
from the first part of this tutorial had this textual representation:")
 . The definition of the unit vector
. The definition of the unit vector  is:
is:
 is the norm (magnitude, length) of the vector
is the norm (magnitude, length) of the vector  space (don’t worry, I’m going to explain it all).
space (don’t worry, I’m going to explain it all).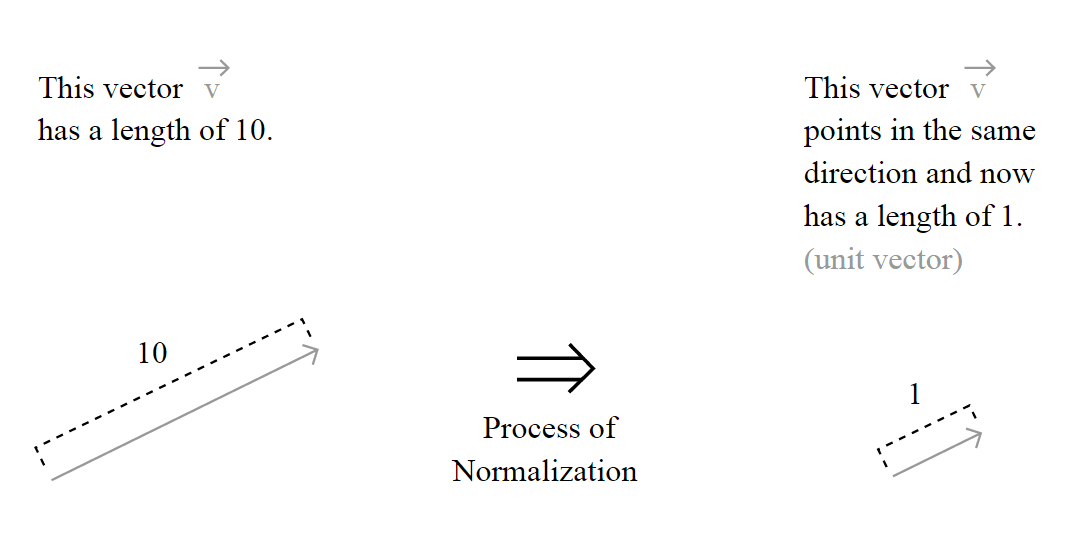
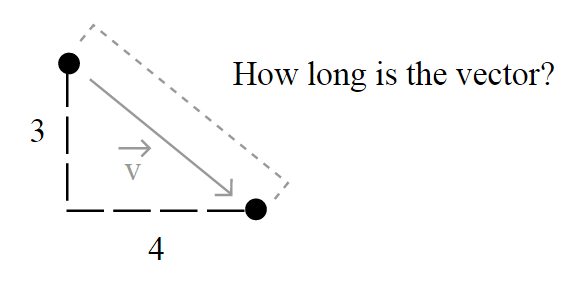
") is calculated using the
is calculated using the 

 together with the norm notation, like in
together with the norm notation, like in  . That’s because it could be generalized as:
. That’s because it could be generalized as:^\frac{1}{p}")
^\frac{1}{p}")
 , the most common norm used to measure the length of a vector, typically called “magnitude”; actually, when you have an unqualified length measure (without the
, the most common norm used to measure the length of a vector, typically called “magnitude”; actually, when you have an unqualified length measure (without the  , defined as:
, defined as:")

 , and is the unique shortest path.
, and is the unique shortest path. . To do that, we’ll simple plug it into the definition of the unit vector to evaluate it:
. To do that, we’ll simple plug it into the definition of the unit vector to evaluate it:}{\sqrt{0^2 + 2^2 + 1^2 + 0^2}} \\ \\ \hat{v_{d_4}} = \frac{(0,2,1,0)}{\sqrt{5}} \\ \\ \small \hat{v_{d_4}} = (0.0, 0.89442719, 0.4472136, 0.0)")
 .
. where
where  is the number of documents in your corpus, and in our case as
is the number of documents in your corpus, and in our case as  and
and  . The cardinality of our document space is defined by
. The cardinality of our document space is defined by  and
and  , since we have only 2 two documents for training and testing, but they obviously don’t need to have the same cardinality.
, since we have only 2 two documents for training and testing, but they obviously don’t need to have the same cardinality. = \log{\frac{\left|D\right|}{1+\left|\{d : t \in d\}\right|}}")
 is the number of documents where the term
is the number of documents where the term  \neq 0") , we’re only adding 1 into the formula to avoid zero-division.
, we’re only adding 1 into the formula to avoid zero-division. = \mathrm{tf}(t, d) \times \mathrm{idf}(t)")

") ,
, ") ,
, ") ,
, ") :
: = \log{\frac{\left|D\right|}{1+\left|\{d : t_1 \in d\}\right|}} = \log{\frac{2}{1}} = 0.69314718")
 = \log{\frac{\left|D\right|}{1+\left|\{d : t_2 \in d\}\right|}} = \log{\frac{2}{3}} = -0.40546511")
 = \log{\frac{\left|D\right|}{1+\left|\{d : t_3 \in d\}\right|}} = \log{\frac{2}{3}} = -0.40546511")
 = \log{\frac{\left|D\right|}{1+\left|\{d : t_4 \in d\}\right|}} = \log{\frac{2}{2}} = 0.0")
")
 ) and the vector representing the idf for each feature of our matrix (
) and the vector representing the idf for each feature of our matrix ( ), we can calculate our tf-idf weights. What we have to do is a simple multiplication of each column of the matrix
), we can calculate our tf-idf weights. What we have to do is a simple multiplication of each column of the matrix  with both the vertical and horizontal dimensions equal to the vector
with both the vertical and horizontal dimensions equal to the vector 

 will be different than the result of the
will be different than the result of the  , and this is why the
, and this is why the  & \mathrm{tf}(t_2, d_1) & \mathrm{tf}(t_3, d_1) & \mathrm{tf}(t_4, d_1)\\ \mathrm{tf}(t_1, d_2) & \mathrm{tf}(t_2, d_2) & \mathrm{tf}(t_3, d_2) & \mathrm{tf}(t_4, d_2) \end{bmatrix} \times \begin{bmatrix} \mathrm{idf}(t_1) & 0 & 0 & 0\\ 0 & \mathrm{idf}(t_2) & 0 & 0\\ 0 & 0 & \mathrm{idf}(t_3) & 0\\ 0 & 0 & 0 & \mathrm{idf}(t_4) \end{bmatrix} \\ = \begin{bmatrix} \mathrm{tf}(t_1, d_1) \times \mathrm{idf}(t_1) & \mathrm{tf}(t_2, d_1) \times \mathrm{idf}(t_2) & \mathrm{tf}(t_3, d_1) \times \mathrm{idf}(t_3) & \mathrm{tf}(t_4, d_1) \times \mathrm{idf}(t_4)\\ \mathrm{tf}(t_1, d_2) \times \mathrm{idf}(t_1) & \mathrm{tf}(t_2, d_2) \times \mathrm{idf}(t_2) & \mathrm{tf}(t_3, d_2) \times \mathrm{idf}(t_3) & \mathrm{tf}(t_4, d_2) \times \mathrm{idf}(t_4) \end{bmatrix}")

 matrix. Please note that this normalization is “row-wise” because we’re going to handle each row of the matrix as a separated vector to be normalized, and not the matrix as a whole:
matrix. Please note that this normalization is “row-wise” because we’re going to handle each row of the matrix as a separated vector to be normalized, and not the matrix as a whole:

 and
and  from the document set, we’ll have the following index vocabulary denoted as
from the document set, we’ll have the following index vocabulary denoted as ") where the
where the  = \begin{cases} 1, & \mbox{if } t\mbox{ is \"blue\"} \\ 2, & \mbox{if } t\mbox{ is \"sun\"} \\ 3, & \mbox{if } t\mbox{ is \"bright\"} \\ 4, & \mbox{if } t\mbox{ is \"sky\"} \\ \end{cases}")
 or
or  = \sum\limits_{x\in d} \mathrm{fr}(x, t)")
") is a simple function defined as:
is a simple function defined as: = \begin{cases} 1, & \mbox{if } x = t \\ 0, & \mbox{otherwise} \\ \end{cases}")
") returns is how many times is the term
returns is how many times is the term  = 2") since we have only two occurrences of the term “sun” in the document
since we have only two occurrences of the term “sun” in the document , \mathrm{tf}(t_2,d_n), \mathrm{tf}(t_3,d_n), \ldots, \mathrm{tf}(t_n,d_n))")
") represents the frequency-term of the term 1 or
represents the frequency-term of the term 1 or  (which is our “blue” term of the vocabulary) in the document
(which is our “blue” term of the vocabulary) in the document  .
. and
and  are represented as vectors:
are represented as vectors:, \mathrm{tf}(t_2,d_3), \mathrm{tf}(t_3,d_3), \ldots, \mathrm{tf}(t_n,d_3)) \\ \vec{v_{d_4}} = (\mathrm{tf}(t_1,d_4), \mathrm{tf}(t_2,d_4), \mathrm{tf}(t_3,d_4), \ldots, \mathrm{tf}(t_n,d_4))")
 \\ \vec{v_{d_4}} = (0, 2, 1, 0)")
 shows that we have, in order, 0 occurrences of the term “blue”, 1 occurrence of the term “sun”, and so on. In the
shows that we have, in order, 0 occurrences of the term “blue”, 1 occurrence of the term “sun”, and so on. In the  shape, where
shape, where  is the cardinality of the document space, or how many documents we have and the
is the cardinality of the document space, or how many documents we have and the  is the number of features, in our case represented by the vocabulary size. An example of the matrix representation of the vectors described above is:
is the number of features, in our case represented by the vocabulary size. An example of the matrix representation of the vectors described above is:
") (except because it is zero-indexed).
(except because it is zero-indexed). we cited earlier in this post, which represents the two document vectors
we cited earlier in this post, which represents the two document vectors 