Feste: composing NLP tasks with automatic parallelization and batching
![]()
I just released Feste, a free and open-source framework with a permissive license that allows scalable composition of NLP tasks using a graph execution model that is optimized and executed by specialized schedulers. The main idea behind Feste is that it builds a graph of execution instead of executing tasks immediately, this graph allows Feste to optimize and parallelize it. One main example of optimization is when we have multiple calls to the same backend (e.g. same API), Feste automatically fuses these calls into a single one and therefore it batches the call to reduce latency and improve backend inference leverage of GPU vectorization. Feste also executes tasks that can be done in parallel in different processes, so the user doesn’t have to care about parallelization, especially when there are multiple frameworks using different concurrency strategies.
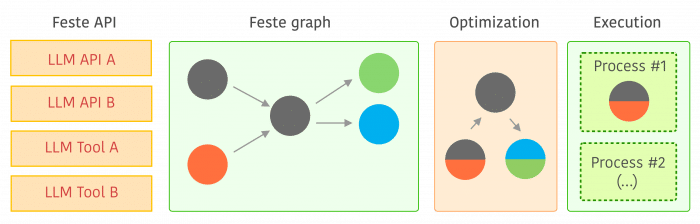
Project page: https://feste.readthedocs.io/en/latest/design.html
Github: https://github.com/perone/feste
