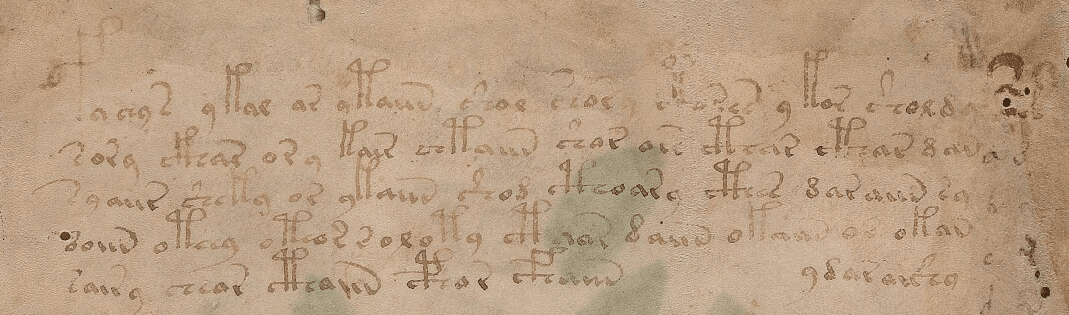The receptive field in Convolutional Neural Networks (CNN) is the region of the input space that affects a particular unit of the network. Note that this input region can be not only the input of the network but also output from other units in the network, therefore this receptive field can be calculated relative to the input that we consider and also relative the unit that we are taking into consideration as the “receiver” of this input region. Usually, when the receptive field term is mentioned, it is taking into consideration the final output unit of the network (i.e. a single unit on a binary classification task) in relation to the network input (i.e. input image of the network).
It is easy to see that on a CNN, the receptive field can be increased using different methods such as: stacking more layers (depth), subsampling (pooling, striding), filter dilation (dilated convolutions), etc. In theory, when you stack more layers you can increase your receptive field linearly, however, in practice, things aren’t simple as we thought, as shown by Luo, Wenjie et al. article. In the article, they introduce the concept of the “Effective Receptive Field”, or ERF; the intuition behind the concept is that not all pixels in the receptive field contribute equally to the output unit’s response. When doing the forward pass, we can see that the central receptive field pixels can propagate their information to the output using many different paths, as they are part of multiple output unit’s calculations.
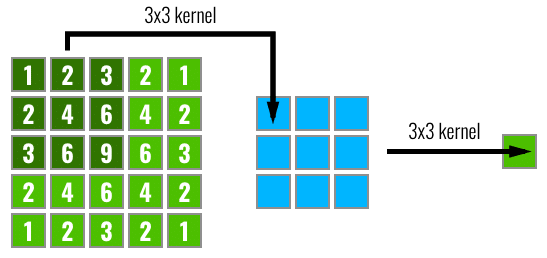
In the figure below, we can see in left the input pixels, after that we have a feature map calculated from the input pixels using a 3×3 convolution filter and then finally the output after another 3×3 filtering. The numbers inside the pixels on the left image represent how many times this pixel was part of a convolution step (each sliding step of the filter). As we can see, some pixels like the central ones will have their information propagated through many different paths in the network, while the pixels on the borders are propagated along a single path.
Receptive Field across 3 different layers using 3×3 filters.
By looking at the image above, it isn’t that surprising that the effective receptive field impact on the final output computation will look more like a Gaussian distribution instead of a uniform distribution. What is actually more even interesting is that this receptive field is dynamic and changes during the training. The impact of this on the backpropagation is that the central pixels will have a larger gradient magnitude when compared to the border pixels.
In the article written by Luo, Wenjie et al., they devised a way to quantify the effect on each input pixel of the network by calculating the quantity that represents how much each pixel contributes to the output .
In the paper, they did experimentations to visualize the effective receptive field using multiple different architectures, activations, etc. I replicate here the ones that I found most interesting:
Figure 1 from the paper “Understanding the Effective Receptive Field in Deep Convolutional Neural Networks”, by Luo, Wenjie et al.
As we can see from the Figure 1 of the paper, where they compare the effect of the number of layers, initialization schemes, and different activations, the results are amazing. We can clearly see the Gaussian and also the sparsity added by the ReLU activations.
There are also some comparisons on Figure 3 of the paper, where CIFAR-10 and CamVid datasets were used to train the network.
Figure 3 of the paper “Understanding the Effective Receptive Field in Deep Convolutional Neural Networks”, by Luo, Wenjie et al.
As we can see, the size of the effective receptive field is very dynamic and it is increased by a large margin after the training, which implies, as stated by authors of the paper, that better initialization schemes can be employed to increase the receptive field in the beginning of the training. They actually developed a different initialization scheme and were able to get 30% training speed-up, however, these results weren’t consistent.
Foveal vision on reading activity. Image from http://www.learning-systems.ch.
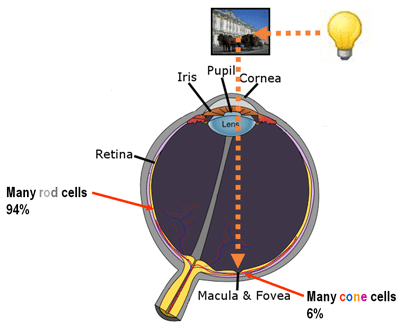
What is also very interesting, is that the effective receptive field has a very close relationship with the foveal vision of the human eye, which produces the sharp central vision, effect of the high-density region of cone cells (as shown in the image below) present in the eye fundus.
Fovea region on the human eye. Image from http://eyetracking.me.
Our central sharp vision also decays rapidly like the effective receptive field that is very similar to a Gaussian. It is amazing that this effect is also naturally present on the CNN networks.
PS: Just for the sake of curiosity, some birds that do complex aerial movements such as the hummingbird, have two foveas instead of a single one, which means that they have a sharp accurate vision not only on the central region but also on the sides.
Since Benford’s law got some attention in the past years, I decided to make a list of the previous posts I made on the subject in the context of elections, fraud, corruption, universality and prime numbers:
* This is a critical article regarding the presence of historicism in modern AI predictions for the future.
Ray Kurzweil
Perhaps you already read about the Technological Singularity, since it is one of the hottest predictions for the future (there is even a university with that name), especially after the past years’ development of AI, more precisely, after recent Deep Learning advancements that attracted a lot of attention (and bad journalism too). In his The Singularity is near (2005) book, Ray Kurzweil predicts that humans will transcend the “limitations of our biological bodies and brain”, stating also that “future machines will be human, even if they are not biological”. In other books, like The Age of Intelligent Machines (1990), he also predicts a new world government, computers passing Turing tests, exponential laws everywhere, and so on (not that hard to have a good recall rate with that amount of predictions right ?).
As science fiction, these predictions are pretty amazing, and many of them were very close to what happened in our “modern days” (and I also really love the works made by Arthur C. Clarke), however, there are a lot of people that are putting science clothes on what is called “futurism”, sometimes also called “future studies” or “futurology”, although as you can imagine, the last term is usually avoided due to some obvious reasons (sounds like astrology, and you don’t want to be linked to pseudo-science right ?).
In this post, I would like to talk not about the predictions. Personally, I think that these points of view are really relevant to our future, just like the serious research on ethics and moral in AI, but I would like to criticize a very particular aspect of the status of how these ideas are being diffused, and I like to make the point here very clear: I’m NOT criticizing the predictions themselves, NEITHER the importance of these predictions and different views of the future, but the status of these ideas, because it seems that there is a major comeback of a kind of historicism in this particular field that I would like to discuss.
There is a very subtle line where it is very easy to transition from a personal prediction of historical events to a view where you pretend that these predictions have a scientific status. Some harsh critics were made in the past regarding the Technological Singularity, such as this one from Steven Pinker (2008):
(…) There is not the slightest reason to believe in a coming singularity. The fact that you can visualize a future in your imagination is not evidence that it is likely or even possible. Look at domed cities, jet-pack commuting, underwater cities, mile-high buildings, and nuclear-powered automobiles—all staples of futuristic fantasies when I was a child that have never arrived. Sheer processing power is not a pixie dust that magically solves all your problems. (…) –
– Steven Pinker, 2008
Steven Pinker is criticizing here an important aspect, that is obvious but many people usually do not understand the implication of this: the fact that you can imagine something isn’t a reason or evidence that this is possible. Just like the ontological argument was criticized in the past by Immanuel Kant, where we have the same kind of transition.
Karl Popper
However, what I would like to criticize here is the fact that a lot of futurists are postulating these predictions as if they have a scientific status, which is a gross misunderstanding of the scientific method that led to the development of the social historicism in the past, and that was hardly criticized by the philosopher Karl Popper in many different important works such as The Open Society and Its Enemies (1945) and on The Poverty of Historicism (1936) in the political context.
Historicism, as Popper describes, is characterized by the belief that once you have discovered the developmental laws (like the futurist exponential laws) of history (or AI development), that would enable us to prophesy the destiny of man with scientific status. Karl Popper found that the dangerous habit of historical prophecy, so widespread among our intellectual leaders, has various functions:
“It is always flattering to belong to the inner circle of the initiated, and to possess the unusual power of predicting the course of history. Besides, there is a tradition that intellectual leaders are gifted with such powers, and not to possess them may lead to the loss of caste. The danger, on the other hand, of their being unmasked as charlatans is very small, since they can always point out that it is certainly permissible to make less sweeping predictions; and the boundaries between these and augury are fluid.”
– Karl Popper, 1945
Recently, we were also able to witness the debate between Elon Musk and Mark Zuckerberg, where you’ll find all sort of criticism between each other, but little or no humility regarding the limits of these claims. Karl Popper mentions an important fact to consider in his The Open Society and Its Enemies book on the social context, that can also be certainly applied here as you’ll note:
(…) Such arguments may sound plausible enough. But plausibility is not a reliable guide in such matters. In fact, one should not enter into a discussion of these specious arguments before having considered the following question of method: Is it within the power of any social science to make such sweeping historical prophecies ? Can we expect to get more than the irresponsible reply of the soothsayer if we ask a man what the future has in store for mankind ?
– Karl Popper, 1945
With that said, we should always remember the importance of our future views and predictions, but we should also never forget the status of these predictions, and be always responsible for our diffusion of these claims. They aren’t scientific by any means, and we shouldn’t take them as that, especially when dangerous ideas such as the urge for control are being made based on these personal future prophecies.
I would like to close this post by quoting Karl Popper:
The systematic analysis of historicism aims at something like scientific status. This book does not. Many of the opinions expressed are personal. What it owes to scientific method is largely the awareness of its limitations : it does not offer proofs where nothing can be proved, nor does it pretend to be scientific where it cannot give more than a personal point of view. It does not try to replace the old systems of philosophy by a new system. It does not try to add to all these volumes filled withwisdom, to the metaphysics of history and destiny, such as are fashionable nowadays. It rather tries to show that this prophetic wisdom is harmful, that the metaphysics of historyimpede the application of the piecemeal methods of science to the problems of social reform. And it further triesto show how we may become the makers of our fate when we have ceased to pose as its prophets.
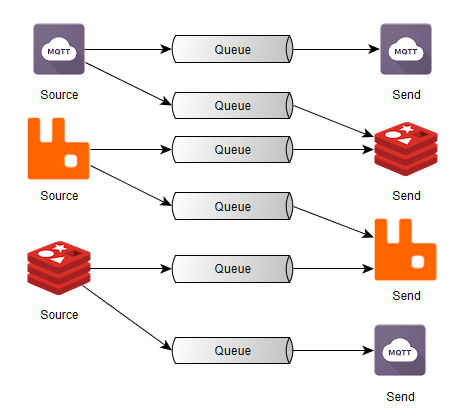
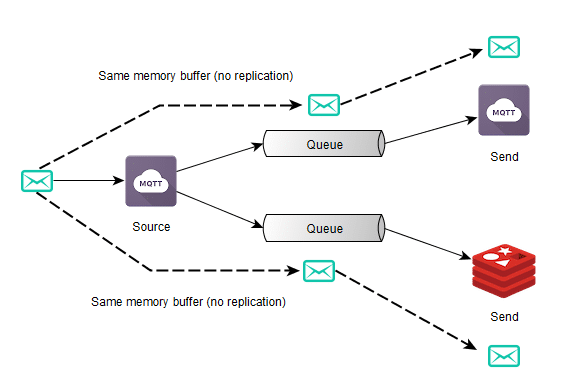
Hello everyone, I just released the Nanopipe project. Nanopipe is a library that allows you to connect different message queue systems (but not limited to) together. Nanopipe was built to avoid the glue code between different types of communication protocols/channels that is very common nowadays. An example of this is: you have an application that is listening for messages on an AMQP broker (ie. RabbitMQ) but you also have a Redis pub/sub source of messages and also a MQTT source from a weird IoT device you may have. Using Nanopipe, you can connect both MQTT and Redis to RabbitMQ without doing any glue code for that. You can also build any kind of complex connection scheme using Nanopipe.
One of the most amazing components of the TensorFlow architecture is the computation graph that can be serialized using Protocol Buffers. This computation graph follows a well-defined format (click here for the proto files) and describes the computation that you specify (it can be a Deep Learning model like a CNN, a simple Logistic Regression or even any computation you want). For instance, here is an example of a very simple TensorFlow computation graph that we will use in this tutorial (using TensorFlow Python API):
As you can see, this is a very simple computation graph. First, we define the placeholder that will hold the input tensor and after that we specify the computation that should happen using this input tensor as input data. Here we can also see that we’re defining two important nodes of this graph, one is called “input” (the aforementioned placeholder) and the other is called “output“, that will hold the result of the final computation. This graph is the same as the following formula for a scalar: , where I intentionally added redundant operations to see LLVM constant propagation later.
In the last line of the code, we’re persisting this computation graph (including the constant values) into a serialized protobuf file. The final True parameter is to output a textual representation instead of binary, so it will produce the following human-readable output protobuf file (I omitted a part of it for brevity):
This is a very simple graph, and TensorFlow graphs are actually never that simple, because TensorFlow models can easily contain more than 300 nodes depending on the model you’re specifying, specially for Deep Learning models.
We’ll use the above graph to show how we can JIT native code for this simple graph using LLVM framework.
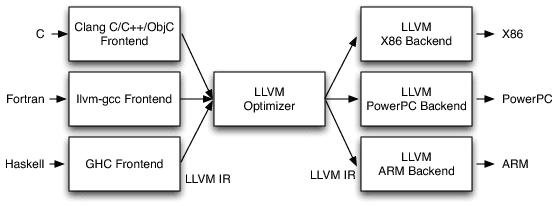
The LLVM Frontend, IR and Backend
The LLVM framework is a really nice, modular and complete ecosystem for building compilers and toolchains. A very nice description of the LLVM architecture that is important for us is shown in the picture below:
LLVM Compiler Architecture (AOSA/LLVM, Chris Lattner)
(The picture above is just a small part of the LLVM architecture, for a comprehensive description of it, please see the nice article from the AOSA book written by Chris Lattner)
Looking in the image above, we can see that LLVM provides a lot of core functionality, in the left side you see that many languages can write code for their respective language frontends, after that it doesn’t matter in which language you wrote your code, everything is transformed into a very powerful language called LLVM IR (LLVM Intermediate Representation) which is as you can imagine, a intermediate representation of the code just before the assembly code itself. In my opinion, the IR is the key component of what makes LLVM so amazing, because it doesn’t matter in which language you wrote your code (or even if it was a JIT’ed IR), everything ends in the same representation, and then here is where the magic happens, because the IR can take advantage of the LLVM optimizations (also known as transform and analysis passes).
After this IR generation, you can feed it into any LLVM backend to generate native code for any architecture supported by LLVM (such as x86, ARM, PPC, etc) and then you can finally execute your code with the native performance and also after LLVM optimization passes.
In order to JIT code using LLVM, all you need is to build the IR programmatically, create a execution engine to convert (during execution-time) the IR into native code, get a pointer for the function you have JIT’ed and then finally execute it. I’ll use here a Python binding for LLVM called llvmlite, which is very Pythonic and easy to use.
JIT’ing TensorFlow Graph using Python and LLVM
Let’s now use the LLVM and Python to JIT the TensorFlow computational graph. This is by no means a comprehensive implementation, it is very simplistic approach, a oversimplification that assumes some things: a integer closure type, just some TensorFlow operations and also a single scalar support instead of high rank tensors.
So, let’s start building our JIT code; first of all, let’s import the required packages, initialize some LLVM sub-systems and also define the LLVM respective type for the TensorFlow integer type:
from ctypes import CFUNCTYPE, c_int
import tensorflow as tf
from google.protobuf import text_format
from tensorflow.core.framework import graph_pb2
from tensorflow.core.framework import types_pb2
from tensorflow.python.framework import ops
import llvmlite.ir as ll
import llvmlite.binding as llvm
llvm.initialize()
llvm.initialize_native_target()
llvm.initialize_native_asmprinter()
TYPE_TF_LLVM = {
types_pb2.DT_INT32: ll.IntType(32),
}
After that, let’s define a class to open the TensorFlow exported graph and also declare a method to get a node of the graph by name:
class TFGraph(object):
def __init__(self, filename="graph.pb", binary=False):
self.graph_def = graph_pb2.GraphDef()
with open("graph.pb", "rb") as f:
if binary:
self.graph_def.ParseFromString(f.read())
else:
text_format.Merge(f.read(), self.graph_def)
def get_node(self, name):
for node in self.graph_def.node:
if node.name == name:
return node
And let’s start by defining our main function that will be the starting point of the code:
As you can see in the code above, we open the serialized protobuf graph and then get the input and output nodes of this graph. After that we also map the type of the both graph nodes (input/output) to the LLVM type (from TensorFlow integer to LLVM integer). We start then by defining a LLVM Module, which is the top level container for all IR objects. One module in LLVM can contain many different functions, here we will create just one function that will represent the graph, this function will receive as input argument the input data of the same type of the input node and then it will return a value with the same type of the output node.
After that we start by creating the entry block of the function and using this block we instantiate our IR Builder, which is a object that will provide us the building blocks for JIT’ing operations of TensorFlow graph.
Let’s now define the function that will do the real work of converting TensorFlow nodes into LLVM IR:
def build_graph(ir_builder, graph, node):
if node.op == "Add":
left_op_node = graph.get_node(node.input[0])
right_op_node = graph.get_node(node.input[1])
left_op = build_graph(ir_builder, graph, left_op_node)
right_op = build_graph(ir_builder, graph, right_op_node)
return ir_builder.add(left_op, right_op)
if node.op == "Sub":
left_op_node = graph.get_node(node.input[0])
right_op_node = graph.get_node(node.input[1])
left_op = build_graph(ir_builder, graph, left_op_node)
right_op = build_graph(ir_builder, graph, right_op_node)
return ir_builder.sub(left_op, right_op)
if node.op == "Placeholder":
function_args = ir_builder.function.args
for arg in function_args:
if arg.name == node.name:
return arg
raise RuntimeError("Input [{}] not found !".format(node.name))
if node.op == "Const":
llvm_const_type = TYPE_TF_LLVM[node.attr["dtype"].type]
const_value = node.attr["value"].tensor.int_val[0]
llvm_const_value = llvm_const_type(const_value)
return llvm_const_value
In this function, we receive by parameters the IR Builder, the graph class that we created earlier and the output node. This function will then recursively build the LLVM IR by means of the IR Builder. Here you can see that I only implemented the Add/Sub/Placeholder and Const operations from the TensorFlow graph, just to be able to support the graph that we defined earlier.
After that, we just need to define a function that will take a LLVM Module and then create a execution engine that will execute the LLVM optimization over the LLVM IR before doing the hard-work of converting the IR into native x86 code:
In the code above, you can see that we first get the CPU features (SSE, etc) into a list, after that we parse the LLVM IR from the module and then we create a engine using maximum optimization level (opt=3, roughly equivalent to the GCC -O3 parameter), we’re also printing the assembly code (in my case, the x86 assembly built by LLVM).
And here we just finish our run_main() function:
ret = build_graph(ir_builder, graph, output_node)
ir_builder.ret(ret)
with open("output.ir", "w") as f:
f.write(str(module))
engine = create_engine(module)
func_ptr = engine.get_function_address("tensorflow_graph")
cfunc = CFUNCTYPE(c_int, c_int)(func_ptr)
ret = cfunc(10)
print "Execution output: {}".format(ret)
As you can see in the code above, we just call the build_graph() method and then use the IR Builder to add the “ret” LLVM IR instruction (ret = return) to return the output of the IR function we just created based on the TensorFlow graph. We’re also here writing the IR output to a external file, I’ll use this LLVM IR file later to create native assembly for other different architectures such as ARM architecture. And finally, just get the native code function address, create a Python wrapper for this function and then call it with the argument “10”, which will be input data and then output the resulting output value.
And that is it, of course that this is just a oversimplification, but now we understand the advantages of having a JIT for our TensorFlow models.
The output LLVM IR, the advantage of optimizations and multiple architectures (ARM, PPC, x86, etc)
For instance, lets create the LLVM IR (using the code I shown above) of the following TensorFlow graph:
As you can see, the LLVM IR looks a lot like an assembly code, but this is not the final assembly code, this is just a non-optimized IR yet. Just before generating the x86 assembly code, LLVM runs a lot of optimization passes over the LLVM IR, and it will do things such as dead code elimination, constant propagation, etc. And here is the final native x86 assembly code that LLVM generates for the above LLVM IR of the TensorFlow graph:
As you can see, the optimized code removed a lot of redundant operations, and ended up just doing a add operation of 103, which is the correct simplification of the computation that we defined in the graph. For large graphs, you can see that these optimizations can be really powerful, because we are reusing the compiler optimizations that were developed for years in our Machine Learning model computation.
You can also use a LLVM tool called “llc”, that can take an LLVM IR file and the generate assembly for any other platform you want, for instance, the command-line below will generate native code for ARM architecture:
As you can see above, the ARM assembly code is also just a “add” assembly instruction followed by a return instruction.
This is really nice because we can take natural advantage of the LLVM framework. For instance, today ARM just announced the ARMv8-A with Scalable Vector Extensions (SVE) that will support 2048-bit vectors, and they are already working on patches for LLVM. In future, a really nice addition to LLVM would be the development of LLVM Passes for analysis and transformation that would take into consideration the nature of Machine Learning models.
And that’s it, I hope you liked the post ! Is really awesome what you can do with a few lines of Python, LLVM and TensorFlow.
Update 22 Aug 2016: TensorFlow team is actually working on a JIT (I don’t know if they are using LLVM, but it seems the most reasonable way to go in my opinion). In their paper, there is also a very important statement regarding Future Work that I cite here:
“We also have a number of concrete directions to improve the performance of TensorFlow. One such direction is our initial work on a just-in-time compiler that can take a subgraph of a TensorFlow execution, perhaps with some runtime profiling information about the typical sizes and shapes of tensors, and can generate an optimized routine for this subgraph. This compiler will understand the semantics of perform a number of optimizations such as loop fusion, blocking and tiling for locality, specialization for particular shapes and sizes, etc.” – TensorFlow White Paper
Full code
from ctypes import CFUNCTYPE, c_int
import tensorflow as tf
from google.protobuf import text_format
from tensorflow.core.framework import graph_pb2
from tensorflow.core.framework import types_pb2
from tensorflow.python.framework import ops
import llvmlite.ir as ll
import llvmlite.binding as llvm
llvm.initialize()
llvm.initialize_native_target()
llvm.initialize_native_asmprinter()
TYPE_TF_LLVM = {
types_pb2.DT_INT32: ll.IntType(32),
}
class TFGraph(object):
def __init__(self, filename="graph.pb", binary=False):
self.graph_def = graph_pb2.GraphDef()
with open("graph.pb", "rb") as f:
if binary:
self.graph_def.ParseFromString(f.read())
else:
text_format.Merge(f.read(), self.graph_def)
def get_node(self, name):
for node in self.graph_def.node:
if node.name == name:
return node
def build_graph(ir_builder, graph, node):
if node.op == "Add":
left_op_node = graph.get_node(node.input[0])
right_op_node = graph.get_node(node.input[1])
left_op = build_graph(ir_builder, graph, left_op_node)
right_op = build_graph(ir_builder, graph, right_op_node)
return ir_builder.add(left_op, right_op)
if node.op == "Sub":
left_op_node = graph.get_node(node.input[0])
right_op_node = graph.get_node(node.input[1])
left_op = build_graph(ir_builder, graph, left_op_node)
right_op = build_graph(ir_builder, graph, right_op_node)
return ir_builder.sub(left_op, right_op)
if node.op == "Placeholder":
function_args = ir_builder.function.args
for arg in function_args:
if arg.name == node.name:
return arg
raise RuntimeError("Input [{}] not found !".format(node.name))
if node.op == "Const":
llvm_const_type = TYPE_TF_LLVM[node.attr["dtype"].type]
const_value = node.attr["value"].tensor.int_val[0]
llvm_const_value = llvm_const_type(const_value)
return llvm_const_value
def create_engine(module):
features = llvm.get_host_cpu_features().flatten()
llvm_module = llvm.parse_assembly(str(module))
target = llvm.Target.from_default_triple()
target_machine = target.create_target_machine(opt=3, features=features)
engine = llvm.create_mcjit_compiler(llvm_module, target_machine)
engine.finalize_object()
print target_machine.emit_assembly(llvm_module)
return engine
def run_main():
graph = TFGraph("graph.pb", False)
input_node = graph.get_node("input")
output_node = graph.get_node("output")
input_type = TYPE_TF_LLVM[input_node.attr["dtype"].type]
output_type = TYPE_TF_LLVM[output_node.attr["T"].type]
module = ll.Module()
func_type = ll.FunctionType(output_type, [input_type])
func = ll.Function(module, func_type, name='tensorflow_graph')
func.args[0].name = 'input'
bb_entry = func.append_basic_block('entry')
ir_builder = ll.IRBuilder(bb_entry)
ret = build_graph(ir_builder, graph, output_node)
ir_builder.ret(ret)
with open("output.ir", "w") as f:
f.write(str(module))
engine = create_engine(module)
func_ptr = engine.get_function_address("tensorflow_graph")
cfunc = CFUNCTYPE(c_int, c_int)(func_ptr)
ret = cfunc(10)
print "Execution output: {}".format(ret)
if __name__ == "__main__":
run_main()
Presentation about an “Achitectural Zoo” of different applications and architectures of CNNs. Presented at Machine Learning Meetup in Porto Alegre yesterday.
The Voynich Manuscript is a hand-written codex written in an unknown system and carbon-dated to the early 15th century (1404–1438). Although the manuscript has been studied by some famous cryptographers of the World War I and II, nobody has deciphered it yet. The manuscript is known to be written in two different languages (Language A and Language B) and it is also known to be written by a group of people. The manuscript itself is always subject of a lot of different hypothesis, including the one that I like the most which is the “culture extinction” hypothesis, supported in 2014 by Stephen Bax. This hypothesis states that the codex isn’t ciphered, it states that the codex was just written in an unknown language that disappeared due to a culture extinction. In 2014, Stephen Bax proposed a provisional, partial decoding of the manuscript, the video of his presentation is very interesting and I really recommend you to watch if you like this codex. There is also a transcription of the manuscript done thanks to the hard-work of many folks working on it since many moons ago.
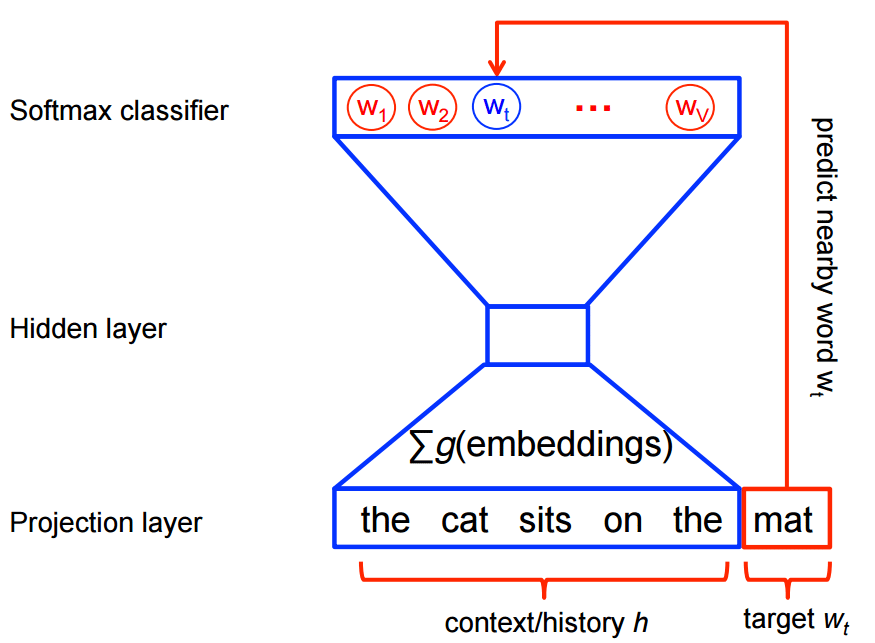
Word vectors
My idea when I heard about the work of Stephen Bax was to try to capture the patterns of the text using word2vec. Word embeddings are created by using a shallow neural network architecture. It is a unsupervised technique that uses supervided learning tasks to learn the linguistic context of the words. Here is a visualization of this architecture from the TensorFlow site:
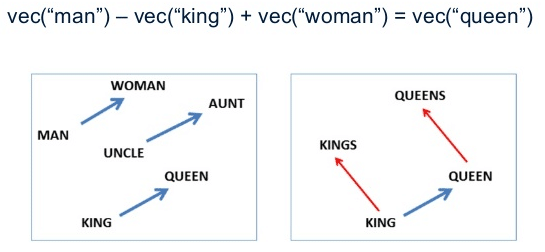
These word vectors, after trained, carry with them a lot of semantic meaning. For instance:
We can see that those vectors can be used in vector operations to extract information about the regularities of the captured linguistic semantics. These vectors also approximates same-meaning words together, allowing similarity queries like in the example below:
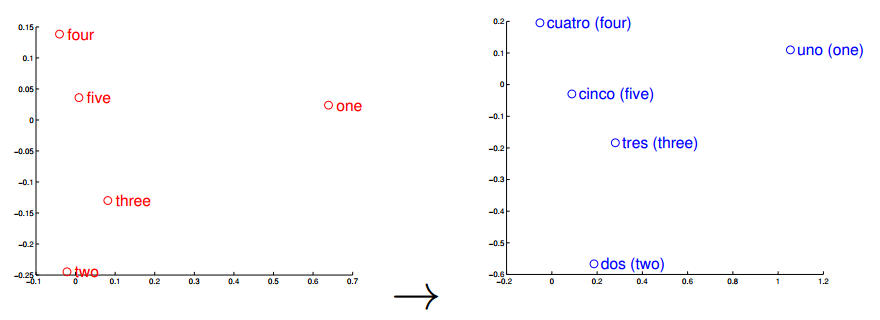
Word vectors can also be used (surprise) for translation, and this is the feature of the word vectors that I think that its most important when used to understand text where we know some of the words translations. I pretend to try to use the words found by Stephen Bax in the future to check if it is possible to capture some transformation that could lead to find similar structures with other languages. A nice visualization of this feature is the one below from the paper “Exploiting Similarities among Languages for Machine Translation“:
This visualization was made using gradient descent to optimize a linear transformation between the source and destination language word vectors. As you can see, the structure in Spanish is really close to the structure in English.
EVA Transcription
To train this model, I had to parse and extract the transcription from the EVA (European Voynich Alphabet) to be able to feed the Voynich sentences into the word2vec model. This EVA transcription has the following format:
The first data between “<” and “>” has information about the folio (page), line and author of the transcription. The transcription block above is the transcription for the first two lines of the first folio of the manuscript below:
Part of the “f1r”
As you can see, the EVA contains some code characters, like for instance “!”, “*” and they all have some meaning, like to inform that the author doing that translation is not sure about the character in that position, etc. EVA also contains transcription from different authors for the same line of the folio.
To convert this transcription to sentences I used only lines where the authors were sure about the entire line and I used the first line where the line satisfied this condition. I also did some cleaning on the transcription to remove the drawings names from the text, like: “text.text.text-{plant}text” -> “text text texttext”.
After this conversion from the EVA transcript to sentences compatible with the word2vec model, I trained the model to provide 100-dimensional word vectors for the words of the manuscript.
Vector space visualizations using t-SNE
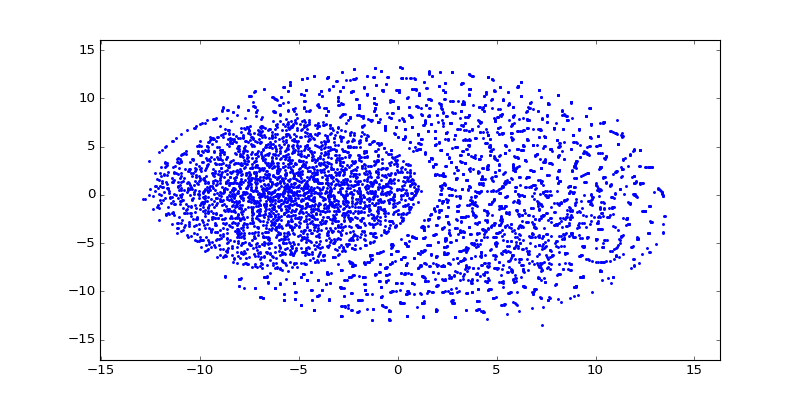
After training word vectors, I created a visualization of the 100-dimensional vectors into a 2D embedding space using t-SNE algorithm:
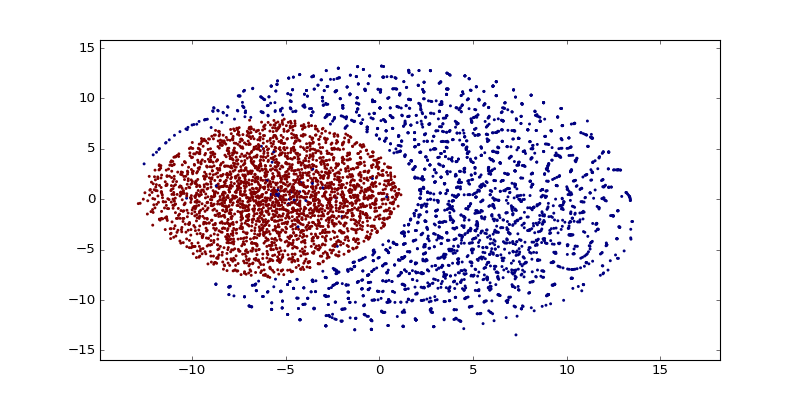
As you can see there are a lot of small clusters and there visually two big clusters, probably accounting for the two different languages used in the Codex (I still need to confirm this regarding the two languages aspect). After clustering it with DBSCAN (using the original word vectors, not the t-SNE transformed vectors), we can clearly see the two major clusters:
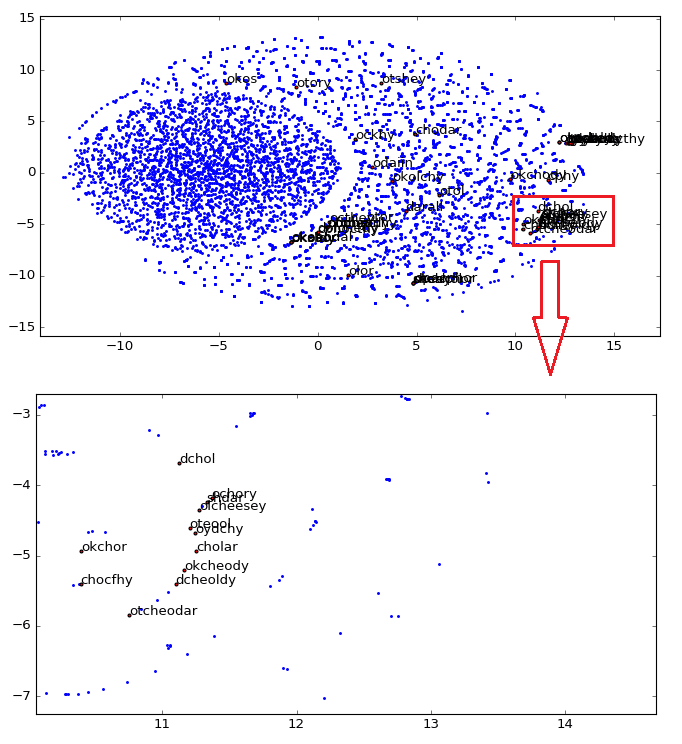
Now comes the really interesting and useful part of the word vectors, if use a star name from the folio below (it’s pretty obvious why it is know that this is probably a star name):
I get really interesting similar words, like for instance the ocphy and other close star names:
It also returns the word “qoekaiin” from the folio 48, that precedes the same star name:
As you can see, word vectors are really useful to find some linguistic structures, we can also create another plot, showing how close are the star names in the 2D embedding space visualization created using t-SNE:
As you can see, we zoomed the major cluster of stars and we can see that they are really all grouped together in the vector space. These representations can be used for instance to infer plat names from the herbal section, etc.
My idea was to show how useful word vectors are to analyze unknown codex texts, I hope you liked and I hope that this could be somehow useful for other people how are also interested in this amazing manuscript.
This website uses cookies to improve your experience. We'll assume you're ok with this, but you can opt-out if you wish. Cookie settingsACCEPT
Privacy & Cookies Policy
Privacy Overview
This website uses cookies to improve your experience while you navigate through the website. Out of these cookies, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may have an effect on your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.





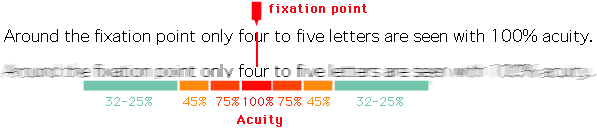




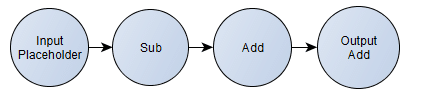
-5)+100)") , where I intentionally added redundant operations to see LLVM constant propagation later.
, where I intentionally added redundant operations to see LLVM constant propagation later.