You know, Python represents every object using the low-level C API PyObject (or PyVarObject for variable-size objects) structure, so, concretely, you can cast any Python object pointer to this type; this inheritance is built by hand, every new object must have a leading macro called PyObject_HEAD which defines the PyObject header for the object. The PyObject structure is declared in Include/object.h as:
[enlighter lang=”c”]
typedef struct _object {
PyObject_HEAD
} PyObject;
[/enlighter]
and the PyObject_HEAD macro is defined as:
[enlighter lang=”c”]
#define PyObject_HEAD \
_PyObject_HEAD_EXTRA \
Py_ssize_t ob_refcnt; \
struct _typeobject *ob_type;
[/enlighter]
… with two fields (forget the _PyObject_HEAD_EXTRA, it’s only used for a tracing debug feature) called ob_refcnt and ob_type, representing the reference counting for the object and the type of the object. I know you can use sys.getrefcount to get the reference counting of an object, but hacking the object memory using ctypes is by far more powerful, since you can get the contents of any field of the object (in cases where you don’t have a native API for that), I’ll show more examples later, but lets focus on the reference counting field of the object.
Getting the reference count (ob_refcnt)
So, in Python, we have the built-in function id(), this function returns the identity of the object, but, looking at its definition on CPython implementation, you’ll notice that id() returns the memory address of the object, see the source in Python/bltinmodule.c:
[enlighter lang=”c”]
static PyObject *
builtin_id(PyObject *self, PyObject *v)
{
return PyLong_FromVoidPtr(v);
}
[/enlighter]
… the function PyLong_FromVoidPtr returns a Python long object from a void pointer. So, in CPython, this value is the address of the object in the memory as shown below:
[enlighter lang=”python”]
>>> value = 666
>>> hex(id(value))
‘0x8998e50’ # memory address of the ‘value’ object
[/enlighter]
Now that we have the memory address of the object, we can use the Python ctypes module to get the reference counting by accessing the attribute ob_refcnt, here is the code needed to do that:
[enlighter lang=”python”]
>>> value = 666
>>> value_address = id(value)
>>>
>>> ob_refcnt = ctypes.c_long.from_address(value_address)
>>> ob_refcnt
c_long(1)
[/enlighter]
What I’m doing here is getting the integer value from the ob_refcnt attribute of the PyObject in memory. Let’s add a new reference for the object ‘value’ we created, and then check the reference count again:
[enlighter lang=”python”]
>>> value_ref = value
>>> id(value_ref) == id(value)
True
>>> ob_refcnt
c_long(2)
[/enlighter]
Note that the reference counting was increased by 1 due to the new reference variable called ‘value_ref’.
Interned strings state (ob_sstate)
Now, getting the reference count wasn’t even funny, we already had the sys.getrefcount API for that, but what about the interned state of the strings ? In order to avoid the creation of different allocations for the same string (and to speed comparisons), Python uses a dictionary that works like a “cache” for strings, this dictionary is defined in Objects/stringobject.c:
[enlighter lang=”c”]
/* This dictionary holds all interned strings. Note that references to
strings in this dictionary are *not* counted in the string’s ob_refcnt.
When the interned string reaches a refcnt of 0 the string deallocation
function will delete the reference from this dictionary.
Another way to look at this is that to say that the actual reference
count of a string is: s->ob_refcnt + (s->ob_sstate?2:0)
*/
static PyObject *interned;
[/enlighter]
I also copied here the comment about the dictionary, because is interesting to note that the strings in the dictionary aren’t counted in the string’s ob_refcnt.
So, the interned state of a string object is hold in the attribute ob_sstate of the string object, let’s see the definition of the Python string object:
[enlighter lang=”c”]
typedef struct {
PyObject_VAR_HEAD
long ob_shash;
int ob_sstate;
char ob_sval[1];
/* Invariants:
* ob_sval contains space for ‘ob_size+1’ elements.
* ob_sval[ob_size] == 0.
* ob_shash is the hash of the string or -1 if not computed yet.
* ob_sstate != 0 iff the string object is in stringobject.c’s
* ‘interned’ dictionary; in this case the two references
* from ‘interned’ to this object are *not counted* in ob_refcnt.
*/
} PyStringObject;
[/enlighter]
As you can note, strings objects inherit from the PyObject_VAR_HEAD macro, which defines another header attribute, let’s see the definition to get the complete idea of the structure:
[enlighter lang=”c”]
#define PyObject_VAR_HEAD \
PyObject_HEAD \
Py_ssize_t ob_size; /* Number of items in variable part */
[/enlighter]
The PyObject_VAR_HEAD macro adds another field called ob_size, which is the number of items on the variable part of the Python object (i.e. the number of items on a list object). So, before getting to the ob_sstate field, we need to shift our offset to skip the fields ob_refcnt (long), ob_type (void*) (from PyObject_HEAD), the field ob_size (long) (from PyObject_VAR_HEAD) and the field ob_shash (long) from the PyStringObject. Concretely, we need to skip this offset (3 fields with size long and one field with size void*) of bytes:
[enlighter lang=”python”]
>>> ob_sstate_offset = ctypes.sizeof(ctypes.c_long)*3 + ctypes.sizeof(ctypes.c_voidp)
>>> ob_sstate_offset
16
[/enlighter]
Now, let’s prepare two cases, one that we know that isn’t interned and another that is surely interned, then we’ll force the interned state of the other non-interned string to check the result of the ob_sstate attribute:
[enlighter lang=”python”]
>>> a = “lero”
>>> b = “”.join([“l”, “e”, “r”, “o”])
>>> ctypes.c_long.from_address(id(a) + ob_sstate_offset)
c_long(1)
>>> ctypes.c_long.from_address(id(b) + ob_sstate_offset)
c_long(0)
>>> ctypes.c_long.from_address(id(intern(b)) + ob_sstate_offset)
c_long(1)
[/enlighter]
Note that the interned state for the object “a” is 1 and for the object “b” is 0. After forcing the interned state of the variable “b”, we can see that the field ob_sstate has changed to 1.
Changing internal states (evil mode)
Now, let’s suppose we want to change some internal state of a Python object through the interpreter. Let’s try to change the value of an int object. Int objects are defined in Include/intobject.h:
[enlighter lang=”c”]
typedef struct {
PyObject_HEAD
long ob_ival;
} PyIntObject;
[/enlighter]
As you can see, the internal value of an int is stored in the field ob_ival, to change it, we just need to skip the ob_refcnt (long) and the ob_type (void*) from the PyObject_HEAD:
[enlighter lang=”python”]
>>> value = 666
>>> ob_ival_offset = ctypes.sizeof(ctypes.c_long) + ctypes.sizeof(ctypes.c_voidp)
>>> ob_ival = ctypes.c_int.from_address(id(value)+ob_ival_offset)
>>> ob_ival
c_long(666)
>>> ob_ival.value = 8
>>> value
8
[/enlighter]
And that is it, we have changed the value of the int value directly in the memory.
I hope you liked it, you can play with lots of other Python objects like lists and dicts, note that this method is just intended to show how the Python objects are structured in the memory and how you can change them using the native API, but obviously, you’re not supposed to use this to change the value of ints lol.
Update 11/29/11: you’re not supposed to do such things on your production code or something like that, in this post I’m doing lazy assumptions about arch details like sizes of primitives, etc. Be warned.
") which is actually the term count of the term
which is actually the term count of the term  in the document
in the document  . The use of this simple term frequency could lead us to problems like keyword spamming, which is when we have a repeated term in a document with the purpose of improving its ranking on an IR (Information Retrieval) system or even create a bias towards long documents, making them look more important than they are just because of the high frequency of the term in the document.
. The use of this simple term frequency could lead us to problems like keyword spamming, which is when we have a repeated term in a document with the purpose of improving its ranking on an IR (Information Retrieval) system or even create a bias towards long documents, making them look more important than they are just because of the high frequency of the term in the document. that we have calculated in the first part of this tutorial. The document
that we have calculated in the first part of this tutorial. The document  from the first part of this tutorial had this textual representation:
from the first part of this tutorial had this textual representation:")
 . The definition of the unit vector
. The definition of the unit vector  is:
is:
 is the norm (magnitude, length) of the vector
is the norm (magnitude, length) of the vector  space (don’t worry, I’m going to explain it all).
space (don’t worry, I’m going to explain it all).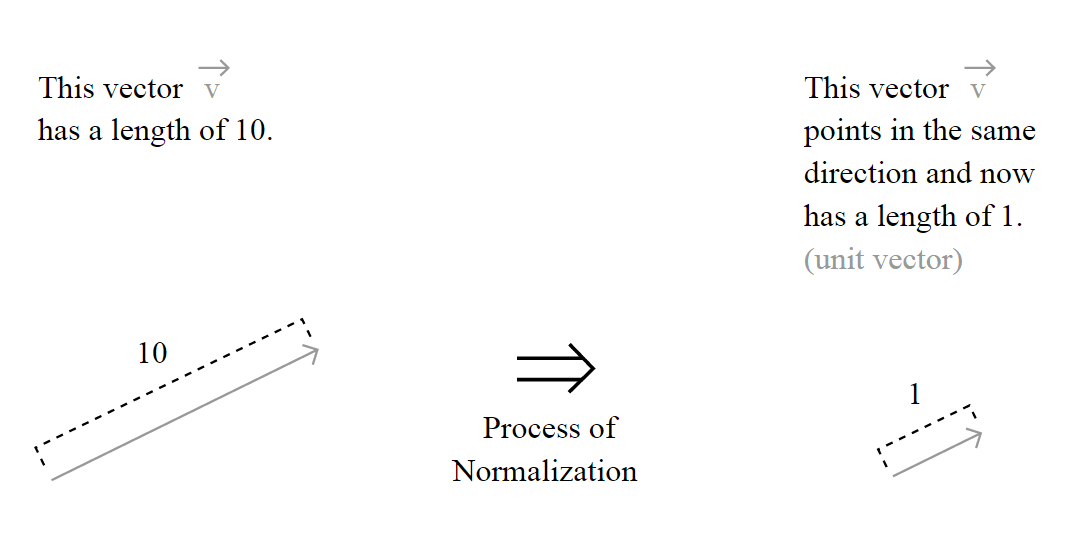
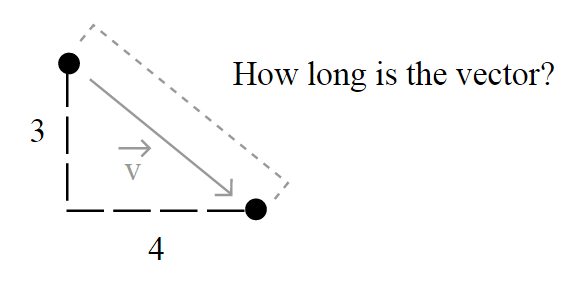
") is calculated using the
is calculated using the 

 together with the norm notation, like in
together with the norm notation, like in  . That’s because it could be generalized as:
. That’s because it could be generalized as:^\frac{1}{p}")
^\frac{1}{p}")
 , the most common norm used to measure the length of a vector, typically called “magnitude”; actually, when you have an unqualified length measure (without the
, the most common norm used to measure the length of a vector, typically called “magnitude”; actually, when you have an unqualified length measure (without the  , defined as:
, defined as:")

 , and is the unique shortest path.
, and is the unique shortest path. . To do that, we’ll simple plug it into the definition of the unit vector to evaluate it:
. To do that, we’ll simple plug it into the definition of the unit vector to evaluate it:}{\sqrt{0^2 + 2^2 + 1^2 + 0^2}} \\ \\ \hat{v_{d_4}} = \frac{(0,2,1,0)}{\sqrt{5}} \\ \\ \small \hat{v_{d_4}} = (0.0, 0.89442719, 0.4472136, 0.0)")
 .
. where
where  is the number of documents in your corpus, and in our case as
is the number of documents in your corpus, and in our case as  and
and  . The cardinality of our document space is defined by
. The cardinality of our document space is defined by  and
and  , since we have only 2 two documents for training and testing, but they obviously don’t need to have the same cardinality.
, since we have only 2 two documents for training and testing, but they obviously don’t need to have the same cardinality. = \log{\frac{\left|D\right|}{1+\left|\{d : t \in d\}\right|}}")
 is the number of documents where the term
is the number of documents where the term  \neq 0") , we’re only adding 1 into the formula to avoid zero-division.
, we’re only adding 1 into the formula to avoid zero-division. = \mathrm{tf}(t, d) \times \mathrm{idf}(t)")

") ,
, ") ,
, ") ,
, ") :
: = \log{\frac{\left|D\right|}{1+\left|\{d : t_1 \in d\}\right|}} = \log{\frac{2}{1}} = 0.69314718")
 = \log{\frac{\left|D\right|}{1+\left|\{d : t_2 \in d\}\right|}} = \log{\frac{2}{3}} = -0.40546511")
 = \log{\frac{\left|D\right|}{1+\left|\{d : t_3 \in d\}\right|}} = \log{\frac{2}{3}} = -0.40546511")
 = \log{\frac{\left|D\right|}{1+\left|\{d : t_4 \in d\}\right|}} = \log{\frac{2}{2}} = 0.0")
")
 ) and the vector representing the idf for each feature of our matrix (
) and the vector representing the idf for each feature of our matrix ( ), we can calculate our tf-idf weights. What we have to do is a simple multiplication of each column of the matrix
), we can calculate our tf-idf weights. What we have to do is a simple multiplication of each column of the matrix  with both the vertical and horizontal dimensions equal to the vector
with both the vertical and horizontal dimensions equal to the vector 

 will be different than the result of the
will be different than the result of the  , and this is why the
, and this is why the  & \mathrm{tf}(t_2, d_1) & \mathrm{tf}(t_3, d_1) & \mathrm{tf}(t_4, d_1)\\ \mathrm{tf}(t_1, d_2) & \mathrm{tf}(t_2, d_2) & \mathrm{tf}(t_3, d_2) & \mathrm{tf}(t_4, d_2) \end{bmatrix} \times \begin{bmatrix} \mathrm{idf}(t_1) & 0 & 0 & 0\\ 0 & \mathrm{idf}(t_2) & 0 & 0\\ 0 & 0 & \mathrm{idf}(t_3) & 0\\ 0 & 0 & 0 & \mathrm{idf}(t_4) \end{bmatrix} \\ = \begin{bmatrix} \mathrm{tf}(t_1, d_1) \times \mathrm{idf}(t_1) & \mathrm{tf}(t_2, d_1) \times \mathrm{idf}(t_2) & \mathrm{tf}(t_3, d_1) \times \mathrm{idf}(t_3) & \mathrm{tf}(t_4, d_1) \times \mathrm{idf}(t_4)\\ \mathrm{tf}(t_1, d_2) \times \mathrm{idf}(t_1) & \mathrm{tf}(t_2, d_2) \times \mathrm{idf}(t_2) & \mathrm{tf}(t_3, d_2) \times \mathrm{idf}(t_3) & \mathrm{tf}(t_4, d_2) \times \mathrm{idf}(t_4) \end{bmatrix}")

 matrix. Please note that this normalization is “row-wise” because we’re going to handle each row of the matrix as a separated vector to be normalized, and not the matrix as a whole:
matrix. Please note that this normalization is “row-wise” because we’re going to handle each row of the matrix as a separated vector to be normalized, and not the matrix as a whole:

 and
and  from the document set, we’ll have the following index vocabulary denoted as
from the document set, we’ll have the following index vocabulary denoted as ") where the
where the  = \begin{cases} 1, & \mbox{if } t\mbox{ is ``blue''} \\ 2, & \mbox{if } t\mbox{ is ``sun''} \\ 3, & \mbox{if } t\mbox{ is ``bright''} \\ 4, & \mbox{if } t\mbox{ is ``sky''} \\ \end{cases}")
 or
or  = \sum\limits_{x\in d} \mathrm{fr}(x, t)")
") is a simple function defined as:
is a simple function defined as: = \begin{cases} 1, & \mbox{if } x = t \\ 0, & \mbox{otherwise} \\ \end{cases}")
") returns is how many times is the term
returns is how many times is the term  = 2") since we have only two occurrences of the term “sun” in the document
since we have only two occurrences of the term “sun” in the document , \mathrm{tf}(t_2,d_n), \mathrm{tf}(t_3,d_n), \ldots, \mathrm{tf}(t_n,d_n))")
") represents the frequency-term of the term 1 or
represents the frequency-term of the term 1 or  (which is our “blue” term of the vocabulary) in the document
(which is our “blue” term of the vocabulary) in the document  .
. and
and  are represented as vectors:
are represented as vectors:, \mathrm{tf}(t_2,d_3), \mathrm{tf}(t_3,d_3), \ldots, \mathrm{tf}(t_n,d_3)) \\ \vec{v_{d_4}} = (\mathrm{tf}(t_1,d_4), \mathrm{tf}(t_2,d_4), \mathrm{tf}(t_3,d_4), \ldots, \mathrm{tf}(t_n,d_4))")
 \\ \vec{v_{d_4}} = (0, 2, 1, 0)")
 shows that we have, in order, 0 occurrences of the term “blue”, 1 occurrence of the term “sun”, and so on. In the
shows that we have, in order, 0 occurrences of the term “blue”, 1 occurrence of the term “sun”, and so on. In the  shape, where
shape, where  is the cardinality of the document space, or how many documents we have and the
is the cardinality of the document space, or how many documents we have and the  is the number of features, in our case represented by the vocabulary size. An example of the matrix representation of the vectors described above is:
is the number of features, in our case represented by the vocabulary size. An example of the matrix representation of the vectors described above is:
") (except because it is zero-indexed).
(except because it is zero-indexed). we cited earlier in this post, which represents the two document vectors
we cited earlier in this post, which represents the two document vectors 
