Introduction
 It is not a secret that Diffusion models have become the workhorses of high-dimensionality generation: start with a Gaussian noise and, through a learned denoising trajectory, you get high-fidelity images, molecular graphs, or robot trajectories that look (uncannily) real. I wrote extensively about diffusion and its connection with the data manifold metric tensor recently as well, so if you are interested please take a look on it.
It is not a secret that Diffusion models have become the workhorses of high-dimensionality generation: start with a Gaussian noise and, through a learned denoising trajectory, you get high-fidelity images, molecular graphs, or robot trajectories that look (uncannily) real. I wrote extensively about diffusion and its connection with the data manifold metric tensor recently as well, so if you are interested please take a look on it.
Now, for many engineering and practical tasks we care less about “looking real” and more about maximising a task-specific score or a reward from a simulator, a chemistry docking metric, a CLIP consistency score, human preference, etc. Even though we can use guidance or do a constrained sampling from the model, we often require differentiable functions for that. Evolution-style search methods (CEM, CMA-ES, etc), however, can shine in that regime, but naively applying them in the raw object space wastes most samples on absurd or invalid candidates and takes a lot of time to converge to a reasonable solution.
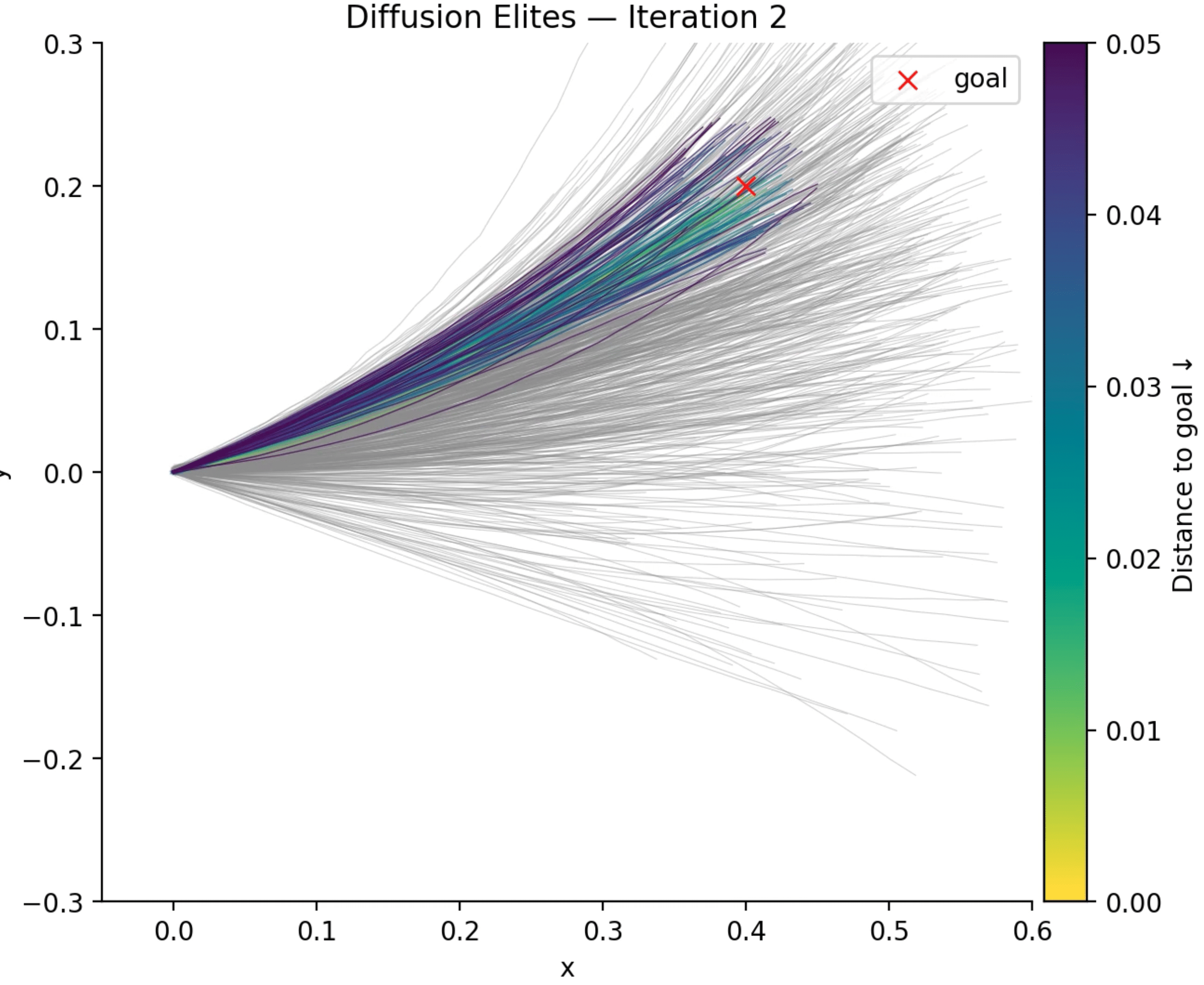
I have been experimenting on some personal projects with something that we can call “Diffusion Elites“, which aims to close this gap by letting a pre-trained diffusion model provide the prior and letting an adapted Cross-Entropy Method (CEM) steer the search inside its latent space instead. I found that this works quite well for many domains and it is also an impressively flexible method with a lot to explore (I will talk about some cases later).
To summarize, the method is as simple as the following:
- Draw a population of latent vectors from a Gaussian
- Run one full denoise pass to turn each latent into a structured object
- Score every object with any reward function
- Keep the top-K “elite” latents, refit a new Gaussian to them, and iterate
This five-line loop inherits the robust, gradient-free advantages of evolutionary search while guaranteeing that every candidate lives on the diffusion model’s data manifold. In practice that means fewer wasted evaluations, faster convergence, and dramatically higher-quality solutions for many tasks (e.g. planning, design, etc). In the rest of this post I will unpack the Diffusion Elites in detail, from the algorithm to some coding examples. Diffusion Elites shows that you can explore a diffusion model and turn it into a powerful black box optimizer, it is like doing search on the data manifold itself.
Diffusion Elites
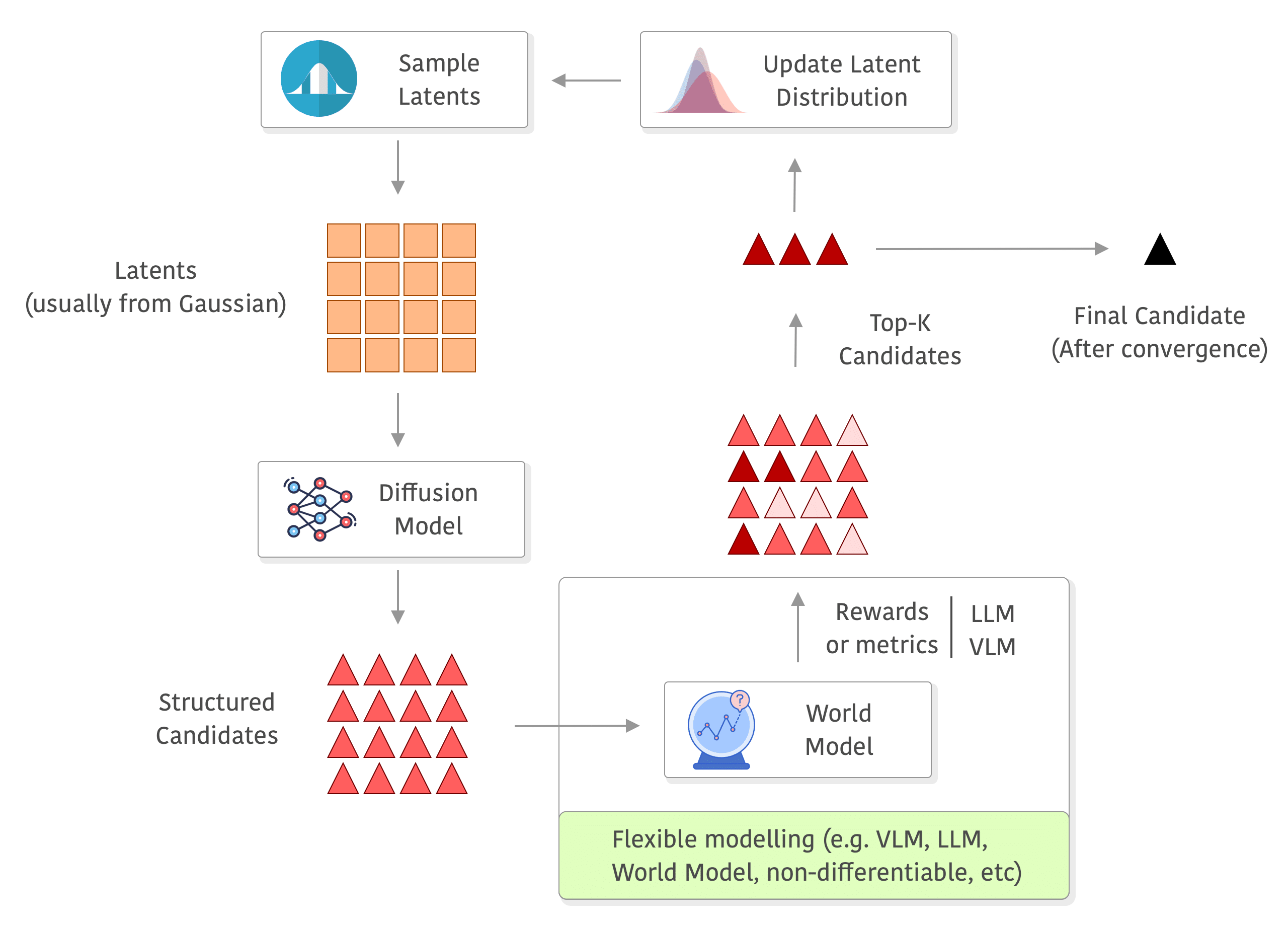
Overview diagram
Below you can see a diagram of the process, I added a world model in the rewards to exemplify how you can use a world model and even do roll-outs there without any differentiability requirements, but you can really use anything to compute your rewards (e.g. you can also compute metrics on the outputs of the world model, or use a VLM/LLM as judge or even as world model as well):