Just sharing some recent publications I’ve been involved recently:
L2M: Practical posterior Laplace approximation with optimization-driven second moment estimation
ArXiv: https://arxiv.org/abs/2107.04695 (ICML 2021 / UDL)
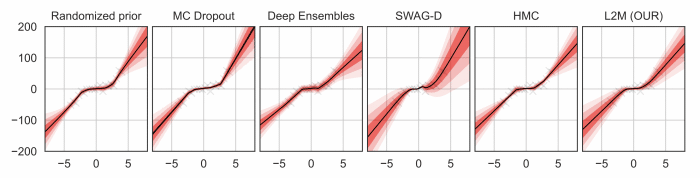
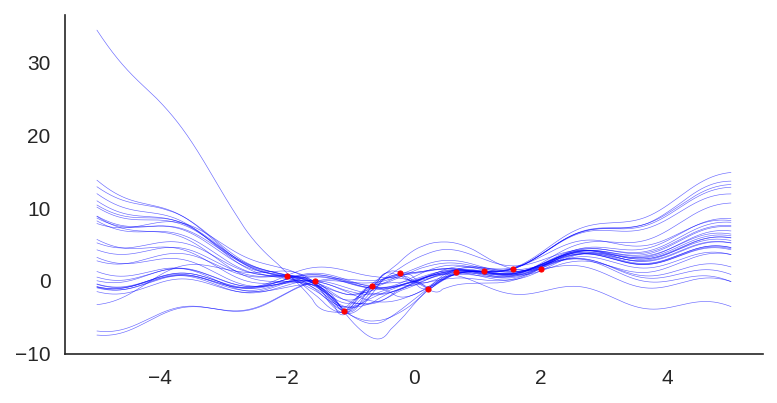
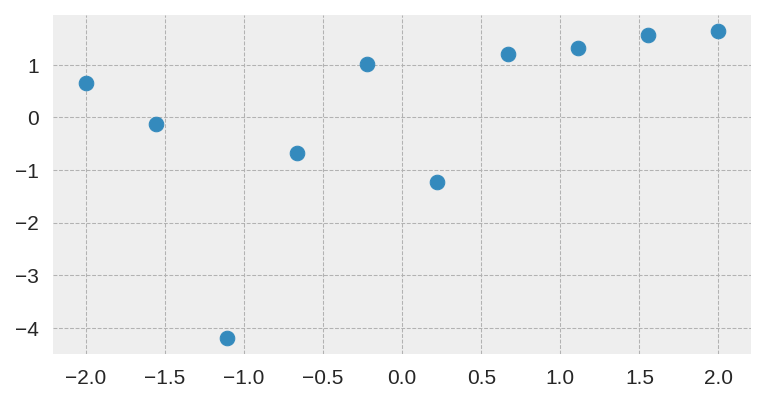
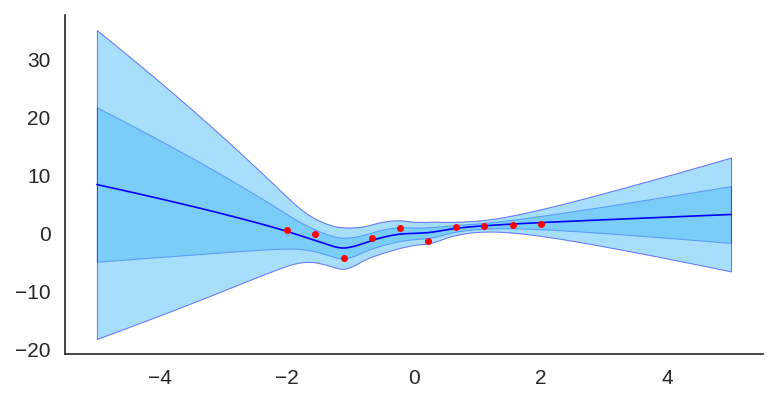
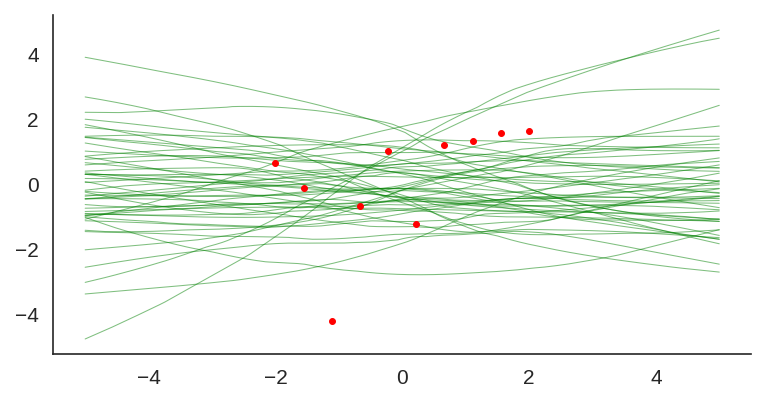
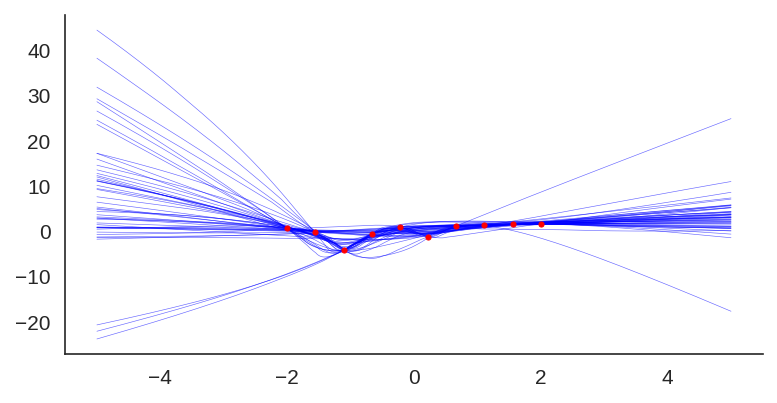
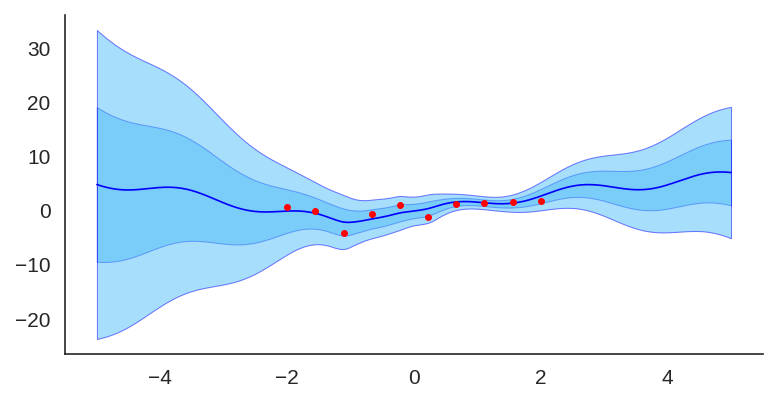
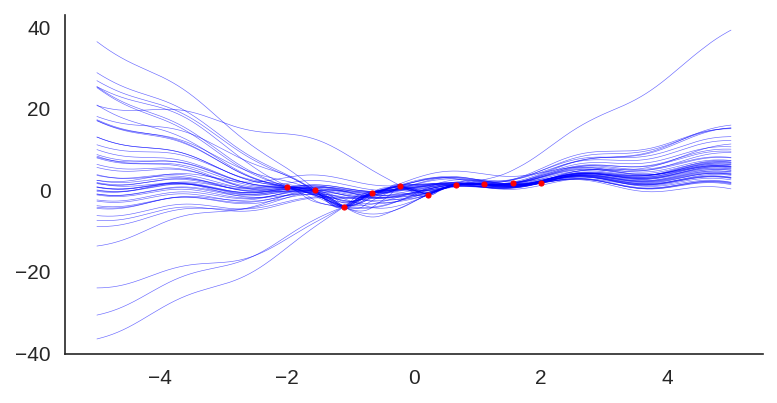
Uncertainty quantification for deep neural networks has recently evolved through many techniques. In this work, we revisit Laplace approximation, a classical approach for posterior approximation that is computationally attractive. However, instead of computing the curvature matrix, we show that, under some regularity conditions, the Laplace approximation can be easily constructed using the gradient second moment. This quantity is already estimated by many exponential moving average variants of Adagrad such as Adam and RMSprop, but is traditionally discarded after training. We show that our method (L2M) does not require changes in models or optimization, can be implemented in a few lines of code to yield reasonable results, and it does not require any extra computational steps besides what is already being computed by optimizers, without introducing any new hyperparameter. We hope our method can open new research directions on using quantities already computed by optimizers for uncertainty estimation in deep neural networks.
CW-ERM: Improving Autonomous Driving Planning with Closed-loop Weighted Empirical Risk Minimization
ArXiv: https://arxiv.org/abs/2210.02174 (NeurIPS 2022 / ML4AD / ICRA 2023 under review)
Project page: https://woven.mobi/cw-erm
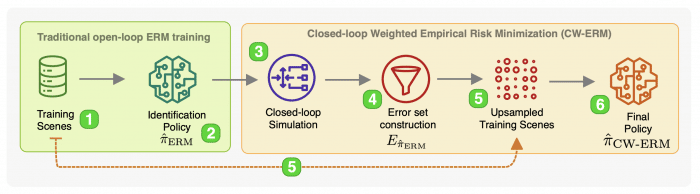
The imitation learning of self-driving vehicle policies through behavioral cloning is often carried out in an open-loop fashion, ignoring the effect of actions to future states. Training such policies purely with Empirical Risk Minimization (ERM) can be detrimental to real-world performance, as it biases policy networks towards matching only open-loop behavior, showing poor results when evaluated in closed-loop. In this work, we develop an efficient and simple-to-implement principle called Closed-loop Weighted Empirical Risk Minimization (CW-ERM), in which a closed-loop evaluation procedure is first used to identify training data samples that are important for practical driving performance and then we these samples to help debias the policy network. We evaluate CW-ERM in a challenging urban driving dataset and show that this procedure yields a significant reduction in collisions as well as other non-differentiable closed-loop metrics.
SafePathNet: Safe Real-World Autonomous Driving by Learning to Predict and Plan with a Mixture of Experts
ArXiv: https://arxiv.org/abs/2211.02131 (NeurIPS 2022 / ML4AD / ICRA 2023 under review)
Project page: https://woven.mobi/safepathnet
The goal of autonomous vehicles is to navigate public roads safely and comfortably. To enforce safety, traditional planning approaches rely on handcrafted rules to generate trajectories. Machine learning-based systems, on the other hand, scale with data and are able to learn more complex behaviors. However, they often ignore that agents and self-driving vehicle trajectory distributions can be leveraged to improve safety. In this paper, we propose modeling a distribution over multiple future trajectories for both the self-driving vehicle and other road agents, using a unified neural network architecture for prediction and planning. During inference, we select the planning trajectory that minimizes a cost taking into account safety and the predicted probabilities. Our approach does not depend on any rule-based planners for trajectory generation or optimization, improves with more training data and is simple to implement. We extensively evaluate our method through a realistic simulator and show that the predicted trajectory distribution corresponds to different driving profiles. We also successfully deploy it on a self-driving vehicle on urban public roads, confirming that it drives safely without compromising comfort.