Nota sobre o estudo da UFPel no Rio Grande do Sul
* This post is in Portuguese.
Introdução
Resolvi escrever esta nota sobre o estudo de prevalência de anticorpos (seroprevalence) que a UFPel está realizando no Rio Grande do Sul, pois parece haver um grande desentendimento por parte da população, principalmente por parte dos jornalistas em relação aos números reportados pelos pesquisadores da UFPel.
Para começar, minha opinião foi e continua sendo (até a data de hoje) de que a UFPel tem feito um péssimo trabalho de divulgação científica, e gostaria de deixar claro que não estou criticando o estudo, mas sim a divulgação que está sendo feita nas coletivas. Infelizmente, para não dizer lamentavelmente, os pesquisadores da UFPel parecem não ter entendido a crítica que fiz no dia 15 de Abril e acabaram descaracterizando completamente o argumento ao responder de forma anti-ética na live que fizeram no dia 21 de Abril (ver aos 59 min do vídeo) onde comentaram que eu estaria “deslumbrado” e que queria “lacrar“, pois entenderam que eu havia dito que eles não haviam pensado sobre o intervalo de confiança, quando na verdade a minha crítica era sobre a omissão da comunicação não só deste intervalo como também da incerteza associada com o kit de teste que eles estão utilizando.
Honestamente não consegui entender porque usaram um argumento ad hominem para responder a minha crítica, deboche não deveria fazer parte da ciência e do diálogo científico. Tive também inúmeros “carteiraços” também no Twitter por parte de outros professores da UFPel e outros:
Do you really want to teach the best epidemiologists in the country on confidence intervals and test validity? A press presentation is different from a scientific report.
— paulo r. ferreira jr (@pferreirajr) April 15, 2020
you are blantantly wrong assuming that a doc that you got is THE document. Worse, you talked down to a team led by Dr. Cesar Victora and his world class recognized epidemiologic research. Pls, humbly, do your homework and reach out the Survey’s leaders. I can help if you want.
— jcesarmartins (@jcesarmartins) April 16, 2020
Toda vez que eu leio sobre estes argumentos de autoridade, eu lembro que foi Karl Popper que felizmente teve o grande insight de que o conhecimento é sujeito a avaliação competitiva e deve ser revisada por pares e por comunidades independentes. Ciência não é sobre autoridade, sobre quem é melhor ou não no país, mas sim sobre evidência, e a evidência inclui incerteza e devemos comunicá-la com rigor científico, estamos falando de um estudo que impacta políticas de saúde pública e vidas.
Torturando os números
Mas vamos ao que interessa, que é a parte técnica. Primeiramente a UFPel apresentou o seguinte slide na coletiva:

Onde alertam sobre “números pequenos”, seja lá o que um “número pequeno” significa, pois ao invés de adotar aqui rigor científico, deixaram margem para a subjetividade. Apesar de este alerta ser importante (dado que se entenda o que ele quer dizer), ele não ajuda em nada porque logo depois temos os slides apresentando os resultados e ignorando detalhes importantes que vou comentar a seguir:
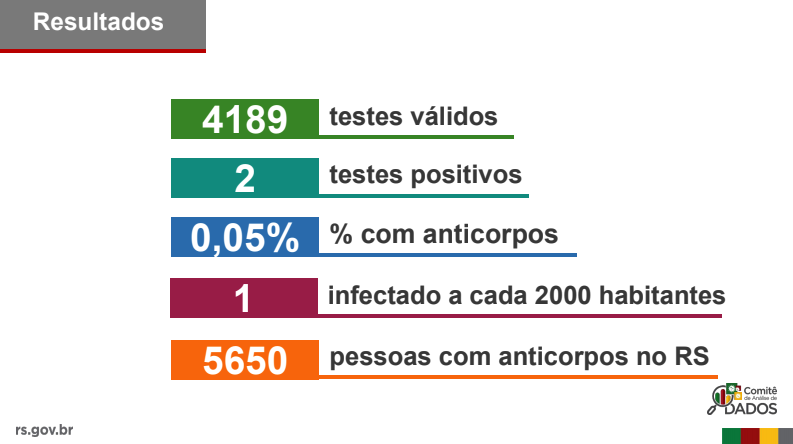
Aqui é onde começam os graves problemas que acabaram gerando uma série de notícias e desinformação que fez com que o público interpretasse estes resultados sem ter a informação completa. Segue uma pequena lista de algumas notícias que foram divulgadas depois desta coletiva:
- Revista Pesquisa Fapesp:
- “Rio Grande do Sul pode ter 7,5 vezes mais casos do que o confirmado”
- Notícia da própria UFPel:
- “Dos 4189 testes validados pelos pesquisadores, dois testes confirmaram positivo, cerca de 0,05% da população gaúcha deve ter sido contaminada.”
- Jornal O Nacional:
- “Estudo estima que RS tenha 5.650 pessoas infectadas pela Covid-19”
- Diário da Manhã:
- “Estudo estima que RS tenha mais de 5.600 pessoas infectadas pela Covid-19”
- Notícia da UNISC:
- “(…) estima-se que há um infectado a cada dois mil habitantes do estado, podendo existir 5650 pessoas que estão ou já estiveram infectadas com o vírus (…)”
E tantas outras notícias de outros jornais, que passaram a veicular estes números da UFPel.
Mas o que há de errado nestes resultados que foram anunciados ? Segue uma lista:
- Arredondamento grosseiro da proporção (0.05%) estimada:
- Este arredondamento pode parecer pequeno, mas já vamos ver qual é o problema;
- Omissão de erro amostral:
- Até enquetes de eleições apresentam incertezas do erro amostral, mas uma pesquisa que vai impactar em política de saúde pública não apresenta isto para imprensa ?
- Ignoraram as características dos testes nestes resultados:
- Sabemos que os testes tem características como sensibilidade e especificidade, e apesar de terem feito validações, não propagaram as incertezas destes testes nos resultados apresentados. No meu ponto de vista, este é um dos piores erros cometidos;
- Constante política que permeia as coletivas:
- Na segunda coletiva da UFPel, eles constantemente falam que o estudo é “único no mundo”, mas ignoram estudos como por exemplo o de Miami que finalizou a segunda etapa no dia 24 de Abril, portanto não é verdade que o estudo é “inédito” ou “único no mundo”. Este tipo de comentário pode gerar um bom marketing para a universidade, mas não devemos ignorar outros estudos em prol da política universitária ou orgulho acadêmico;
- Falta de transparência (open science):
- Os pesquisadores já estão na segunda fase do estudo e ainda não divulgaram dados como por exemplo o número de amostras que utilizaram para fazer a validação dos testes que utilizaram, e tantos outros micro-dados anonimizados que poderiam ser divulgados para que outros pesquisadores possam avançar em outras análises. Há uma demora muito grande para a divulgação destes dados e já estou sem esperanças que este estudo divulgue algo além dos slides apresentados na coletiva antes de acabarem o estudo;
Vou falar de cada um dos pontos acima e depois fazer uma análise prática mostrando alguns números muito diferentes da UFPel. Nesta análise tive que ignorar alguns aspectos como por exemplo os ajustes demográficos porque como comentei, a UFPel não divulgou detalhes do estudo.
Arredondamentos grosseiros
Quando se estima prevalência, estima-se uma proporção. No caso da UFPel, se fizermos uma conta muito simples, veremos que a proporção correta não é 0.05% mas sim 0.047%. Por que estou utilizando uma precisão maior e evitando arredondamento ? Pelo simples motivo de que esta proporção é multiplicada posteriormente pela população inteira para se extrapolar o resultado da amostragem para a população. E sabemos que o número da população não é um número pequeno, no RS temos uma população estimada de 11.300.000 de habitantes. Ou seja, um arredondamento pequeno pode inflacionar artificialmente o número de infectados. Ao multiplicarmos a população pela proporção:

Chegamos ao número que a UFPel divulgou como estimado número de infectados. Mas, ao multiplicarmos pela proporção correta, temos:

Portanto temos uma inflação artificial de 255 infectados a mais, que surgiram magicamente ao se arredondar números que não se devem ser arredondados. Esta quantidade de infectados pode não parecer um número grande, mas ao colocarmos 255 infectados em uma população e utilizarmos o número de reprodução básico (R0) estimado do SARS-CoV-2, o impacto destes infectados em uma população, definitivamente não é insignificante. Parece aqui que a UFPel não lembrou do próprio conselho que apresentou no slide anterior: “devermos ter cuidado quando os números são pequenos”.
Modelando erro amostral
Quando fazemos uma amostragem de uma população, as quantidades estatísticas estimadas para esta amostragem podem não representar a as mesmas quantidades da população. Aumentando o tamanho da amostra, conseguimos reduzir este erro, porém é obviamente proibitivo fazer isto quando não temos nem testes suficientes no Brasil para grupos de risco, quanto mais para uma amostra grande de assintomáticos. Portanto em estudos de prevalência temos que conviver com estes erros, que geralmente são grandes pelo fato das amostras representarem apenas uma pequena parcela da população total. Novamente, não estou aqui criticando que a UFPel não irá fazer isto no estudo final, ou que não pensou sobre estes intervalos de confiança, minha crítica é que não apresentaram estes intervalos na primeira coletiva.
Para estimar esse erro amostral, vou fazer uma modelagem bayesiana simples utilizando um prior não-informativo. Como estamos estimando valores discretos de número de testes positivos dado uma quantidade de ensaios, utilizei a distribuição binomial \(\text{Binomial}(n, p)\) onde n é o número de trials e p é a probabilidade que queremos estimar, que representa a probabilidade de sucesso para cada trial. Como estamos estimando uma proporção p, a distribuição natural como prior para este tipo de quantidade é a distribuição \(\text{Beta}(\alpha, \beta)\), como não sabemos muito sobre a prevalência, utilizei um prior não-informativo \(\text{Beta}(1.0, 1.0)\). No fim o modelo é este:
$$
\begin{eqnarray}
\text{p} &\sim & \text{Beta}(\mathit{alpha}=1.0,~\mathit{beta}=1.0)\\\text{y_obs} &\sim & \text{Binomial}(\mathit{n}=4189,~\mathit{p}=\text{p})
\end{eqnarray}
$$
O resultado da estimativa deste parâmetro de prevalência resultou na seguinte distribuição:
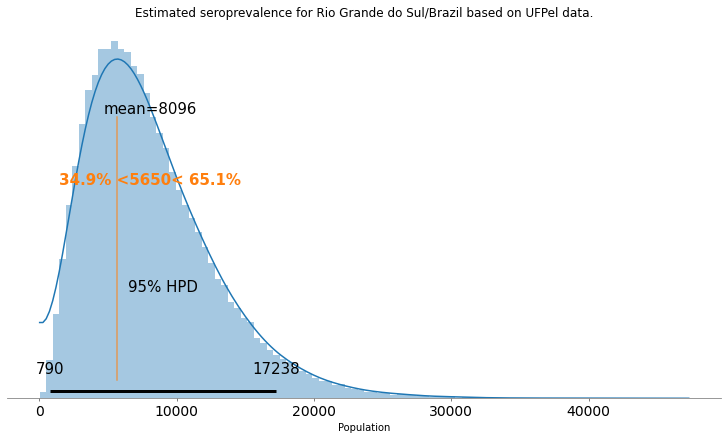
Adicionei neste plot o valor que a UFPel divulgou, que é o 5650. Mas como podemos ver, com um intervalo de credibilidade de 95% este valor na realidade vai de 790 até 17238 infectados. Como podemos ver, um valor muito diferente do que a UFPel divulgou e tem um erro grande associado devido ao tamanho da amostra. Mas este ainda não é o pior dos problemas, porque nesta estimativa estamos assumindo um teste perfeito que nunca erra, o que sabemos não representar a realidade, portanto devemos incluir nesta modelagem as características de sensibilidade e especificidade dos testes utilizados.
Incorporando incerteza dos testes
A UFPel utilizou testes da Wondfo, que foram validados pela própria UFPel e por outros institutos [1]. No seguinte slide, a UFPel mostra alguns resultados destas validações:

Onde comentaram que o teste tem “ótimas características de validade” e que foi validado também por eles mesmos (mas não apresentaram como isto foi feito e nem a quantidade de amostras utilizada para esta validação). Estes testes são distribuídos no Brasil pela empresa Celer Biotecnologia, mas nas especificações brasileiras, a tabela do estudo feito pelo fabricante relacionada ao sangue capilar foi removido. Segue uma thread interessante do Ricardo Parolin:
Esse é o teste da Wondfo, distribuído no Brasil pela Celer Biotecnologia. A parte “esquecida” refere a testes com amostras de sangue capilar, e mostra um número muito menor de amostras analisadas. E 2 falsos-positivos em 172 amostras, e apenas 42 amostras positivas testadas. pic.twitter.com/7MurHJZUjC
— Ricardo Parolin Schnekenberg MD (@parolin_ricardo) April 29, 2020
Como é muito difícil encontrar os dados dos estudos realizados no Brasil (INCQS e outro pela UFPel), vou utilizar os dados do estudo do fabricante pois podemos saber o tamanho da amostra que eles utilizaram para podermos propagar a incerteza do estudo no estudo da UFPel. É importante ressaltar que os dados dos fabricantes geralmente são extremamente otimistas em relação ao que acontece na realidade, pois eles são feitos em condições ideais de testagem, o que muitas vezes não se reflete em campo, mas como são os dados que temos, é o que vou utilizar.
Para definir os priors de sensibilidade e especificidade, utilizei a distribuição \(\text{Beta}(\alpha, \beta)\) por naturalmente modelar proporções e representar a incerteza dependendo da quantidade de amostras que foram utilizas. Abaixo segue o prior definido para a sensibilidade (sensitivity) utilizando os dados do fabricante de 42 amostras positivas e onde as 42 foram corretamente detectadas como positivos (true positives):

É interessante visualizarmos como este prior seria se o fabricante tivesse utilizado apenas 5 amostras por exemplo:
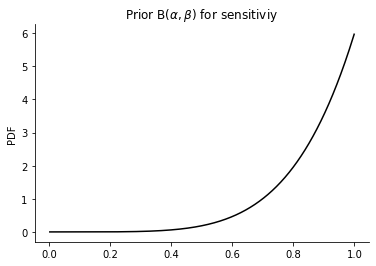
O que isto quer dizer é que na modelagem, independente se a deteção de verdadeiros positivos seja sempre correta, ao utilizar menos amostras a incerteza nestes dados aumenta porque temos maior incerteza com menos amostras do que se tivéssemos mais amostras, este é um ponto importante na escolha de um prior para este tipo de proporção.
Utilizei o mesmo prior para os dados de especificidade do fabricante, o qual teve 2 falsos positivos em uma amostra de 172:

Como podemos ver, a incerteza em relação a especificidade do teste é bem menor do que vimos na sensibilidade, por terem utilizado mais amostras (172) neste ensaio. Porém ainda temos uma incerteza associada. Lembrando novamente que estes dados são do próprio fabricante e que são dados otimistas.
Para modelar o problema agora, temos que ter em mente que a prevalência detectada pelo estudo da UFPel é apenas uma prevalência aparente e não a prevalência verdadeira, pois não estamos usando um teste perfeito. Porém sabemos a relação entre sensibilidade/especificidade e a prevalência verdadeira, então podemos utilizar esta relação para estimar a prevalência verdadeira dado a incerteza amostral e também a incerteza dos testes (utilizando dados do estudo do fabricante):
$$
\hat{\pi} = \pi se + (1.0 – \pi) (1.0 – sp)
$$
Onde \(\hat{\pi}\) é a prevalência aparente, \(\pi\) é a prevalência real, \(se\) é a sensibilidade e \(sp\) é a especificidade. No fim o modelo em plate notation ficou assim:
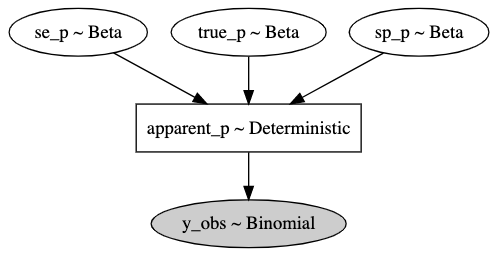
Onde propagamos as incertezas do teste através dos priors, modelamos o prior da prevalência verdadeira com um prior não-informativo e o que estamos observando no fim é o y_obs que é uma distribuição binomial com uma proporção que representa a prevalência aparente. Esta modelagem é muito similar a modelagem apresentada em [2].
Os resultados desta modelagem nos dão a seguinte distribuição:
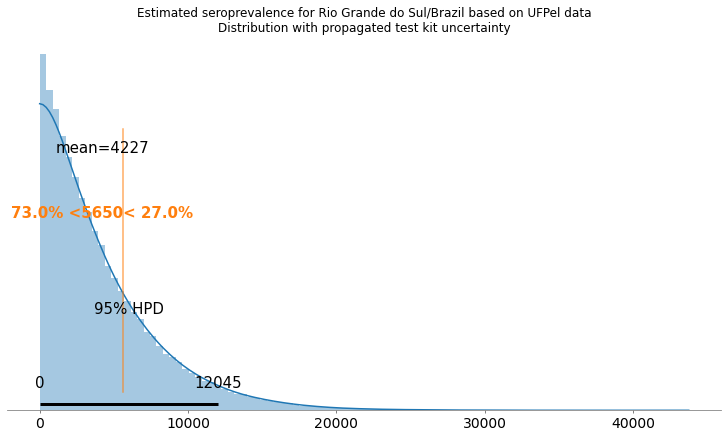
Deixei o valor anunciado pela UFPel como referência em uma linha vertical de cor alaranjada. Como podemos ver, ao incorporar a incerteza dos testes (com os dados otimistas do fabricante), temos um intervalo de 0 (zero) até 12045 infectados no Rio Grande do Sul com um intervalo de credibilidade de 95%. Estes números são bem diferentes dos números anunciados pela UFPel na primeira coletiva, e podemos ver que há uma grande incerteza associada a eles.
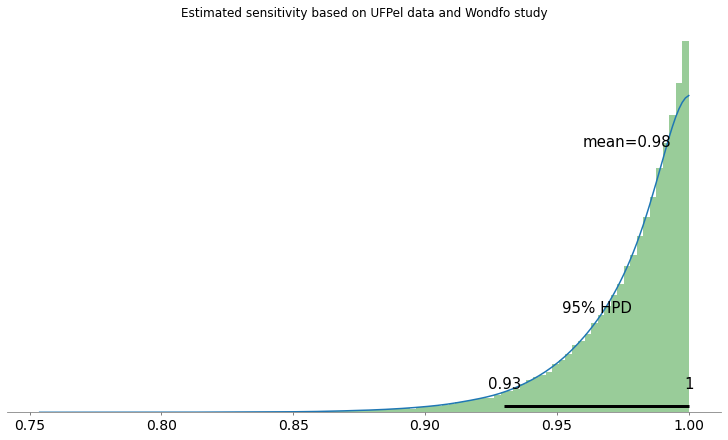
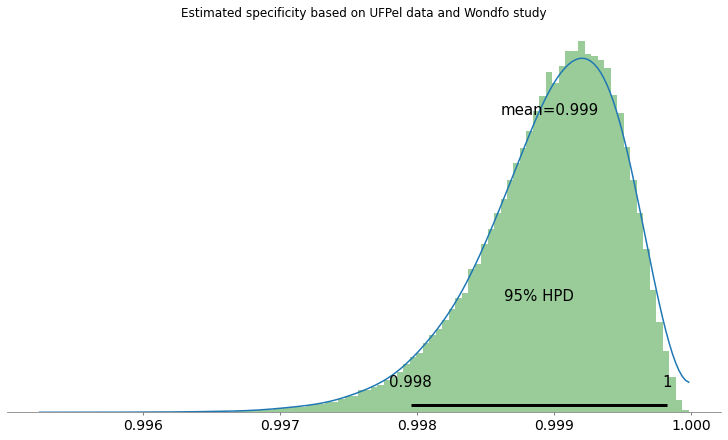
Seguem as distribuições e o intervalo de credibilidade de 95% para sensibilidade e especificidade:
Na segunda fase do estudo, a UFPel divulgou o seguinte resultado:
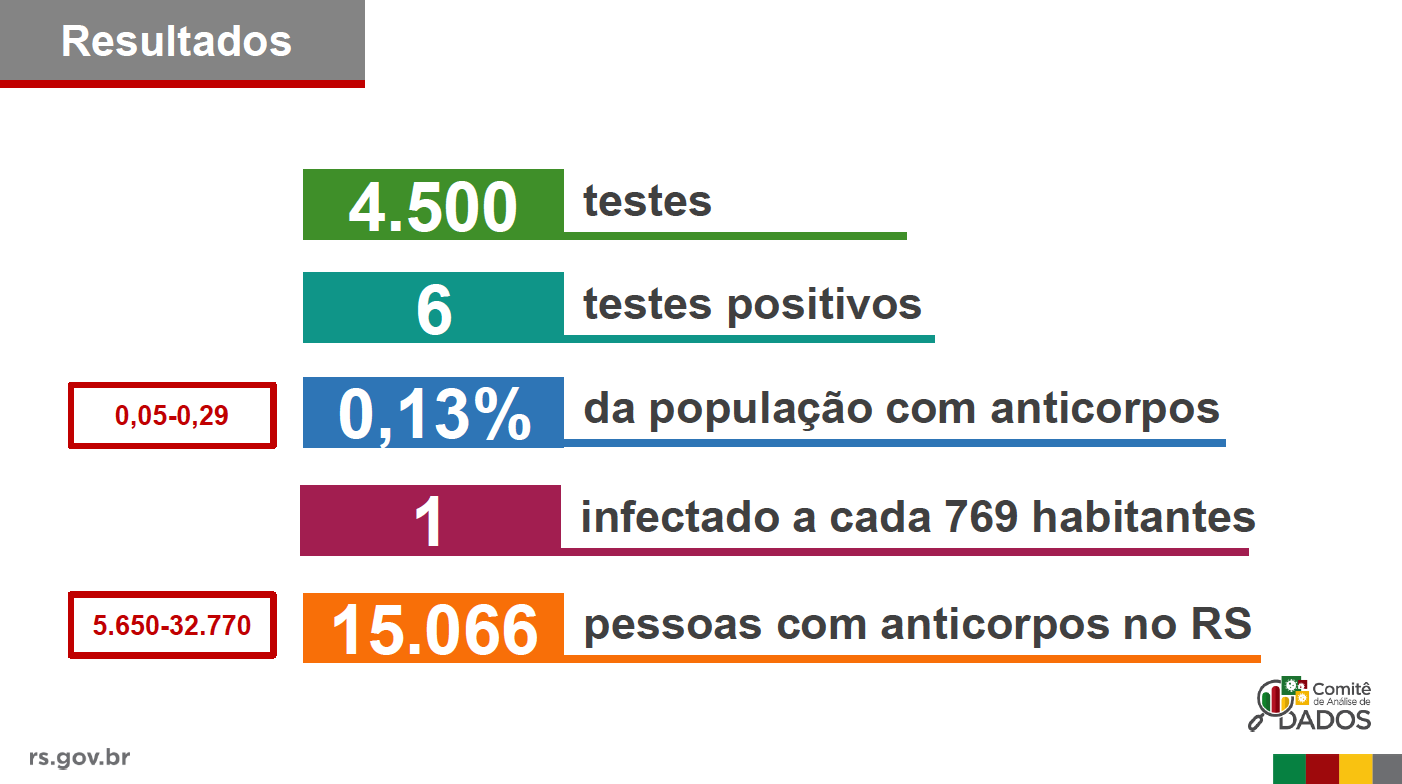
Segue abaixo o resultado com os dados da segunda fase do estudo:
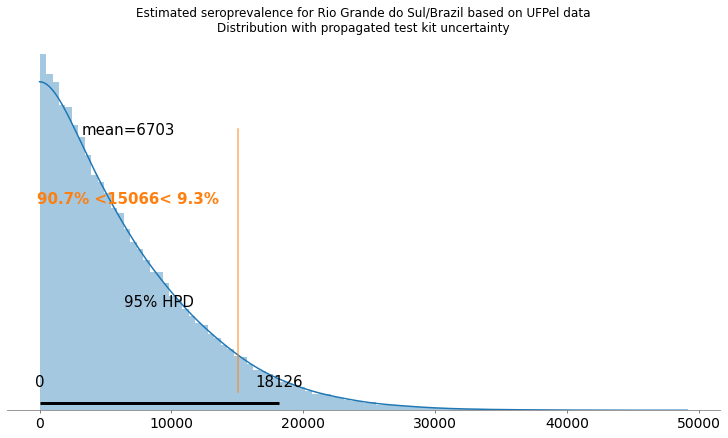
Deixei novamente a linha laranjada representando o resultado divulgado pela UFPel. Como podem ver, este resultado acaba caindo muito longe da maior parte da distribuição estimada. O intervalo mostrado pela UFPel foi de 5650 até 32770, enquanto que o meu intervalo acabou sendo entre 0 (zero) e 18126 com uma credibilidade já alta de 95%.
Óbvio que se pode melhorar o resultado ao incorporar mais hipóteses como por exemplo a quantidade de infectados que já se sabia existir em dado momento no tempo, mas apenas com os dados em mão, é isto o que se pode dizer, algo inconclusivo devido a baixa prevalência encontrada e as propriedades do teste, especialmente a especificidade. E neste caso ainda estou usando os dados otimistas do fabricante que testou o produto em condições ideais. Novamente, isto não significa que você não deva fazer estudos [3], mas sim que deve propagar as incertezas dos erros amostrais e dos kits de teste, e levando também em consideração os erros amostrais.
Outro comentário interessante sobre estes detalhes do estudo da UFPel por Manoel Galdino:
Olha, tem algumas coisas que não batem neste estudo. Segue fio em que explico o que é estranho. Quem sabe algum autor do estudo vê minhas dúvidas e explica. Tl;dr: subnotificação pode ser bem menor que a reportada (3x, em vez de 12x). https://t.co/828M1f1nOI
— Manoel Galdino (@mgaldino) April 30, 2020
Comparação interessante entre RS e Portugal
Uma comparação que eu fiz no dia 12 de Abril, que eu acho muito interessante, é entre o Rio Grande do Sul e Portugal. Ambos tem aproximadamente uma população similar e coincidentemente adotaram medidas de fechamento de escolas, declaração de estado de emergência nas mesmas datas. Porém, o Rio Grande do Sul foi mais rápido ao adotar as medidas em relação ao primeiro caso detectado.
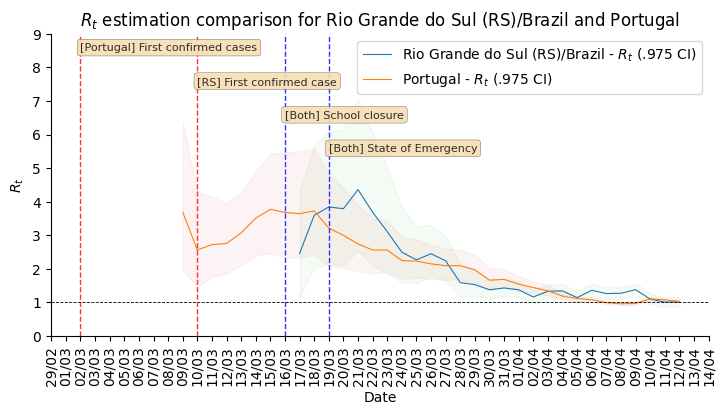
É interessante que o Rio Grande do Sul parece ter atingido um número reprodutivo efetivo menor que Portugal antes de Portugal. Mas, Portugal manteve até hoje (dia 2 de Maio) o estado de emergência e as medidas de intervenção e isolamento. Portugal hoje se encontra com a epidemia controlada, com ocupação de UTIs estável e está aos poucos relaxando o confinamento, entretanto, ninguém sabe se teremos uma nova onda ao relaxar as intervenções como tem acontecido no Rio Grande do Sul na região de Passo Fundo/Marau onde parece estar se tornando um novo epicentro da epidemia no Rio Grande do Sul.
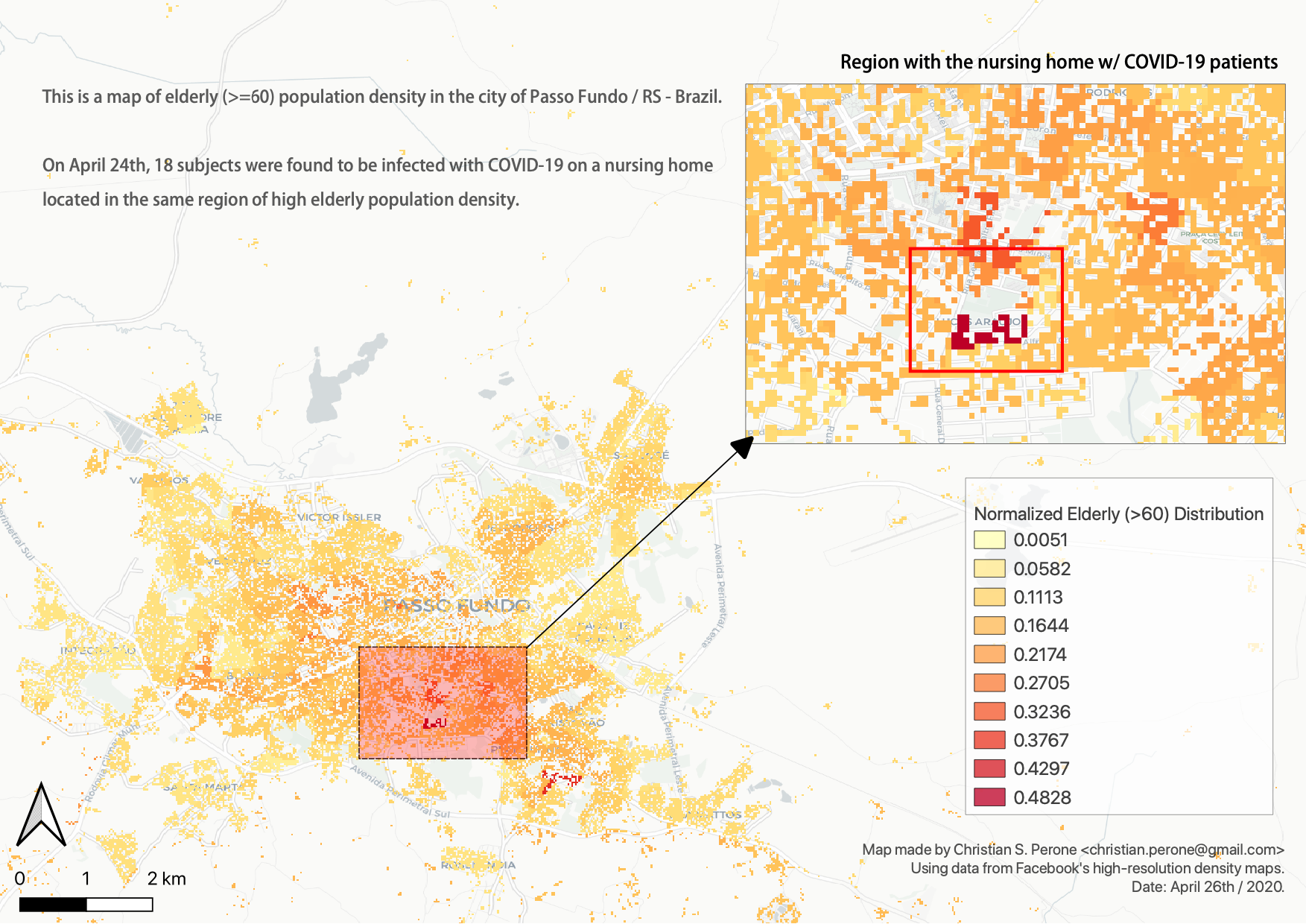
Tenho tentado ressaltar a importância de não só utilizarmos testes em assintomáticos e em estudos randomizados com o da UFPel mas também utilizarmos os testes em regiões com grupos de risco. Fiz este mapa abaixo mostrando a importância da utilização de dados de alta resolução (utilizando imagens de satélite e Machine Learning) para se estimar onde estão os grupos de risco. O mapa abaixo mostra os pontos onde temos a maior densidade de idosos no grupo de risco (acima de 60 anos) em Passo Fundo no Rio Grande do Sul, e em um dos clusters de maior densidade que o mapa mostrou é justamente onde foi encontrado um lar de idosos com 18 infectados.
Este outro mapa abaixo mostra a quantidade de leitos de UTI no RS juntamente com marcadores em vermelho do número de infectados confirmados nas UTIs:
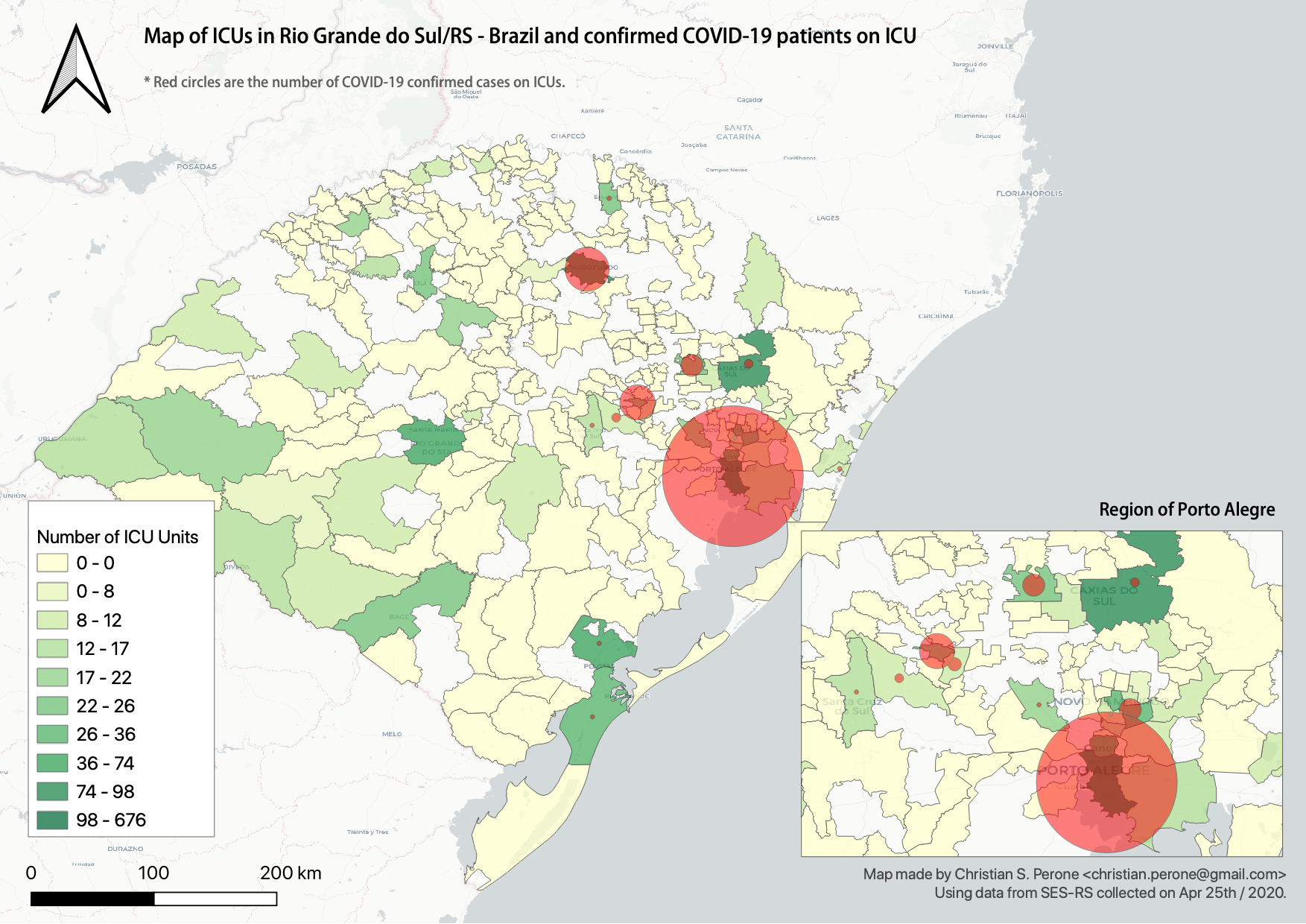
Temos atualmente uma capacidade limitada nas UTIs no Rio Grande do Sul, e não sabemos ainda qual é a defasagem dos testes para podemos estimar em que ponto estamos na curva epidemiológica. Ao relaxar intervenções, podemos correr um alto risco de criarmos uma pressão neste sistema de saúde, especialmente na região de Passo Fundo, que atende várias cidades do interior.
Monitorando a epidemia
Mantenho atualizado diariamente estimativas para o R(t) por estado para todos estados do Brasil. Como já pontuado por inúmeros epidemiologistas, este número é o número que devemos monitorar para auxiliar nas decisões de medidas de intervenção. Ainda dá para melhorar bastante as estimativas ao ajustar pela defasagem dos testes, mas infelizmente as secretarias de saúde não fornecem os dados necessários para que se possa fazer este trabalho.
Segue a última atualização para o estado do Rio Grande do Sul:
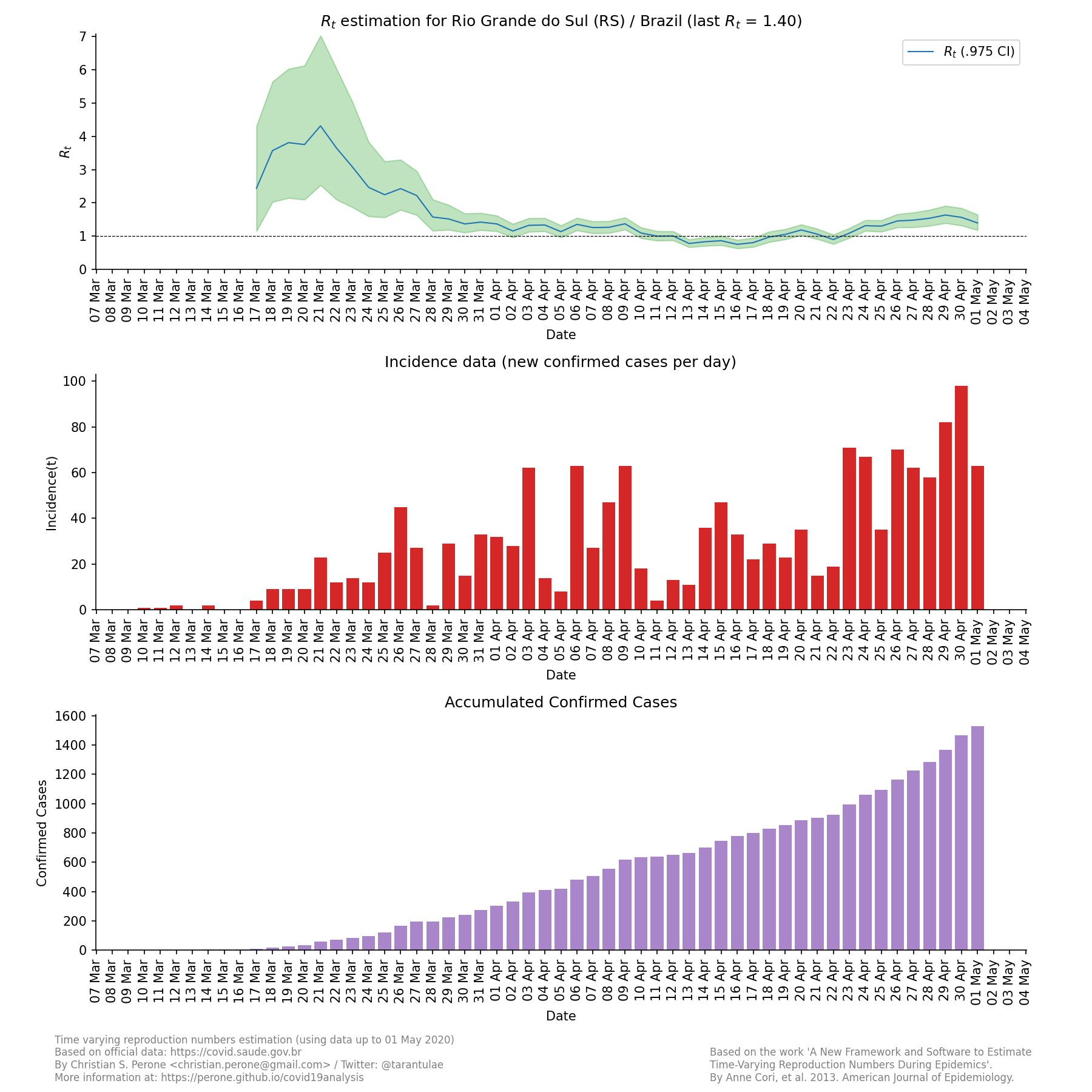
Atualização [13 de Maio 2020]: resultados para terceira fase do estudo
Na terceira fase do estudo que a UFPel liberou, temos os seguintes resultados:

Como podemos ver, dos 10 casos positivos, tivemos 4 deles em Passo Fundo, o que não surpreende muito (veja o que comentei sobre Passo Fundo/RS no dia 29 de Abril acima neste post) dado a alta incidência que há em Passo Fundo desde algumas semanas atrás. Novamente a UFPel só mostrou valores em percentuais sobre a sensibilidade/especificidade do teste e não falou sobre os dados dos 4 estudos diferentes que foram feitos (incluindo o deles), portanto continuamos no escuro em relação à este estudo que eles fizeram sobre os testes, mesmo após a terceira fase do estudo.
De acordo com os resultados da UFPel, teríamos na melhor estimativa deles, 24.860 pessoas com anticorpos no RS. Porém, ao incorporar a incerteza dos testes como comentado anteriormente, temos os seguintes resultados:
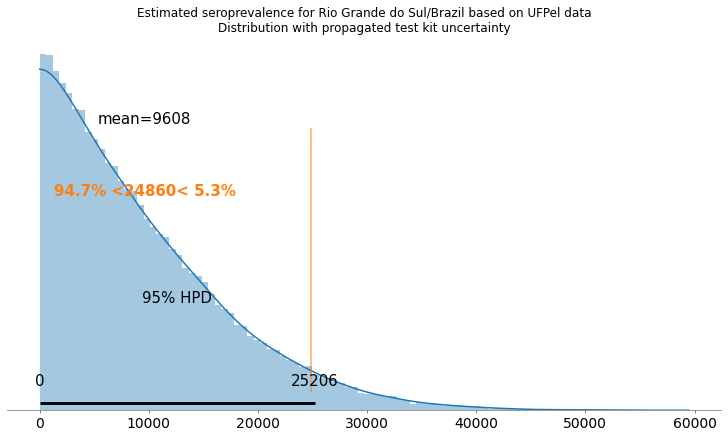
A marca laranjada é onde está a melhor estimativa da UFPel, e a média para o meu resultado é 9.608, muito abaixo do resultado da UFPel. De fato, o resultado da UFPel está já muito próximo do intervalo de credibilidade de 95% deste modelo incorporando a incerteza dos testes.
Temos também as seguintes estimativas de sensibilidade e especificidade:
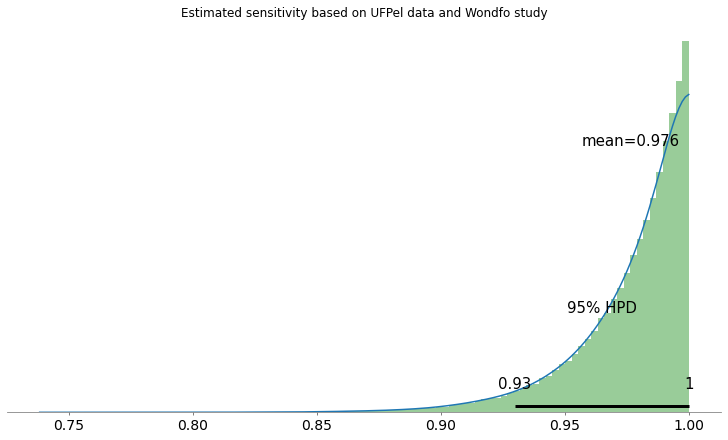
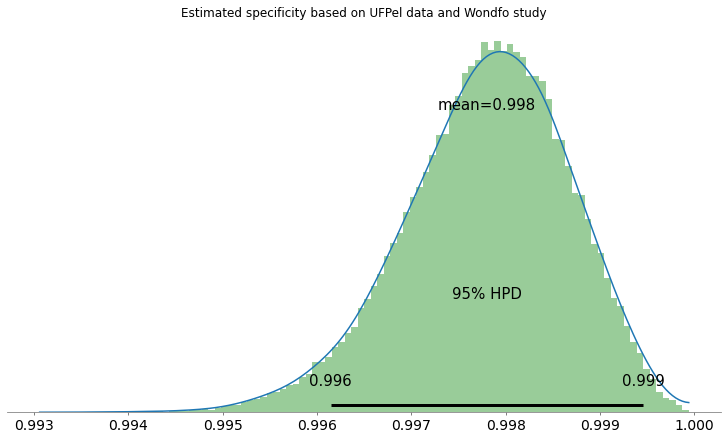
Utilizando as características encontradas por um outro laboratório independente do estudo Test performance evaluation of SARS-CoV-2 serological assays (Jeffrey D. Whitman, et al. 2020), onde há uma sensibilidade bem mais baixa que a especificada pelo fabricante, ainda assim obtemos resultados bem diferentes dos da UFPel:
![]()
Com estes dados do estudo independente, obtemos uma média de pessoas com anti-corpos de 14.894, com 95% de credibilidade em 37.453, ou seja, muito maior do que com os dados do teste do próprio fabricante. O que demonstra como os resultados podem mudar muito ao se utilizar dados de validação de estudos independentes.
Seguem sensibilidade e especificidade estimada com os dados do estudo independente mencionado acima:
![]()
![]()
Atualização [18 de Maio 2020]: resultados de Manaus/Amazonas
Na pesquisa de prevalência em Manaus, foram encontradas 27 amostras positivas do total de 250 amostras feitas. O que mostra uma grande prevalência na cidade de Manaus. A UFPel divulgou um valor estimado de 201.6 mil pessoas com anti-corpos. Seguem os resultados abaixo usando dois cenários, o primeiro usando dados de validação dos testes da própria fabricante (Wondfo) e o segundo utilizando os dados de validação independente do COVID-19 Testing Project [1].
Cenário com validação do COVID-19 Testing Project
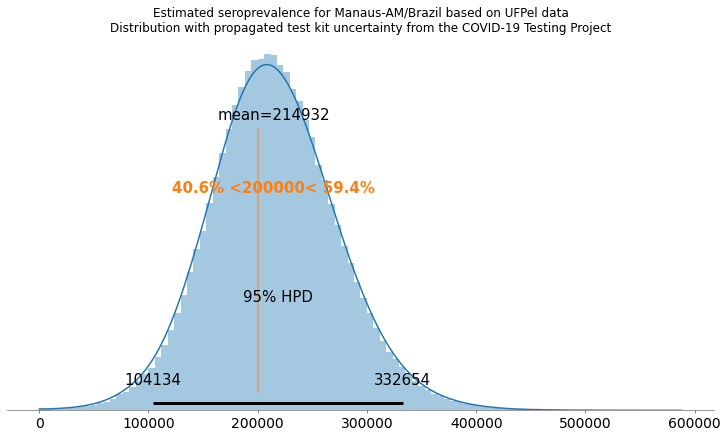
Neste cenário, podemos ver que com uma prevalência mais alta, os resultados começam a bater com os resultados da UFPel, mas com credibilidade muito maiores. Na minha estimativa a média foi 214.932 pessoas com anticorpos (a UFPel anunciou 201.6 mil), e a credibilidade de 95% vai de 104.134 até 332.654, a UFPel anunciou uma margem de 180 mil até 220 mil.
Cenário com validação da própria fabricante
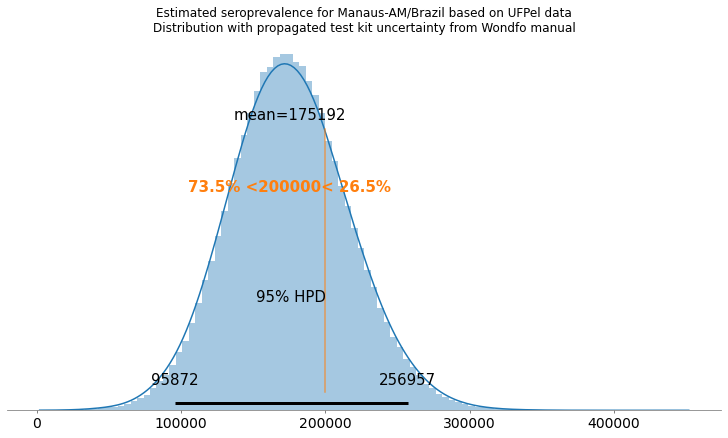
Como podemos ver, com os dados de validação da própria fabricante, os resultados acabam ficando mais otimistas para Manaus.
Comentários
Viu algo errado neste artigo ? Entre em contato e critique ! É através da crítica que juntos crescemos e lutamos contra esta epidemia.
Referências
[1] COVID-19 Testing Project. 2020.
[2] Estimating SARS-CoV-2 seroprevalence and epidemiological parameters with uncertainty from serological surveys. Daniel B Larremore et al. 2020.
[3] Concerns with that Stanford study of coronavirus prevalence. Andrew Gelman. 2020.
– Christian S. Perone
Caro Christian, Como presidente da Procempa eu agradeço a tua grande contribuição ao nosso trabalho alertando para grave vulnerabilidade de segurança de dados. Seu alerta, além de impedir a propagação do problema pela correção do código, está ensejando a revisão e melhorias no processo de desenvolvimento e testes de software para reduzir os riscos desse tipo de problema no futuro. Um abraço, Paulo Miranda.
Olá Paulo ! Muito obrigado pelo retorno, fico feliz de saber que a Procempa está fazendo um ótimo trabalho nesta época difícil que estamos passando. Um forte abraço !
Oi, Christian!
Já sabes da minha admiração pelo teu trabalho, mas mais uma vez parabéns!
Orientando pacientes sobre testes de antígeno, percebi mais uma fonte de incerteza possivelmente importante. A grande maioria desses testes são validados considerando RT-qPCR de swab nasofaríngeo como referência. A referência, no entanto, também tem performance incerta, algo obviamente ignorado pelos fabricantes (https://www.thelancet.com/journals/lancet/article/PIIS0140-6736(20)32635-0/fulltext). Parece ser maior em pacientes hospitalizados, mas difícil dizer em pacientes asintomáticos, por exemplo. Minha dúvida é sobre a possibilidade de decompor se_p em
se_p = P(Teste Rápido + | Doença) = P(Teste Rápido + | PCR +) * P( PCR + | Doença )
O que se aplica a qualquer teste validado com referência de performance incerta (a.k.a. todas?), porém cheira a “nonidentifiability”. No mínimo, o tamanho amostral para validar um teste tendo RT-qPCR como referência deveria ser bem maior.
Muito obrigado,
Giuliano
Daee ! Valeu pelo comentário ! Acho que daria para incluir esta incerteza sim, o problema é que o PCR acaba sendo o único gold standard que temos, sem contar esse bias potencial grande de que a calibração é feita com pacientes com carga viral muito grande (hospitalizados geralmente). No fim das contas acho que pode acabar aumentando tanto a incerteza como em (https://rss.onlinelibrary.wiley.com/doi/abs/10.1111/rssc.12435).